

深度学习之损失函数小结
在深度学习中,损失函数扮演着至关重要的角色。通过对最小化损失函数,使模型达到收敛状态,减少模型预测值的误差。因此,不同的损失函数,对模型的影响是重大的。接下来,总结一下,在工作中经常用到的损失函数:
- 图像分类:交叉熵
- 目标检测:Focal loss,L1/L2损失函数,IOU Loss,GIOU ,DIOU,CIOU
- 图像识别:Triplet Loss,Center Loss,Sphereface,Cosface,Arcface
图像分类
交叉熵
在图像分类中,经常使用softmax+交叉熵作为损失函数,具体的推导可以参考我以前的博客。
$$Cross Entropy=-\sum_{i=1}^{n}p(x_i)ln(q(x_i))$$
其中,$p(x)$表示真实概率分布,$q(x)$表示预测概率分布。交叉熵损失函数通过缩小两个概率分布的差异,来使预测概率分布尽可能达到真实概率分布。
后来,谷歌在交叉熵的基础上,提出了label smoothing(标签平滑),具体介绍,可以参考这篇博客。
在实际中,需要用预测概率去拟合真实概率,而拟合one-hot的真实概率函数会带来两个问题:
- 无法保证模型的泛化能力,容易造成过拟合;
- 全概率和0概率鼓励所属类别和其他类别之间的差距尽可能加大,而由梯度有界可知,这种情况很难adapt,会造成模型过于相信预测的类别。
因此,为了减少这种过于自信,同时减缓人为标注的误差带来的影响,需要对$p(x)$进行变化:
$$p'{(x)}=(1-\epsilon )\delta _{(k,y)}+\epsilon u(k)$$
其中,$\delta _{(k,y)}$为Dirac函数,$u(k)$为均匀分布。简单而言,降低标签y的置信度,提高其余类别的置信度。从而,交叉熵变成了:
$$H(p',q)=-\sum_{i=1}^{n}p'(x_i)ln(q(x_i))=(1-\epsilon )H(p,q)+\epsilon H(p,u)$$
目标检测
最近,看到一篇很好的博文,是介绍目标检测中的损失函数的,可以参考一下:https://mp.weixin.qq.com/s/ZbryNlV3EnODofKs2d01RA
在目标检测中,损失函数一般由两部分组成,classification loss和bounding box regression loss。calssification loss的目的是使类别分类尽可能正确;bounding box regression loss的目的是使预测框尽可能与GT框匹对上。
Focal loss
该Focal loss损失函数出自于论文《Focal Loss for Dense Object Detection》,主要是解决正负样本之间的不平衡问题。通过降低easy example中的损失值,间接提高了hard example中损失值的权重。Focal loss是基于交叉熵进行改进的:
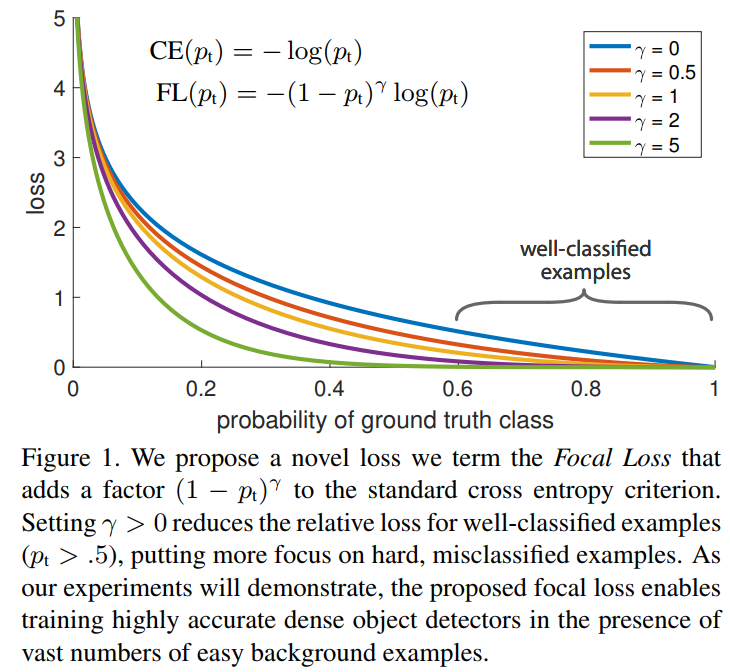
$$Focal loss=-\alpha _t(1-p_t)^\gamma log(p_t)$$
可以看到,在交叉熵前增加了$(1-p_t)^\gamma $,当图片被错分时,$p_t$会很小,$(1-p_t)$接近于1,所以损失受到的影响不大;而增加参数$\gamma $是为了平滑降低esay example的权重。当$\gamma =0$时,Focal loss退化成交叉熵。对于不同的$\gamma $,其影响如下图所示。
L1,L2,smooth L1损失函数
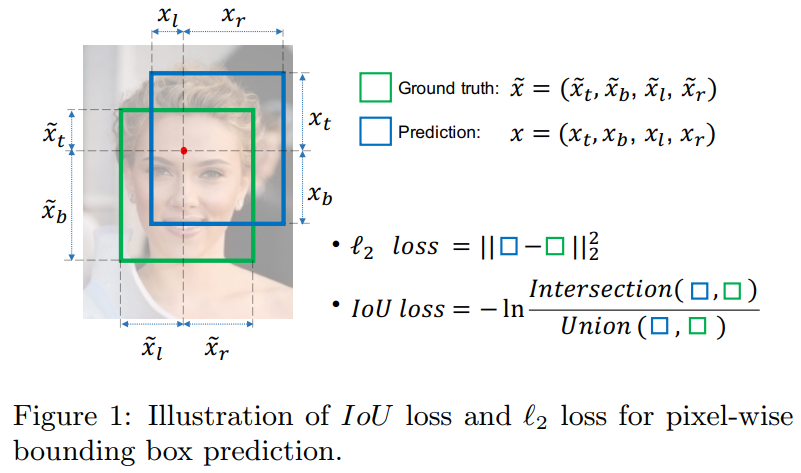
利用L1,L2或者smooth L1损失函数,来对4个坐标值进行回归。smooth L1损失函数是在Fast R-CNN中提出的。三个损失函数,如下所示:
$$L1=\left | x \right |$$
$$L2=x^{2}$$
$$smoothL1=\left\{\begin{matrix} 0.5x^2\qquad if\left |x \right |<1\\ \left |x \right |-0.5 \qquad otherwise \end{matrix}\right.$$
从损失函数对x的导数可知:$L1$损失函数对x的导数为常数,在训练后期,x很小时,如果learning rate 不变,损失函数会在稳定值附近波动,很难收敛到更高的精度。$L2$损失函数对x的导数在x值很大时,其导数也非常大,在训练初期不稳定。smooth L1完美的避开了$L1$和$L2$损失的缺点。
在一般的目标检测中,通常是计算4个坐标值与GT框之间的差异,然后将这4个loss进行相加,构成regression loss。
但使用上述的3个损失函数,会存在以下的不足:
- 上面的三种Loss用于计算目标检测的Bounding Box Loss时,独立的求出4个点的Loss,然后进行相加得到最终的Bounding Box Loss,这种做法的假设是4个点是相互独立的,实际是有一定相关性的;
- 实际评价框检测的指标是使用IOU,这两者是不等价的,多个检测框可能有相同大小的Loss,但IOU可能差异很大,为了解决这个问题就引入了IOU LOSS
IOU Loss
该IOU Loss是旷视在2016年提出的《UnitBox: An Advanced Object Detection Network》。该论文的主要观点之一是:
- 使用基于欧式距离的L-n损失函数,其前提是假设4个坐标变量都是独立的,但实际上,这些坐标变量是具有一定的关联性。
- 评价指标使用了IOU,而回归坐标框又使用4个坐标变量,这两者是不等价的。
- 具有相同的欧式距离的框,其IOU值却不是唯一的。
所以,提出了IOU loss,直接使用IOU作为损失函数:
$$Loss_{IOU}=-ln(IOU)$$
同时,也会有人使用的是:
$$Loss_{IOU}=1-IOU$$
GIOU
该GIOU Loss损失函数是斯坦福于2019年提出的《Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression》。在上面的IOU Loss中,无法对两个不重叠的框进行优化,而且IOU Loss无法反映出两个框到底距离有多远。为了解决这个问题,作者提了GIOU来作为损失函数:
$$GIOU=IOU-\frac{C-(A\bigcup B)}{C}$$
其中,$C$表示两个框的最小外接矩阵面积。即先求出两个框的IOU,然后求出外接矩阵C的面积,减去A与B的面积。最终得到GIOU的值。

GIOU具有以下的性质:
- GIOU可以作为一种衡量距离的方式,$Loss_{GIOU}=1-GIOU$
- GIOU具有尺度不变性
- GIOU是IOU的下限,$GIOU(A,B)\leq IOU(A,B)$。当矩形框A、B类似时,$\lim_{A\rightarrow B}GIOU(A,B)=IOU(A,B)$
- 当矩形框A、B重叠时,$GIOU(A,B)=IOU(A,B)$
- 当矩形框A、B不相交时,$GIOU(A,B)=-1$
总的来说,GIOU包含了IOU所有的优点,同时克服了IOU的不足。
DIOU和CIOU
DIOU和CIOU是天津大学于2019年提出的《Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression》。为了解决GIOU收敛慢和提高回归精度,提出DIOU来加速收敛。同时考虑到框回归的3个几何因素(重叠区域,中心点距离,宽高比),基于DIOU,再次提出CIOU,进一步提高收敛速度和回归精度。另外,可以将DIOU结合NMS组成DIOU-NMS,来对预测框进行后处理。
当出现下图的情况(GT框完全包含预测框)时,IOU与GIOU的值相同,此时GIOU会退化成IOU,无法区分其相对位置关系。同时由于严重依赖于IOU项,GIOU会致使收敛慢。

基于上述问题,作者提出两个问题
- 直接最小化预测框与目标框之间的归一化距离是否可行,以达到更快的收敛速度。
- 如何使回归在与目标框有重叠甚至包含时更准确、更快
好的目标框回归损失应该考虑三个重要的几何因素:重叠面积,中心点距离,长宽比。基于问题一,作者提出了DIoU Loss,相对于GIoU Loss收敛速度更快,该Loss考虑了重叠面积和中心点距离,但没有考虑到长宽比;针对问题二,作者提出了CIoU Loss,其收敛的精度更高,以上三个因素都考虑到了。
首先,定义一下基于IOU Loss的损失函数:
$$Loss=1-IOU+R(B,B^{gt})$$
其中,$R(B,B^{gt})$表示预测框与GT框的惩罚项。在IOU Loss中,$R(B,B^{gt})=0$;在GIOU中,$R(B,B^{gt})=\frac{C-A\bigcup B}{C}$。
而在DIOU中,该惩罚项$R(B,B^{GT})=\frac{\rho ^2(b,b^{gt})}{c^2}$,其中$b$和$b^{gt}$表示预测框与GT框的中心点,$\rho ()$表示欧式距离,$c$表示预测框$B$与GT框$B^{gt}$的最小外接矩阵的对角线距离,如下图所示。
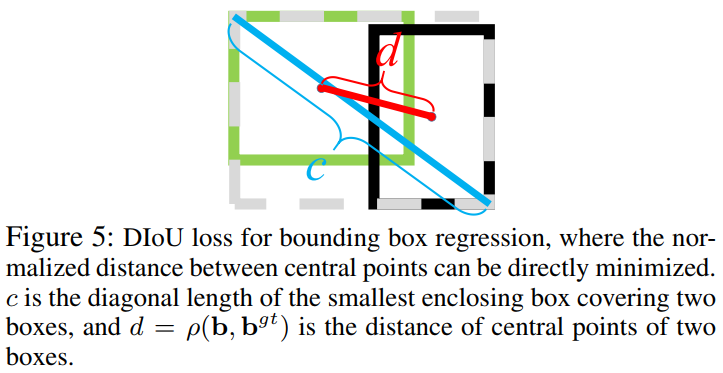
因此,$Loss_{DIOU}$定义为:
$$Loss_{GIOU}=1-IOU+\frac{\rho ^2(b,b^{gt})}{c^2}$$
所以,$Loss_{DIOU}$具有如下性质:
- DIOU依然具有尺度不变性;
- DIOU直接最小化两个框的距离,因此收敛会更快;
- 对于目标框包裹预测框的这种情况,DIoU Loss可以收敛的很快,而GIoU Loss此时退化为IoU Loss收敛速度较慢
DIOU同时考虑了重叠面积和中心点之间的距离,但是没有考虑到宽高比。进一步提出了CIOU,同时考虑了这3个因素,在DIOU的惩罚项中加入了$\alpha \upsilon $:
$$R(B,B^{gt})=R_{CIOU}=\frac{\rho ^2(b,b^{gt})}{c^2}+\alpha \upsilon $$
其中,$\alpha $表示trade-off参数,$\upsilon $表示宽高比一致性参数。
$$\upsilon =\frac{4}{\pi ^2}\left ( arctan\frac{w^{gt}}{h^{gt}}-arctan\frac{w}{h} \right )^2$$
$$\alpha =\frac{\upsilon }{(1-IOU)+\upsilon }$$
这里的$\upsilon $为什么会有$\frac{4}{\pi ^2}$呢?这里$arctan$的范围是$[0,\frac{\pi }{2})$。
所以,CIOU的损失函数为:
$$Loss_{CIOU}=1-IOU+\frac{\rho ^2(b,b^{gt})}{c^2}+\alpha \upsilon $$
而在实际操作中,$w^2+h^2$是很小的数字,在后向传播时,容易造成梯度爆炸。通常用1来代替$w^2+h^2$。
另外,提醒一点的是,GIOU、CIOU、DIOU都是衡量方式,在使用时可以代替IOU。但是这里需要考虑的一个问题是,预测框与GT框的匹配规则问题。并不是说anchor一定会去匹配一个不重叠的GT框。类似于SSD中所说,anchor会选择一个重叠最大的GT框进行预测,而这个重叠最大可以使用IOU、GIOU、CIOU、DIOU来进行衡量。
图像识别
图像识别问题,包含了行人重识别,人脸识别等问题。此类损失都是通用的,因此放在一起汇总。同样,也看到一篇很好的博客介绍了大量人脸识别的损失函数:https://mp.weixin.qq.com/s/wJ-JNsUv60vXtGIV-mDrTA
Triplet Loss
该Triplet Loss损失函数提出于2015年的《FaceNet: A Unified Embedding for Face Recognition and Clustering》。该损失函数的主要想法是,拉近同一id之间的距离,扩大不同id之间的距离。如下图所示,图中的anchor与positive属于同一id,即$y_{anchor}=y_{positive}$;而anchor与negative属于不同的id,即$y_{anchor} \ne y_{negative}$。通过不断学习后,使得anchor与positive的欧式距离变小,anchor与negative的欧式距离变大。其中,这里的anchor、Positive、negative是图片的d维嵌入向量(embedding)。

使用数学公式进行表达,triplet loss想达到的效果是:
$$d(x^a_i,x^p_i)+\alpha \leq d(x^a_i,x^n_i)$$
其中,$d()$表示两个向量之间的欧氏距离,$\alpha $表示两个向量之间的margin,防止$d(x^a_i,x^p_i)=d(x^a_i,x^n_i)=0$。因此,可以最小化triplet loss损失函数来达到此目的:
$$triplet\quad loss=[d(x^a_i,x^p_i)-d(x^a_i,x^n_i)+\alpha ]_+$$
在实际中,通常使用在线训练方式,选择P的不同的id,每个id包含K张图片,形成了$batch_size=PK$的mini-batch。从而在这mini-batch种选择hard/easy example构成loss,具体可以参考这篇博客。
Center Loss
该Center Loss损失函数提出于《A Discriminative Feature Learning Approach for Deep Face Recognition》。为了提高特征的区分能力,作者提出了center loss损失函数,不仅能缩小类内差异,而且能扩大类间差异。
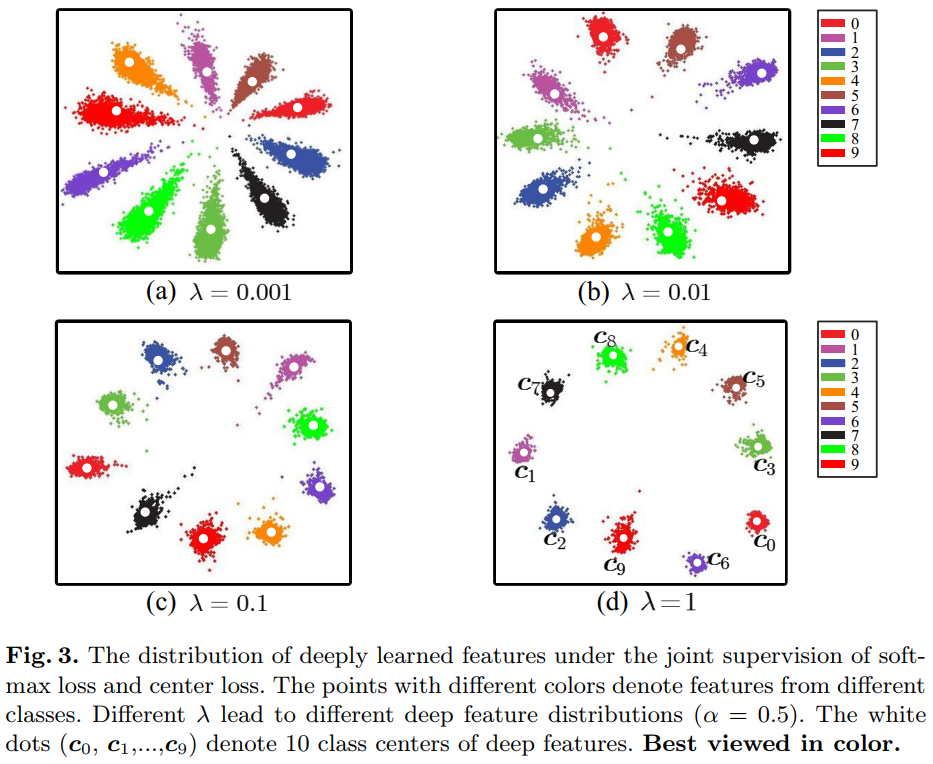
作者首先在MNIST数据集上进行试验,将隐藏层的最后输出维度改为2,使用softmax+交叉熵作为损失函数,将其结果可视化出来,如下图所示。可以看出,交叉熵可以使每一类分开,数据分布呈射线形,但却不够区分性,即类内差异大。

因此,作者想要在保持数据的可分性前提下,进一步缩小类内之间的差异。为了达到这个目的,提出了center loss损失函数:
$$L_C=\frac{1}{2}\sum_{i=1}^{m}\left \| x_i-c_{y_i} \right \|^2_2$$
其中,$c_{y_i}$表示第$y_i$类的中心。因此,通常将center loss和交叉熵进行结合,构成组合损失函数:
$$L=L_S+\lambda L_C=-\sum_{i=1}^{m}log\frac{e^{W^T_{y_i}x_i+b_{y_i}}}{\sum_{j=1}^{n}e^{W^T_j x_j+b_{y_i}}}+\frac{\lambda }{2}\sum_{i=1}^{m}\left \| x_i-c_{y_i} \right \|^2_2$$
其中,$\lambda $表示center loss的惩罚力度。同样在MNIST中,其结果如下图所示。可以看到随着$\lambda $的增加,约束性更强,每一类会更聚集在类内中心处。
在使用Center Loss损失函数时,需要引入两个超参:$\alpha $和$\lambda $。其中,$\lambda $表示center loss的惩罚力度;而$\alpha $控制类内中心点$c_{y_i}$的学习率。类内中心点$c_{y_i}$应该随着特征的不同,会产生变化。一般会在每个mini-batch中更新类内中心点$c_{y_i}$:
$$c^{t+1}_j=c^t_j-\alpha \Delta c^t_j$$
Sphereface
该Sphereface提出于《SphereFace: Deep Hypersphere Embedding for Face Recognition》,其也称A-Softmax损失函数。作者认为,triplet loss需要精心构建三元组,不够灵活;center loss损失函数只是强调了类内的聚合度,对类间的可分性不够重视。因此,作者提出了疑问:基于欧式距离的损失函数是否适合模型学习到具有区分性的特征呢?
首先,重新看一下softmax loss损失函数(即softmax+交叉熵):
$$Loss_i=-log\left ( \frac{e^{W^T_{y_i}x_i+b_{y_i}}}{\sum_{j}e^{W^T_jx_i+b_j}} \right )=-log\left (\frac{e^{||W_{y_i}|| \; ||x_i||cos(\theta _{y_i,i})+b_{y_i}}}{\sum_je^{||W_j|| \; ||x_i||cos(\theta _{j,i})+b_j}} \right )$$
其中,$\theta _{j,i} \quad (0 \leq \theta _{j,i}\leq \pi )$表示向量$W_j$和$x_i$的夹角。可以看到,损失函数与$||Wj||$,$\theta _{j,i}$和$b_j$有关,令$||Wj||=1$和$b_j=0$,则可以得到modified-softmax损失函数,更加关注角度信息:
$$L_{modified-softmax}=-log\left (\frac{e^{||x_i||cos(\theta _{y_i,i})}}{\sum_je^{||x_i||cos(\theta _{j,i})}} \right )$$
虽然使用modified-softmax损失函数可以学习到特征具有角度区分性,但这个区分力度仍然不够大。因此,在$\theta _{j,i}$上乘以一个大于1的整数,来提高区分度:
$$L_{ang}=-log\left (\frac{e^{||x_i||cos(m\theta _{y_i,i})}}{e^{||x_i||cos(m\theta _{j,i})}+\sum_{j\neq y_i}e^{||x_i||cos(\theta _{j,i})}} \right )$$
这样,能扩大类间距离,缩小类内距离。
下图是论文的实验结果,从超球面的角度进行解释,不同的m值的结果。其中,不同颜色的点表示不同的类别。可以看出,使用A-Softmax损失函数,会将学习到的向量特征映射到超球面上,$m=1$表示退化成modified-softmax损失函数,可以看出,每个类别虽然有明显的分布,但区分性不够明显。随着$m$的增大,区分性会越来越大,但也越来越难训练。

最后,给出该损失函数的实现方式,请参考这篇博客。
Cosface
该Cosface损失函数是由腾讯在2018年《CosFace: Large Margin Cosine Loss for Deep Face Recognition》中提出的。Cosface损失函数,也称Large Margin Cosine Loss(LMCL)。从名字可以看出,通过对cos的间隔最大化,来实现扩大类间距离,缩小类内距离。
从softmax出发(与Sphereface类似),作者发现,为了实现有效的特征学习,$||W_j=1||$是十分有必要的,即对权重进行归一化。同时,在测试阶段,测试用的人脸对的得分通常是根据两个特征向量之间的余弦相似度进行计算的。这表明,$||x||$对得分计算影响不大,因此,在训练阶段将$||x||=s$固定下来(在本论文中,$s=64$):
$$L_{ns}=\frac{1}{N}\sum_{i}-log\frac{e^{s \; cos(\theta _{y_i,i})}}{\sum_{j}e^{s \; cos(\theta _{j,i})}}$$
其中ns表示归一化版本的softmax loss,$\theta _{j,i}$表示$W_j$和$x$之间的角度。为了加大区分性,类似Sphereface一样,引入常数m:
$$L_{lmc}=\frac{1}{N}\sum_{i}-log\frac{e^{s \; (cos(\theta _{y_i,i})-m)}}{e^{s \; (cos(\theta _{y_i,i})-m)}+\sum_{j\neq y_i}e^{s \; cos(\theta _{j,i})}}$$
其中,$W=\frac{W^*}{||W^*||},x=\frac{x^*}{||x^*||},cos(\theta _j,i)=W^T_jx_i$。
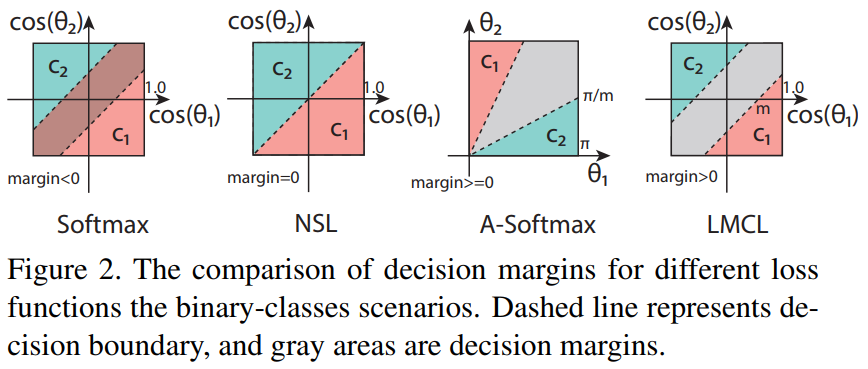
下图是作者的解释图。第一个表示正常的sotfmax loss,可以看出两个类别的分类边界具有重叠性,即区分性不强;第二个表示归一化版本的softmax loss,此时边界已经很明显,相互没有重叠,但是区分性不足;第三个表示A-softmax,此时横纵坐标变成了$\theta $,从这个角度解释,使用两条线作为区分边界,作者也提出,该损失函数的缺点是不连续;第四个表示Cosface,在$cos(\theta )$下,使用两条线作为区分边界,特征之间没有交集,随着m值增大,区分性也会越来越明显,但训练难度会加大。
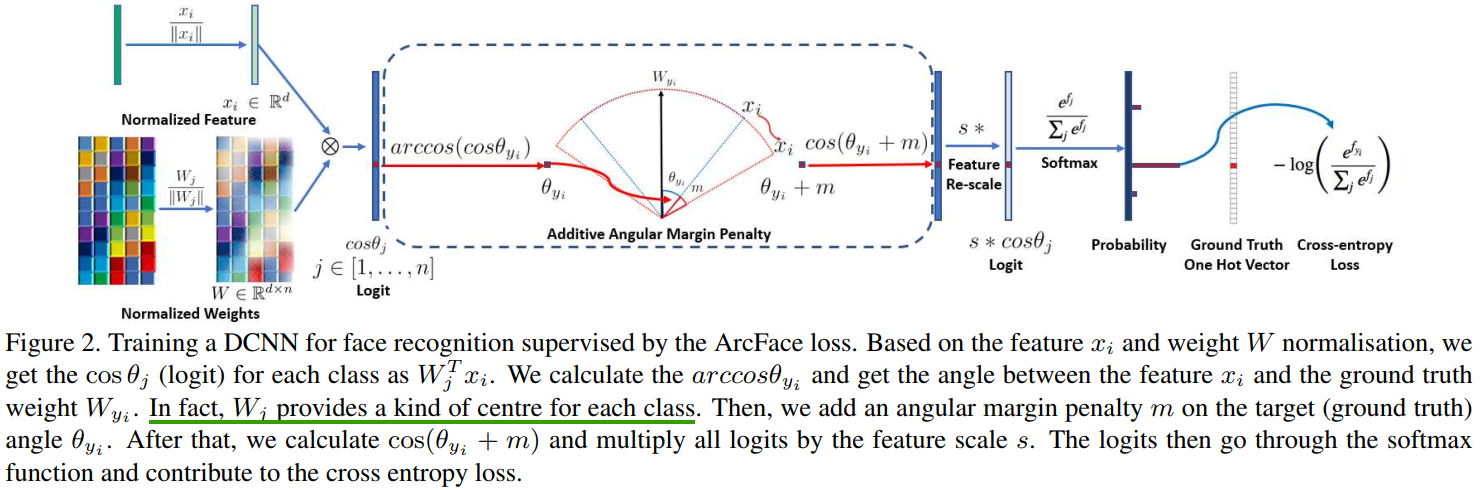
Arcface
该Arcface损失函数提出于《ArcFace: Additive Angular Margin Loss for Deep Face Recognition》。类似于Sphereface和Cosface,Arcface同样需要令$||W||=1,||x||=s$,同时也引入常数m,但与前面两者不同的是,这里的m是对$\theta $进行修改:
$$L_{arcface}=\frac{1}{N}\sum_{i}-log\frac{e^{s \; (cos(\theta _{y_i,i}+m))}}{e^{s \; (cos(\theta _{y_i,i}+m))}+\sum_{j\neq y_i}e^{s \; cos(\theta _{j,i})}}$$
下图是Arcface的计算流程图,首先对$x$与$W$进行标准化,然后进行相乘得到$cos(\theta _{j,i})$,通过$arccos(cos(\theta _{j,i}))$来得到角度$\theta _{j,i}$,加上常数$m$来加大间距得到$\theta _{j,i}+m$,之后计算$cos(\theta _{j,i}+m)$并乘上常数$s$,最后进行常规的softmax loss就行。
通过对Sphereface、Cosface和Arcface进行整合,得到了统一的形式:
$$L=\frac{1}{N}\sum_{i}-log\frac{e^{s \; (cos(m_1\theta _{y_i,i}+m_2)-m_3)}}{e^{s \; (cos(m_1\theta _{y_i,i}+m_2)-m_3)}+\sum_{j\neq y_i}e^{s \; cos(\theta _{j,i})}}$$
此时,就可以对该损失函数进行魔改了,作者实验得到,对于部分数据集,$m_1=1,m_2=0.3,m_3=0.2$和$m_1=0.9,m_2=0.4,m_3=0.15$的效果较好。
同时,作者也尝试将Arcface融入Triplet loss中,但效果不太明显。
至此,我在工作中常用到的损失函数介绍完成了。后续继续跟进和补充该文章,感谢阅读。

