
Strom
Strom是什么
Apache Storm is a free and open source distributed realtime computation system 免费 开源 分布式 实时计算系统 Storm makes it easy to reliably process unbounded streams of data unbounded: 无界 bounded: Hadoop/Spark SQL 离线(input .... output) Storm has many use cases: realtime analytics(实时分析), online machine learning(在线机器学习), continuous computation(连续计算), distributed RPC(分布式RPC), ETL, and more. Storm特点 fast:a million tuples processed per second per node scalable(可拓展), fault-tolerant(容错), guarantees your data will be processed( 保证您的数据得到处理) and is easy to set up and operate(并且易于设置和操作). 小结:Strom能实现高频数据和大规模数据的实时处理 Storm产生于BackType(被Twitter收购)公司 #...# 需求:大数据的实时处理 自己来实现实时系统,要考虑的因素: 1) 健壮性 2) 扩展性/分布式 3) 如何使得数据不丢失,不重复 4) 高性能、低延时 Storm开源 2011.9 Apache Clojure Java Storm技术网站 1) 官网: storm.apache.org 2) GitHub: github.com/apache/storm 3) wiki: https://en.wikipedia.org/wiki/Storm_(event_processor) Storm vs Hadoop 数据源/处理领域 处理过程 Hadoop: Map Reduce Storm: Spout Bolt 进程是否结束 处理速度 使用场景![]()
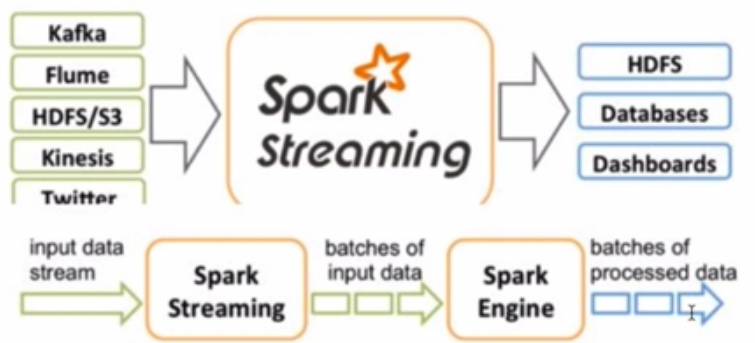
storm和spark streaming的区别
storm


发展趋势 1) 社区的发展、活跃度 2) 企业的需求 3) 大数据相关的大会, Storm主题的数量上升 4) 互联网 JStorm
storm核心概念
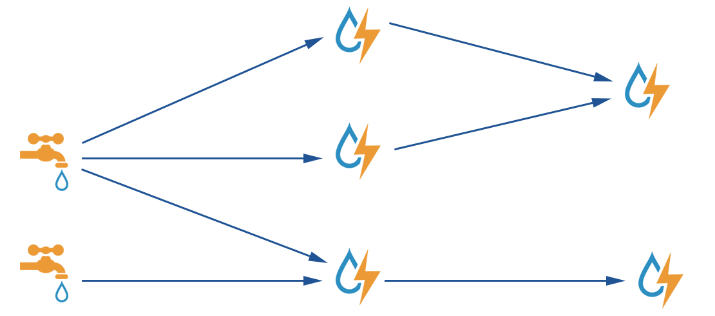
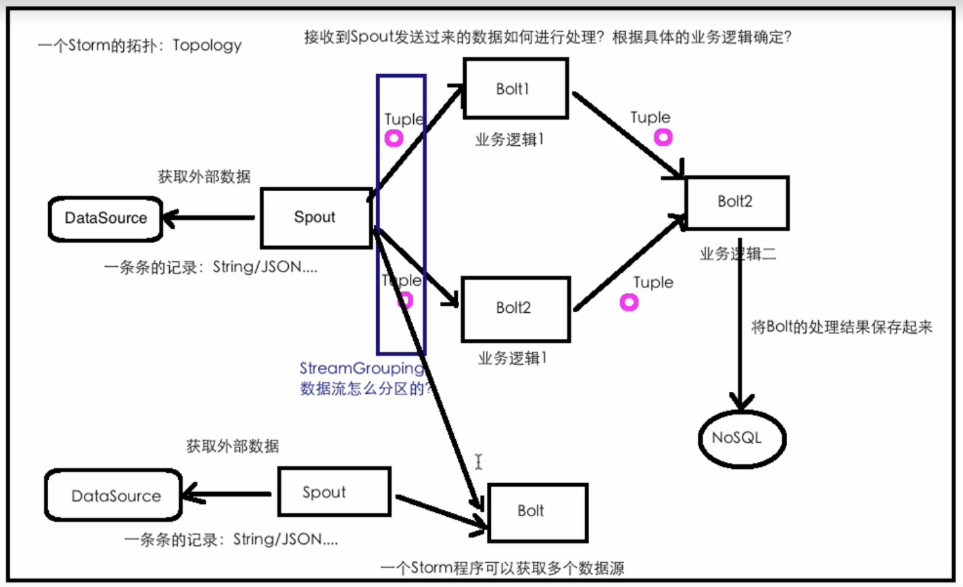
核心概念 Topologies 拓扑,将整个流程串起来 Streams 流,数据流,水流 Spouts 产生数据/水的东西 Bolts 处理数据/水的东西 水壶/水桶 Tuple 数据/水
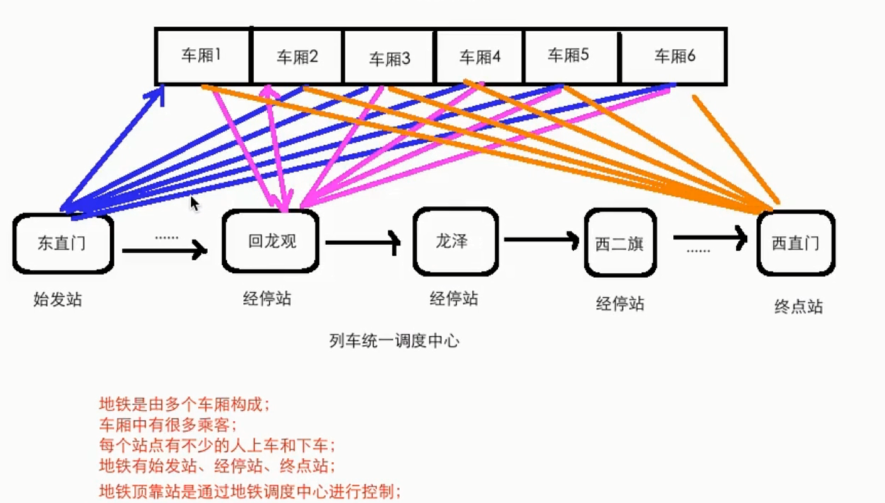
地铁运行模型:
storm:
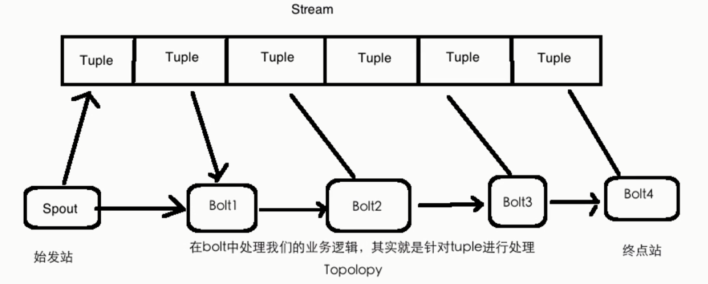
Storm核心概念总结 Topology: 计算拓扑,由spout和bolt组成的 Stream:消息流,抽象概念,没有边界的tuple构成 Tuple:消息/数据 传递的基本单元 Spout:消息流的源头,Topology的消息生产者 Bolt:消息处理单元,可以做过滤、聚合、查询/写数据库的操作
图解:
storm编程
搭建开发环境 jdk: 1.8 windows: exe linux/mac(dmg): tar ..... 把jdk指定到系统环境变量(~/.bash_profile) export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home export PATH=$JAVA_HOME/bin:$PATH source ~/.bash_profile echo $JAVA_HOME java -version IDEA: Maven: 3.3+ windows/linux/mac 下载安装包 tar .... -C ~/app 把maven指定到系统环境变量(~/.bash_profile) export MAVEN_HOME=/Users/rocky/app/apache-maven-3.3.9 export PATH=$MAVEN_HOME/bin:$PATH source ~/.bash_profile echo $JAVA_HOME mvn -v 调整maven依赖下载的jar所在位置: $MAVEN_HOME/conf/setting.xml <localRepository>/Users/rocky/maven_repos</localRepository> 在pom.xml中添加storm的maven依赖 <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.1.1</version> </dependency> ISpout 概述 核心接口(interface),负责将数据发送到topology中去处理 Storm会跟踪Spout发出去的tuple的DAG ack/fail tuple: message id ack/fail/nextTuple是在同一个线程中执行的,所以不用考虑线程安全方面 核心方法 open: 初始化操作 close: 资源释放操作 nextTuple: 发送数据 core api ack: tuple处理成功,storm会反馈给spout一个成功消息 fail:tuple处理失败,storm会发送一个消息给spout,处理失败 实现类 public abstract class BaseRichSpout extends BaseComponent implements IRichSpout { public interface IRichSpout extends ISpout, IComponent DRPCSpout ShellSpout IComponent接口 概述: public interface IComponent extends Serializable 为topology中所有可能的组件提供公用的方法 void declareOutputFields(OutputFieldsDeclarer declarer); 用于声明当前Spout/Bolt发送的tuple的名称 使用OutputFieldsDeclarer配合使用 实现类: public abstract class BaseComponent implements IComponent IBolt接口 概述 职责:接收tuple处理,并进行相应的处理(filter/join/....) hold住tuple再处理 IBolt会在一个运行的机器上创建,使用Java序列化它,然后提交到主节点(nimbus)上去执行 nimbus会启动worker来反序列化,调用prepare方法,然后才开始处理tuple处理 方法 prepare:初始化 execute:处理一个tuple暑假,tuple对象中包含了元数据信息 cleanup:shutdown之前的资源清理操作 实现类: public abstract class BaseRichBolt extends BaseComponent implements IRichBolt { public interface IRichBolt extends IBolt, IComponent RichShellBolt 导入storm包
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.1.1</version>
</dependency>
导入操作文件工具包
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
求和案例 需求:1 + 2 + 3 + .... = ??? 实现方案: Spout发送数字作为input 使用Bolt来处理业务逻辑:求和 将结果输出到控制台 拓扑设计: DataSourceSpout --> SumBolt
package com.imooc.bigdata; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.topology.base.BaseRichSpout; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import org.apache.storm.utils.Utils; import java.util.Map; /** * 使用Storm实现积累求和的操作 */ public class LocalSumStormTopology { /** * Spout需要继承BaseRichSpout * 数据源需要产生数据并发射 */ public static class DataSourceSpout extends BaseRichSpout { private SpoutOutputCollector collector; /** * 初始化方法,只会被调用一次 * @param conf 配置参数 * @param context 上下文 * @param collector 数据发射器 */ public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { this.collector = collector; } int number = 0; /** * 会产生数据,在生产上肯定是从消息队列中获取数据 * 这个方法是一个死循环,会一直不停的执行 */ public void nextTuple() { this.collector.emit(new Values(++number)); System.out.println("Spout: " + number); // 防止数据产生太快 Utils.sleep(1000); } /** * 声明输出字段 * @param declarer */ public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("num")); } } /** * 数据的累积求和Bolt:接收数据并处理 */ public static class SumBolt extends BaseRichBolt { /** * 初始化方法,会被执行一次 * @param stormConf * @param context * @param collector */ public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { } int sum = 0; /** * 其实也是一个死循环,职责:获取Spout发送过来的数据 * @param input */ public void execute(Tuple input) { // Bolt中获取值可以根据index获取,也可以根据上一个环节中定义的field的名称获取(建议使用该方式) Integer value = input.getIntegerByField("num"); sum += value; System.out.println("Bolt: sum = [" + sum + "]"); } public void declareOutputFields(OutputFieldsDeclarer declarer) { } } public static void main(String[] args) { // TopologyBuilder根据Spout和Bolt来构建出Topology // Storm中任何一个作业都是通过Topology的方式进行提交的 // Topology中需要指定Spout和Bolt的执行顺序 TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("DataSourceSpout", new DataSourceSpout()); builder.setBolt("SumBolt", new SumBolt()).shuffleGrouping("DataSourceSpout"); // 创建一个本地Storm集群:本地模式运行,不需要搭建Storm集群 LocalCluster cluster = new LocalCluster(); cluster.submitTopology("LocalSumStormTopology", new Config(), builder.createTopology()); } }
词频统计 需求:读取指定目录的数据,并实现单词计数功能 实现方案: Spout来读取指定目录的数据,作为后续Bolt处理的input 使用一个Bolt把input的数据,切割开,我们按照逗号进行分割 使用一个Bolt来进行最终的单词的次数统计操作 并输出 拓扑设计: DataSourceSpout ==> SplitBolt ==> CountBolt
package com.imooc.bigdata; import org.apache.commons.io.FileUtils; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.topology.base.BaseRichSpout; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import java.io.File; import java.io.IOException; import java.util.*; /** * 使用Storm完成词频统计功能 */ public class LocalWordCountStormTopology { public static class DataSourceSpout extends BaseRichSpout { private SpoutOutputCollector collector; public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { this.collector = collector; } /** * 业务: * 1) 读取指定目录的文件夹下的数据:D:/wctest/ * 2) 把每一行数据发射出去 */ public void nextTuple() { // 获取所有文件 Collection<File> files = FileUtils.listFiles(new File("F:\\wctest"),new String[]{"txt"},true); for(File file : files) { try { // 获取文件中的所有内容 List<String> lines = FileUtils.readLines(file); // 获取文件中的每行的内容 for(String line : lines) { // 发射出去 this.collector.emit(new Values(line)); } // TODO... 数据处理完之后,改名,否则一直重复执行 FileUtils.moveFile(file, new File(file.getAbsolutePath() + System.currentTimeMillis())); } catch (IOException e) { e.printStackTrace(); } } } public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("line")); } } /** * 对数据进行分割 */ public static class SplitBolt extends BaseRichBolt { private OutputCollector collector; public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; } /** * 业务逻辑: * line: 对line进行分割,按照逗号 */ public void execute(Tuple input) { String line = input.getStringByField("line"); String[] words = line.split(","); for(String word : words) { this.collector.emit(new Values(word)); } } public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } } /** * 词频汇总Bolt */ public static class CountBolt extends BaseRichBolt { public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { } Map<String,Integer> map = new HashMap<String, Integer>(); /** * 业务逻辑: * 1)获取每个单词 * 2)对所有单词进行汇总 * 3)输出 */ public void execute(Tuple input) { // 1)获取每个单词 String word = input.getStringByField("word"); Integer count = map.get(word); if(count == null) { count = 0; } count ++; // 2)对所有单词进行汇总 map.put(word, count); // 3)输出 System.out.println("~~~~~~~~~~~~~~~~~~~~~~"); Set<Map.Entry<String,Integer>> entrySet = map.entrySet(); for(Map.Entry<String,Integer> entry : entrySet) { System.out.println(entry); } } public void declareOutputFields(OutputFieldsDeclarer declarer) { } } public static void main(String[] args) { // 通过TopologyBuilder根据Spout和Bolt构建Topology TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("DataSourceSpout", new DataSourceSpout()); builder.setBolt("SplitBolt", new SplitBolt()).shuffleGrouping("DataSourceSpout"); builder.setBolt("CountBolt", new CountBolt()).shuffleGrouping("SplitBolt"); // 创建本地集群 LocalCluster cluster = new LocalCluster(); cluster.submitTopology("LocalWordCountStormTopology", new Config(), builder.createTopology()); } }
Storm编程注意事项 1) Exception in thread "main" java.lang.IllegalArgumentException: Spout has already been declared for id DataSourceSpout 2) org.apache.storm.generated.InvalidTopologyException: null 3) topology的名称不是重复: local似乎没问题, 等我们到集群测试的时候再来验证这个问题
storm周边框架使用
环境前置说明: 通过我们的客户端(终端,CRT,XShell) ssh hadoop@hadoop000 ssh hadoop@192.168.199.102 远程服务器的用户名是hadoop,密码也是hadoop 有没有提供root权限,sudo command hadoop000(192.168.199.102)是远程服务器的hostname 如果你想在本地通过ssh hadoop@hadoop000远程登录, 那么你本地的hosts肯定要添加ip和hostname的映射 192.168.199.102 hadoop000 JDK的安装 将所有的软件都安装到~/app tar -zxvf jdk-8u91-linux-x64.tar.gz -C ~/app/ 建议将jdk的bin目录配置到系统环境变量中: ~/.bash_profile export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91 export PATH=$JAVA_HOME/bin:$PATH 让系统环境变量生效 source ~/.bash_profile 验证 java -version ZooKeeper安装 下载ZK的安装包:http://archive.cloudera.com/cdh5/cdh/5/
解压:tar -zxvf zookeeper-3.4.5-cdh5.7.0.tar.gz -C ~/app/ 建议ZK_HOME/bin添加到系统环境变量: ~/.bash_profile export ZK_HOME=/home/hadoop/app/zookeeper-3.4.5-cdh5.7.0 export PATH=$ZK_HOME/bin:$PATH 让系统环境变量生效 source ~/.bash_profile 修改ZK的配置: $ZK_HOME/conf/zoo.cfg dataDir=/home/hadoop/app/tmp/zookeeper 启动zk: $ZK_HOME/bin/ zkServer.sh start 验证: jps 多了一个QuorumPeerMain进程,就表示zk启动成功了 ELK: www.elastic.co
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的 “存储库” 中
选择2.4版本,

解压:[root@mini1 apps]# tar -zxvf logstash-2.4.0.tar.gz
控制台输入控制台输出:
(1)cd logstash-2.4.0
bin/logstash -e 'input { stdin { } } output { stdout {} }'

(2)[root@mini1 logstash-2.4.0]# bin/logstash -e 'input { stdin { } } output { stdout {codec=>json} }'

(3)vi test.conf

[root@mini1 logstash-2.4.0]# bin/logstash -f test.conf

文件输入控制台输出:
在官网input plugins可以看到:


[root@mini1 logstash-2.4.0]# touch logstash.txt
[root@mini1 logstash-2.4.0]# pwd
/root/apps/logstash-2.4.0
[root@mini1 logstash-2.4.0]# vi file_stdout.conf
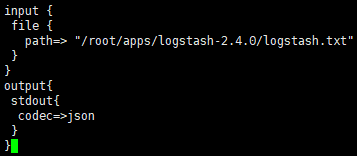
[root@mini1 logstash-2.4.0]# bin/logstash -f file_stdout.conf

在文件中输入:
[root@mini1 logstash-2.4.0]# echo "hello" >> logstash.txt
[root@mini1 logstash-2.4.0]# echo "world" >> logstash.txt

订阅多个文件:

更多使用方法可以在官网查看:https://www.elastic.co/guide/en/logstash/2.4/plugins-inputs-file.html
kafka概述
读取和写入数据流,如消息传递系统。
编写可实时处理事件的可扩展流处理应用程序。
在分布式、复制、容错集群中安全地存储数据流。
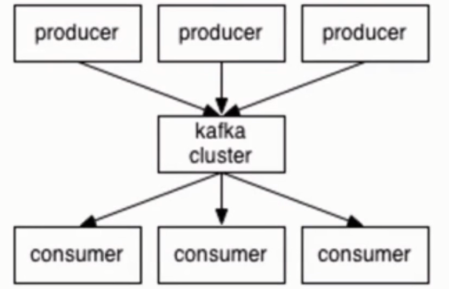
kafka用于构建实时数据管道和流式应用程序。它是水平可扩展的,容错的,快速的,并运行在生产成千上万的公司。

流媒体平台具有三个关键功能:
- 发布和订阅记录流,类似于消息队列或企业消息系统。
- 以容错的持久方式存储记录流。
- 记录发生时的处理流。
卡夫卡通常用于两类广泛的应用:
- 建立实时流数据管道,在系统或应用之间可靠地获取数据
- 建立对数据流进行转换或反应的实时流应用程序
kafka架构和核心概念

[root@mini1 apps]# yum install wget -y
[root@mini1 apps]# wget https://archive.apache.org/dist/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgz
[root@mini1 apps]# tar -zxvf kafka_2.11-0.9.0.0.tgz
[root@mini1 apps]# cd kafka_2.11-0.9.0.0/bin
[root@mini1 bin]# pwd
/root/apps/kafka_2.11-0.9.0.0/bin
[root@mini1 bin]# vi ~/.bash_profile
export KAFKA_HOME=/root/apps/kafka_2.11-0.9.0.0
export PATH=$KAFAK_HOME/bin:$PATH
[root@mini1 config]# vi /root/apps/kafka_2.11-0.9.0.0/config/server.properties
broker.id=0 listeners=PLAINTEXT://:9092 host.name=mini1 log.dirs=/root/apps/tmp/kafka-logs zookeeper.connect=mini1:2181
1)单节点单broker部署及使用
可以在官网http://kafka.apache.org/quickstart看使用方法
[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-server-start.sh
USAGE: bin/kafka-server-start.sh [-daemon] server.properties [--override property=value]*
启动:
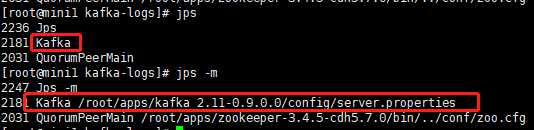
[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-server-start.sh config/server.properties
使用jps或jps -m 查看是否启动成功
创建topic
可以先查看kafka-topics.sh 的用法:[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-topics.sh
创建:[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-topics.sh --create --zookeeper mini1:2181 --replication-factor 1 --partitions 1 --topic hello-topic 查看所有topics:[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-topics.sh --list --zookeeper mini1:2181 发送消息:[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-console-producer.sh --broker-list mini1:9092 --topic hello-topic 消费消息:[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-console-consumer.sh --zookeeper mini1:2181 --topic hello-topic --from-beginning --from-beginning的使用:从头开始消费信息
查看topic信息:[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-topics.sh --describe --zookeeper mini1:2181
2)单节点多broker部署及使用
[root@mini1 kafka_2.11-0.9.0.0]# cp config/server.properties config/server-1.properties
[root@mini1 kafka_2.11-0.9.0.0]# cp config/server.properties config/server-2.properties
[root@mini1 kafka_2.11-0.9.0.0]# cp config/server.properties config/server-3.properties
[root@mini1 kafka_2.11-0.9.0.0]# vi config/server-1.properties
[root@mini1 kafka_2.11-0.9.0.0]# vi config/server-2.properties
[root@mini1 kafka_2.11-0.9.0.0]# vi config/server-3.properties
分别修改:
broker.id=1 2 3
listeners=PLAINTEXT://:9093 9094 9095
log.dirs=/root/apps/tmp/kafka-logs-1 2 3
后台启动,加-daemon
[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server-1.properties &
[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server-2.properties &
[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server-3.properties &
查看:[root@mini1 kafka_2.11-0.9.0.0]# jps -m

创建topic,副本3个--replication-factor 3
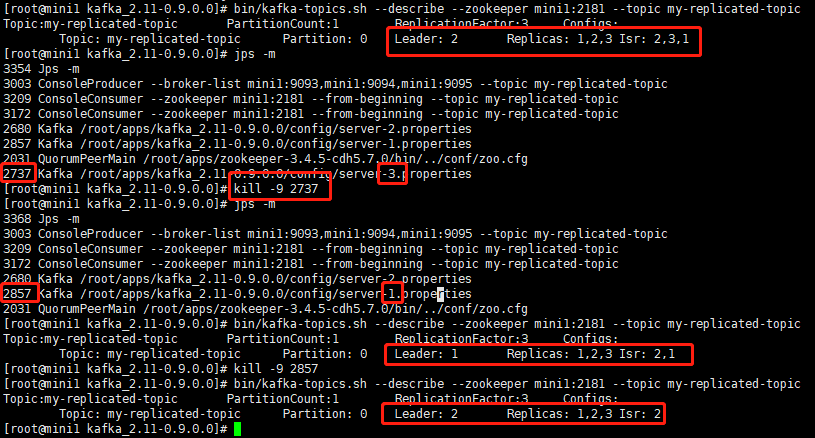
[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-topics.sh --create --zookeeper mini1:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
查看:[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-topics.sh --describe --zookeeper mini1:2181 --topic my-replicated-topic
发送信息:[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-console-producer.sh --broker-list mini1:9093,mini1:9094,mini1:9095 --topic my-replicated-topic
消费信息:bin/kafka-console-consumer.sh --zookeeper mini1:2181 --from-beginning --topic my-replicated-topic

kafka主要有一个节点存活,就还可以发送消费信息
logstash整合kafka
kafka准备:
启动:[root@mini1 kafka_2.11-0.9.0.0]bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
创建:[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-topics.sh --create --zookeeper mini1:2181 --replication-factor 1 --partitions 1 --topic logstash-topic
发送:[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-console-producer.sh --broker-list mini1:9092 --topic logstash-topic
消费:[root@mini1 kafka_2.11-0.9.0.0]# bin/kafka-console-consumer.sh --zookeeper mini1:2181 --topic logstash-topic
[root@mini1 logstash-2.4.0]# vi file_kafka.conf
input { file { path=> "/root/apps/logstash-2.4.0/logstash.txt" } } output{ kafka{ topic_id =>"logstash-topic" bootstrap_servers => "mini1:9092" batch_size => 1 } }
启动logstash:[root@mini1 logstash-2.4.0]# bin/logstash -f file_kafka.conf
获取数据:[root@mini1 logstash-2.4.0]# echo "hello world ssssssssss" >> logstash.txt
kafka消费数据:{"message":"hello world ssssssssss","@version":"1","@timestamp":"2018-08-24T16:04:50.660Z","path":"/root/apps/logstash-2.4.0/logstash.txt","host":"mini1"}
storm架构及部署
storm架构
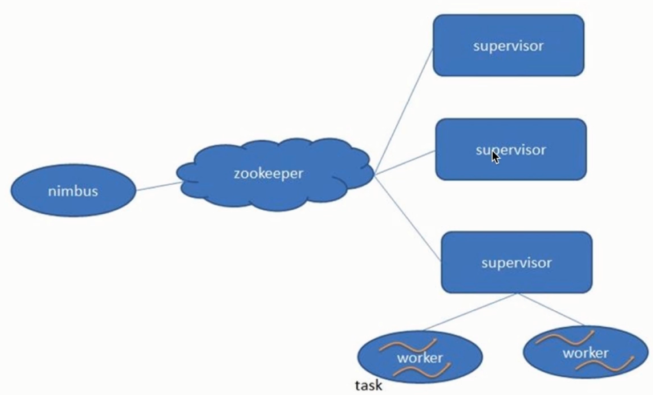
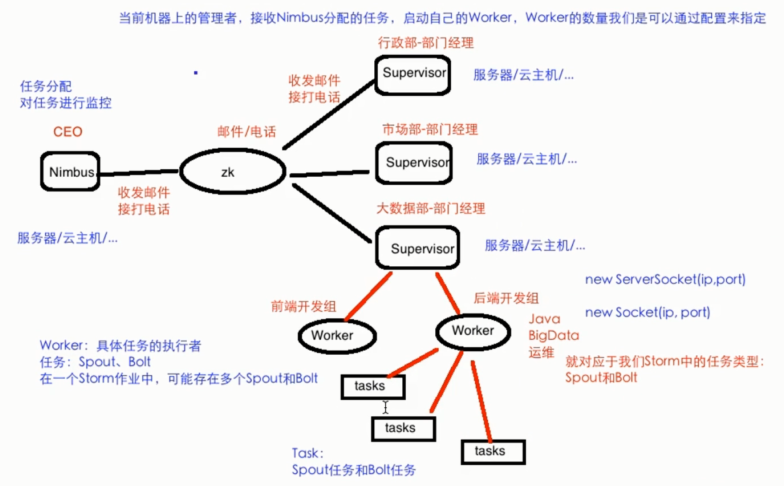
类似于Hadoop的架构,主从(Master/Slave) Nimbus: 主 集群的主节点,负责任务(task)的指派和分发、资源的分配 Supervisor: 从 可以启动多个Worker,具体几个呢?可以通过配置来指定 一个Topo可以运行在多个Worker之上,也可以通过配置来指定 集群的从节点,(负责干活的),负责执行任务的具体部分 启动和停止自己管理的Worker进程 无状态,在他们上面的信息(元数据)会存储在ZK中 Worker: 运行具体组件逻辑(Spout/Bolt)的进程 =====================分割线=================== task: Spout和Bolt Worker中每一个Spout和Bolt的线程称为一个Task executor: spout和bolt可能会共享一个线程
Storm部署
Storm部署的前置条件
jdk7+
python2.6.6+
我们课程使用的Storm版本是:1.1.1
Storm部署
下载
解压到~/app
添加到系统环境变量:~/.bash_profile
export STORM_HOME=/home/hadoop/app/apache-storm-1.1.1
export PATH=$STORM_HOME/bin:$PATH
使其生效: source ~/.bash_profile
目录结构
bin
examples
conf
lib
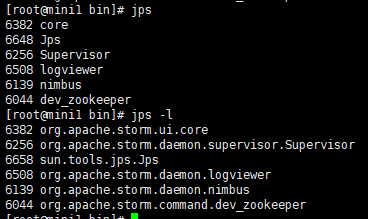
Storm启动
$STORM_HOME/bin/storm 如何使用 执行storm就能看到很多详细的命令
yum install coreutils
dev-zookeeper 启动zk
storm dev-zookeeper 前台启动
nohup sh storm dev-zookeeper &
jps : dev_zookeeper
nimbus 启动主节点
nohup sh storm nimbus &
supervisor 启动从节点
nohup sh storm supervisor &
ui 启动UI界面
nohup sh storm ui &
logviewer 启动日志查看服务
nohup sh storm logviewer &
![]()
注意事项 1) 为什么是4个slot 2) 为什么有2个Nimbus
如何修改将跑在本地的storm app改成运行在集群上的
// 代码提交到Storm集群上运行 String topoName=ClusterSumStormTopology.class.getSimpleName(); try { StormSubmitter.submitTopology(topoName, new Config(), builder.createTopology()); } catch (Exception e) { e.printStackTrace(); }
maven install 可以打包,不包含依赖包,通过路径查看 ,上传到集群
Storm如何运行我们自己开发的应用程序呢? Syntax: storm jar topology-jar-path class args0 args1 args2 storm jar /home/hadoop/lib/storm-1.0.jar com.imooc.bigdata.ClusterSumStormTopology 问题: 3个executor,那么页面就看到spout1个和bolt1个,那么还有一个去哪了?
storm的所有命令说明:http://storm.apache.org/releases/1.1.2/Command-line-client.html
storm 其他命令的使用 list Syntax: storm list List the running topologies and their statuses. 如何停止作业 kill Syntax: storm kill topology-name [-w wait-time-secs] 如何停止集群 hadoop: stop-all.sh kill -9 pid,pid.... Storm集群的部署规划 hadoop000 192.168.199.102 hadoop001 192.168.199.247 hadoop002 192.168.199.138 每台机器的host映射:/etc/hosts 192.168.199.102 hadoop000 192.168.199.247 hadoop001 192.168.199.138 hadoop002 hadoop000: zk nimbus supervisor hadoop001: zk supervisor hadoop002: zk supervisor 安装包的分发: 从hadoop000机器做为出发点 scp xxxx hadoop@hadoop001:~/software scp xxxx hadoop@hadoop002:~/software jdk的安装 解压 配置到系统环境变量 验证 ZK分布式环境的安装,在zoo.cfg中添加 server.1=hadoop000:2888:3888 server.2=hadoop001:2888:3888 server.3=hadoop002:2888:3888 在一下目录中创建myid hadoop000的dataDir目录: myid的值1 hadoop001的dataDir目录: myid的值2 hadoop002的dataDir目录: myid的值3
添加到系统环境变量:~/.bash_profile
export JAVA_HOME=/root/apps/jdk1.7.0_80 export HADOOP_HOME=/root/apps/hadoop export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export ZK_HOME=/root/apps/zookeeper-3.4.5-cdh5.7.0 export PATH=$ZK_HOME/bin:$PATH export KAFKA_HOME=/root/apps/kafka_2.11-0.9.0.0 export PATH=$KAFAK_HOME/bin:$PATH export STORM_HOME=/root/apps/apache-storm-1.1.1 export PATH=$STORM_HOME/bin:$PATH
在每个节点上启动zk: zkServer.sh start 在每个节点上查看当前机器zk的状态: zkServer.sh status Storm集群
在storm_env.sh中加入jkd路径 $STORM_HOME/conf/storm.yaml 严格注意格式(yaml语言) storm.zookeeper.servers: - "hadoop000" - "hadoop001" - "hadoop002" storm.local.dir: "/home/hadoop/app/tmp/storm" supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703 启动 hadoop000: nimbus supervisor(ui,logviewer) hadoop001: supervisor(logviewer) hadoop002: supervisor(logviewer) nimbus 启动主节点 nohup sh storm nimbus & supervisor 启动从节点 nohup sh storm supervisor & ui 启动UI界面 nohup sh storm ui & logviewer 启动日志查看服务 nohup sh storm logviewer & 启动完所有的进程之后,查看 [hadoop@hadoop000 bin]$ jps 7424 QuorumPeerMain 8164 Supervisor 7769 nimbus 8380 logviewer 7949 core [hadoop@hadoop001 bin]$ jps 3142 logviewer 2760 QuorumPeerMain 2971 Supervisor [hadoop@hadoop002 bin]$ jps 3106 logviewer 2925 Supervisor 2719 QuorumPeerMain storm jar /home/hadoop/lib/storm-1.0.jar com.imooc.bigdata.ClusterSumStormTopology 目录树 storm.local.dir nimbus/inbox:stormjar-....jar supervisor/stormdist ClusterSumStormTopology-1-1511599690 │ │ ├── stormcode.ser │ │ ├── stormconf.ser │ │ └── stormjar.jar
并行度
一个worker进程执行的是一个topo的子集
一个worker进程会启动1..n个executor线程来执行一个topo的component
一个运行的topo就是由集群中多台物理机上的多个worker进程组成
executor是一个被worker进程启动的单独线程,每个executor只会运行1个topo的一个component
task是最终运行spout或者bolt代码的最小执行单元
默认:
一个supervisor节点最多启动4个worker进程 ?
每一个topo默认占用一个worker进程 ?
每个worker进程会启动一个executor ?
每个executor启动一个task ?
Total slots:4
Executors: 3 ???? spout + bolt = 2 why 3?
acker 导致的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号