
辅助系统(Flume,azkaban,sqoop)
前言
在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集、结果数据导出、任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中都有便捷的开源框架,如图所示:

1. 日志采集框架Flume
1.1 Flume介绍
1.1.1 概述
Flume是Cloudera提供的一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
Flume可以采集文件,socket数据包、文件夹等各种形式源数据,又可以将采集到的数据输出到HDFS、hbase、hive、kafka等众多外部存储系统中
一般的采集需求,通过对flume的简单配置即可实现
Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
当前Flume有两个版本:
Flume 0.9X版本的统称Flume-og,
Flume1.X版本的统称Flume-ng。
由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。
1.1.2 运行机制
1、 Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
2、 每一个agent相当于一个数据传递员,内部有三个组件:
a) Source:采集源,用于跟数据源对接,以获取数据
b) Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
c) Channel:angent内部的数据传输通道,用于从source将数据传递到sink
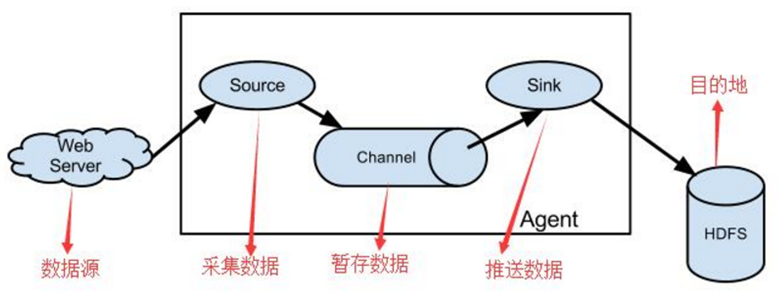
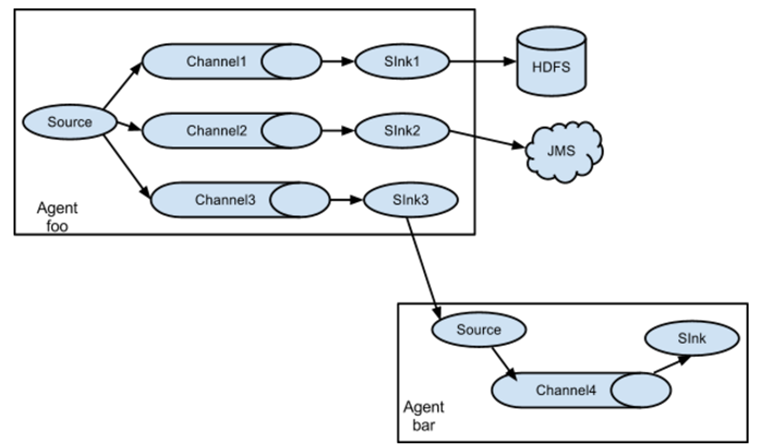
1.1.3 Flume采集系统结构图
1.1.3.1. 简单结构
单个agent采集数据
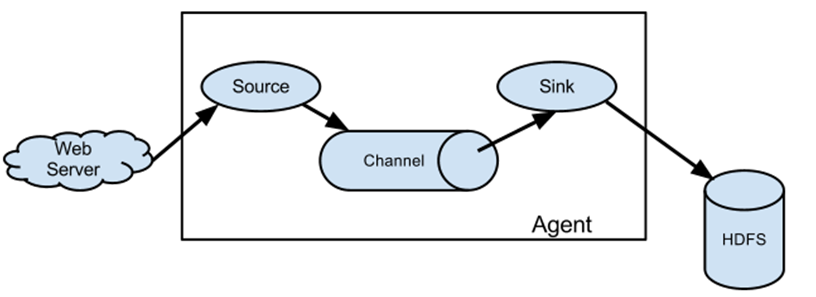
1.1.3.2. 复杂结构
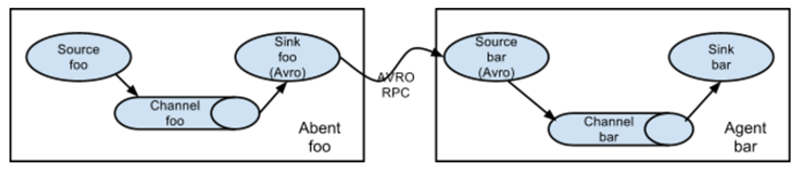
多级agent之间串联
(1)第一种:2个agent串联
(2)第二种:多个agent的采集的数据进行汇总
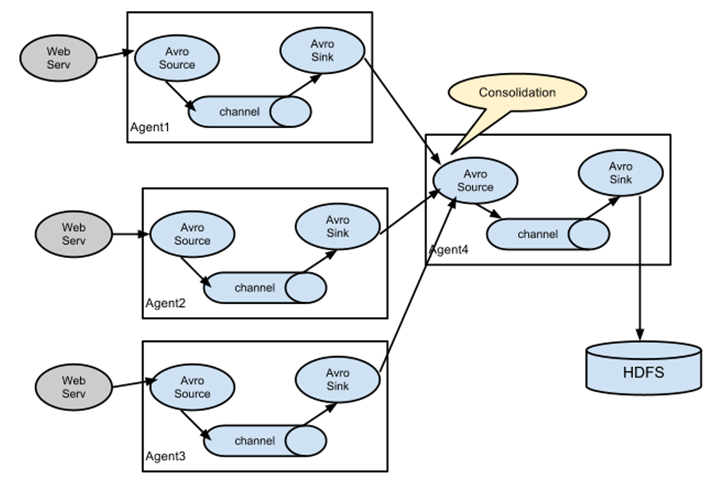
(3)第三种:采集的数据可以下层到不同的系统中
1.2 Flume实战案例
1.2.1 Flume的安装部署
1、Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境
上传安装包到数据源所在节点上
然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz
然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
2、根据数据采集的需求配置采集方案,描述在配置文件中(文件名可任意自定义)
3、指定采集方案配置文件,在相应的节点上启动flume agent
先用一个最简单的例子来测试一下程序环境是否正常
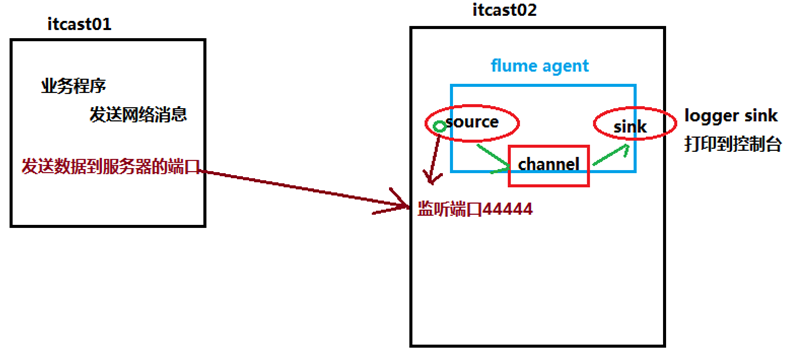
1、先在flume的conf目录下新建一个文件
vi netcat-logger.conf
|
# 定义这个agent中各组件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1
# 描述和配置source组件:r1 a1.sources.r1.type = netcat a1.sources.r1.bind = itcast01 a1.sources.r1.port = 44444
# 描述和配置sink组件:k1 a1.sinks.k1.type = logger
# 描述和配置channel组件,此处使用是内存缓存的方式 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
# 描述和配置source channel sink之间的连接关系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
2、启动agent去采集数据
|
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console |
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
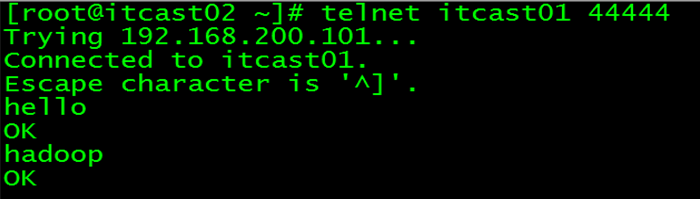
3、测试
先要往agent采集监听的端口上发送数据,让agent有数据可采
随便在一个能跟agent节点联网的机器上

telnet anget-hostname port (telnet itcast01 44444)
1.2.2 Flume中常用的source、channel、sink组件
1.2.2.1 source组件
|
Source类型 |
说明 |
|
Avro Source |
支持Avro协议(实际上是Avro RPC),内置支持 |
|
Thrift Source |
支持Thrift协议,内置支持 |
|
Exec Source |
基于Unix的command在标准输出上生产数据 |
|
JMS Source |
从JMS系统(消息、主题)中读取数据,ActiveMQ已经测试过 |
|
Spooling Directory Source |
监控指定目录内数据变更 |
|
Twitter 1% firehose Source |
通过API持续下载Twitter数据,试验性质 |
|
Netcat Source |
监控某个端口,将流经端口的每一个文本行数据作为Event输入 |
|
Sequence Generator Source |
序列生成器数据源,生产序列数据 |
|
Syslog Sources |
读取syslog数据,产生Event,支持UDP和TCP两种协议 |
|
HTTP Source |
基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式 |
|
Legacy Sources |
兼容老的Flume OG中Source(0.9.x版本) |
1.2.2.2 Channel组件
|
Channel类型 |
说明 |
|
Memory Channel |
Event数据存储在内存中 |
|
JDBC Channel |
Event数据存储在持久化存储中,当前Flume Channel内置支持Derby |
|
File Channel |
Event数据存储在磁盘文件中 |
|
Spillable Memory Channel |
Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用) |
|
Pseudo Transaction Channel |
测试用途 |
|
Custom Channel |
自定义Channel实现 |
1.2.2.3 sink组件
|
Sink类型 |
说明 |
|
HDFS Sink |
数据写入HDFS |
|
Logger Sink |
数据写入日志文件 |
|
Avro Sink |
数据被转换成Avro Event,然后发送到配置的RPC端口上 |
|
Thrift Sink |
数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
|
IRC Sink |
数据在IRC上进行回放 |
|
File Roll Sink |
存储数据到本地文件系统 |
|
Null Sink |
丢弃到所有数据 |
|
HBase Sink |
数据写入HBase数据库 |
|
Morphline Solr Sink |
数据发送到Solr搜索服务器(集群) |
|
ElasticSearch Sink |
数据发送到Elastic Search搜索服务器(集群) |
|
Kite Dataset Sink |
写数据到Kite Dataset,试验性质的 |
|
Custom Sink |
自定义Sink实现 |
Flume支持众多的source、channel、sink类型,详细手册可参考官方文档
http://flume.apache.org/FlumeUserGuide.html
1.2.3 采集案例
1.2.3.1、采集目录到HDFS
采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去
根据需求,首先定义以下3大要素
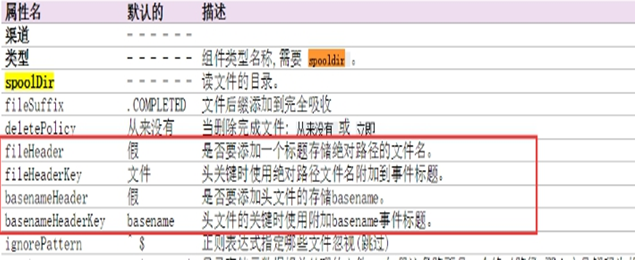
采集源,即source——监控文件目录 : spooldir
下沉目标,即sink——HDFS文件系统 : hdfs sink
source和sink之间的传递通道——channel,可用file channel 也可以用内存memory channel
配置文件编写:
|
#定义三大组件的名称 agent1.sources = source1 agent1.sinks = sink1 agent1.channels = channel1
# 配置source组件 agent1.sources.source1.type = spooldir agent1.sources.source1.spoolDir = /root/data/ agent1.sources.source1.fileHeader = false
#配置拦截器 agent1.sources.source1.interceptors = i1 agent1.sources.source1.interceptors.i1.type = timestamp # 配置sink组件 agent1.sinks.sink1.type = hdfs agent1.sinks.sink1.hdfs.path =/weblog/flume-collection/%y-%m-%d/%H-%M agent1.sinks.sink1.hdfs.filePrefix = access_log agent1.sinks.sink1.hdfs.maxOpenFiles = 5000 agent1.sinks.sink1.hdfs.batchSize= 100 agent1.sinks.sink1.hdfs.fileType = DataStream agent1.sinks.sink1.hdfs.writeFormat =Text #滚动生成的文件按大小生成 agent1.sinks.sink1.hdfs.rollSize = 102400 #滚动生成的文件按行数生成 agent1.sinks.sink1.hdfs.rollCount = 1000000 #滚动生成的文件按时间生成 agent1.sinks.sink1.hdfs.rollInterval = 60 #开启滚动生成目录 agent1.sinks.sink1.hdfs.round = true #以10为一梯度滚动生成 agent1.sinks.sink1.hdfs.roundValue = 10 #单位为分钟 agent1.sinks.sink1.hdfs.roundUnit = minute
# Use a channel which buffers events in memory agent1.channels.channel1.type = memory agent1.channels.channel1.capacity = 500000 agent1.channels.channel1.transactionCapacity = 600 agent1.channels.channel1.keep-alive = 120
# Bind the source and sink to the channel agent1.sources.source1.channels = channel1 agent1.sinks.sink1.channel = channel1 |
flume的source采用spoodir时! 目录下面不允许存放同名的文件,否则报错!
Channel参数解释:
capacity:默认该通道中最大的可以存储的event数量
trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量
keep-alive:event添加到通道中或者移出的允许时间
其他组件:Interceptor(拦截器)
用于Source的一组Interceptor,按照预设的顺序在必要地方装饰和过滤events。
内建的Interceptors允许增加event的headers比如:时间戳、主机名、静态标记等等
定制的interceptors可以通过内省event payload(读取原始日志),实现自己的业务逻辑(很强大)
1.2.3.2、采集文件到HDFS
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs
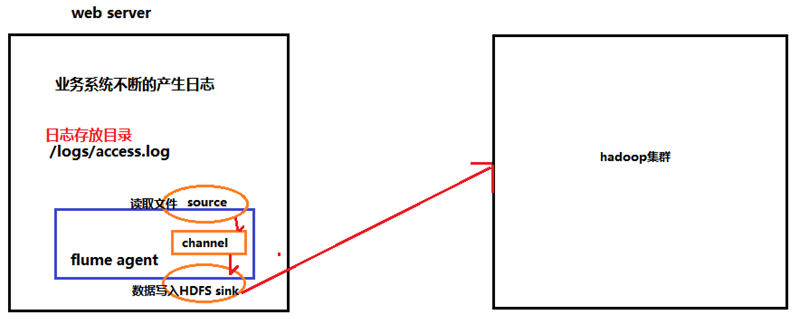
根据需求,首先定义以下3大要素
采集源,即source——监控文件内容更新 : exec ‘tail -F file’
下沉目标,即sink——HDFS文件系统 : hdfs sink
Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
配置文件编写:
|
agent1.sources = source1 agent1.sinks = sink1 agent1.channels = channel1
# Describe/configure tail -F source1 agent1.sources.source1.type = exec agent1.sources.source1.command = tail -F /home/hadoop/logs/access_log agent1.sources.source1.channels = channel1
#configure host for source agent1.sources.source1.interceptors = i1 i2 agent1.sources.source1.interceptors.i1.type = host agent1.sources.source1.interceptors.i1.hostHeader = hostname agent1.sources.source1.interceptors.i1.userIP=false; agent1.sources.source1.interceptors.i2.type=timestamp
# Describe sink1 agent1.sinks.sink1.type = hdfs #a1.sinks.k1.channel = c1 agent1.sinks.sink1.hdfs.path=hdfs://itcast01:9000/file/%{hostname}/%y-%m-%d/%H-%M agent1.sinks.sink1.hdfs.filePrefix = access_log agent1.sinks.sink1.hdfs.batchSize= 100 agent1.sinks.sink1.hdfs.fileType = DataStream agent1.sinks.sink1.hdfs.writeFormat =Text agent1.sinks.sink1.hdfs.rollSize = 10240 agent1.sinks.sink1.hdfs.rollCount = 1000 agent1.sinks.sink1.hdfs.rollInterval = 10 agent1.sinks.sink1.hdfs.round = true agent1.sinks.sink1.hdfs.roundValue = 10 agent1.sinks.sink1.hdfs.roundUnit = minute
# Use a channel which buffers events in memory agent1.channels.channel1.type = memory agent1.channels.channel1.keep-alive = 120 agent1.channels.channel1.capacity = 500000 agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel agent1.sources.source1.channels = channel1 agent1.sinks.sink1.channel = channel1 |
flume 拦截器(interceptor)
1、flume拦截器介绍
拦截器是简单的插件式组件,设置在source和channel之间。source接收到的事件event,在写入channel之前,拦截器都可以进行转换或者删除这些事件。每个拦截器只处理同一个source接收到的事件。可以自定义拦截器。
2、flume内置的拦截器
2.1 时间戳拦截器
flume中一个最经常使用的拦截器 ,该拦截器的作用是将时间戳插入到flume的事件报头中。如果不使用任何拦截器,flume接受到的只有message。时间戳拦截器的配置:
参数 默认值 描述
type timestamp 类型名称timestamp,也可以使用类名的全路径org.apache.flume.interceptor.TimestampInterceptor$Builder
preserveExisting false 如果设置为true,若事件中报头已经存在,不会替换时间戳报头的值
source连接到时间戳拦截器的配置:
a1.sources.r1.interceptors=i1 a1.sources.r1.interceptors.i1.type=timestamp a1.sources.r1.interceptors.i1.preserveExisting=false
2.2 主机拦截器
主机拦截器插入服务器的ip地址或者主机名,agent将这些内容插入到事件的报头中。事件报头中的key使用hostHeader配置,默认是host。主机拦截器的配置:
参数 默认值 描述
type host 类型名称host,也可以使用类名的全路径org.apache.flume.interceptor.HostInterceptor$Builder
hostHeader host 事件头的key
useIP true 如果设置为false,host键插入主机名
preserveExisting false 如果设置为true,若事件中报头已经存在,不会替换时间戳报头的值
source连接到主机拦截器的配置:
a1.sources.r1.interceptors=i2 a1.sources.r1.interceptors.i2.type=host a1.sources.r1.interceptors.i2.useIP=false a1.sources.r1.interceptors.i2.preserveExisting=false
2.3 静态拦截器
静态拦截器的作用是将k/v插入到事件的报头中。配置如下
参数 默认值 描述
type static 类型名称static,也可以使用类全路径名称org.apache.flume.interceptor.StaticInterceptor$Builder
key key 事件头的key
value value key对应的value值
preserveExisting true 如果设置为true,若事件中报头已经存在该key,不会替换value的值
source连接到静态拦截器的配置:
a1.sources.r1.interceptors= i3 a1.sources.r1.interceptors.static.type=static a1.sources.r1.interceptors.static.key=logs a1.sources.r1.interceptors.static.value=logFlume a1.sources.r1.interceptors.static.preserveExisting=false
2.4 正则过滤拦截器
在日志采集的时候,可能有一些数据是我们不需要的,这样添加过滤拦截器,可以过滤掉不需要的日志,也可以根据需要收集满足正则条件的日志。配置如下
参数 默认值 描述
type REGEX_FILTER 类型名称REGEX_FILTER,也可以使用类全路径名称org.apache.flume.interceptor.RegexFilteringInterceptor$Builder
regex .* 匹配除“\n”之外的任何个字符
excludeEvents false 默认收集匹配到的事件。如果为true,则会删除匹配到的event,收集未匹配到的
source连接到正则过滤拦截器的配置:
a1.sources.r1.interceptors=i4 a1.sources.r1.interceptors.i4.type=REGEX_FILTER a1.sources.r1.interceptors.i4.regex=(rm)|(kill) a1.sources.r1.interceptors.i4.excludeEvents=false
这样配置的拦截器就只会接收日志消息中带有rm 或者kill的日志。
测试案例:
test_regex.conf
# 定义这个agent中各组件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述和配置source组件:r1 a1.sources.r1.type = netcat a1.sources.r1.bind = itcast01 a1.sources.r1.port = 44444 a1.sources.r1. a1.sources.r1.interceptors=i4 a1.sources.r1.interceptors.i4.type=REGEX_FILTER #保留内容中出现hadoop或者是spark的字符串的记录 a1.sources.r1.interceptors.i4.regex=(hadoop)|(spark) a1.sources.r1.interceptors.i4.excludeEvents=false # 描述和配置sink组件:k1 a1.sinks.k1.type = logger # 描述和配置channel组件,此处使用是内存缓存的方式 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 描述和配置source channel sink之间的连接关系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
发送数据测试:
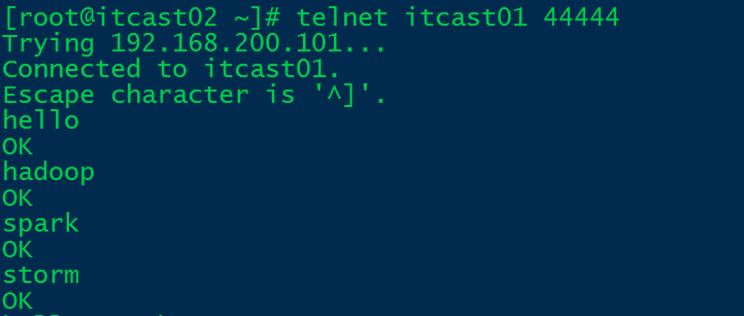
打印到控制台信息:

只接受到存在hadoop或者spark的记录,验证成功!
1.2.3.3、多个agent串联
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs,使用agent串联
根据需求,首先定义以下3大要素
第一台flume agent
采集源,即source——监控文件内容更新 : exec ‘tail -F file’
下沉目标,即sink——数据的发送者,实现序列化 : avro sink
Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
第二台flume agent
采集源,即source——接受数据。并实现反序列化 : avro source
下沉目标,即sink——HDFS文件系统 : HDFS sink
Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
配置文件编写:
Flume-agent1
|
#tail-avro-avro-logger.conf # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1
# Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /root/logs/test.log a1.sources.r1.channels = c1
# Describe the sink ##sink端的avro是一个数据发送者 a1.sinks.k1.type = avro a1.sinks.k1.hostname = itcast02 a1.sinks.k1.port = 41414 a1.sinks.k1.batch-size = 10
# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
Flume-agent2: avro-hdfs.conf
|
a1.sources = r1 a1.sinks =s1 a1.channels = c1
##source中的avro组件是一个接收者服务 a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 #接收来自任何服务器的数据 a1.sources.r1.port = 41414
a1.sinks.s1.type=hdfs a1.sinks.s1.hdfs.path=hdfs://itcast01:9000/flumedata a1.sinks.s1.hdfs.filePrefix = access_log a1.sinks.s1.hdfs.batchSize= 100 a1.sinks.s1.hdfs.fileType = DataStream a1.sinks.s1.hdfs.writeFormat =Text a1.sinks.s1.hdfs.rollSize = 10240 a1.sinks.s1.hdfs.rollCount = 1000 a1.sinks.s1.hdfs.rollInterval = 10 a1.sinks.s1.hdfs.round = true a1.sinks.s1.hdfs.roundValue = 10 a1.sinks.s1.hdfs.roundUnit = minute
a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1 a1.sinks.s1.channel = c1 |



1.2.3.4、高可用配置案例
(一)、failover故障转移
在完成单点的Flume NG搭建后,下面我们搭建一个高可用的Flume NG集群,架构图如下所示:
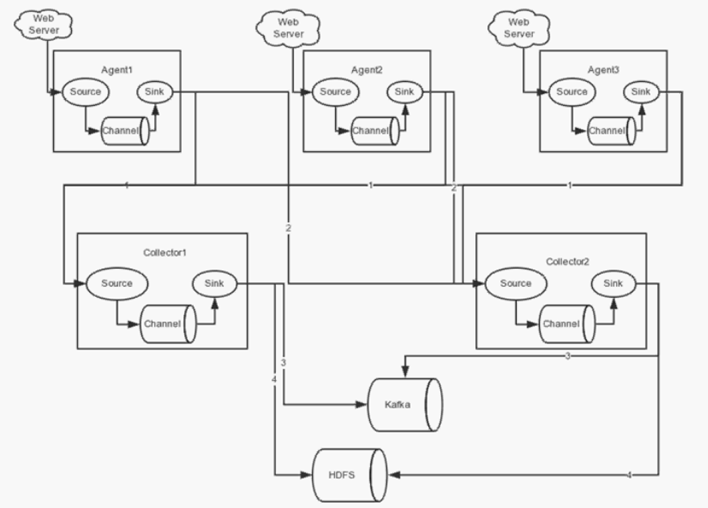
(1)节点分配
Flume的Agent和Collector分布如下表所示:
|
名称 |
Ip地址 |
Host |
角色 |
|
Agent1 |
192.168.200.101 |
Itcast01 |
WebServer |
|
Collector1 |
192.168.200.102 |
Itcast02 |
AgentMstr1 |
|
Collector2 |
192.168.200.103 |
Itcast03 |
AgentMstr2 |
Agent1数据分别流入到Collector1和Collector2,Flume NG本身提供了Failover机制,可以自动切换和恢复。下面我们开发配置Flume NG集群。
(2)配置
在下面单点Flume中,基本配置都完成了,我们只需要新添加两个配置文件,它们是flume-client.conf和flume-server.conf,其配置内容如下所示:
1、itcast01上的flume-client.conf配置
|
#agent1 name agent1.channels = c1 agent1.sources = r1 agent1.sinks = k1 k2
#set gruop agent1.sinkgroups = g1 #set sink group agent1.sinkgroups.g1.sinks = k1 k2
#set channel agent1.channels.c1.type = memory agent1.channels.c1.capacity = 1000 agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1 agent1.sources.r1.type = exec agent1.sources.r1.command = tail -F /root/log/test.log
agent1.sources.r1.interceptors = i1 i2 agent1.sources.r1.interceptors.i1.type = static agent1.sources.r1.interceptors.i1.key = Type agent1.sources.r1.interceptors.i1.value = LOGIN agent1.sources.r1.interceptors.i2.type = timestamp
# set sink1 agent1.sinks.k1.channel = c1 agent1.sinks.k1.type = avro agent1.sinks.k1.hostname = itcast02 agent1.sinks.k1.port = 52020
# set sink2 agent1.sinks.k2.channel = c1 agent1.sinks.k2.type = avro agent1.sinks.k2.hostname = itcast03 agent1.sinks.k2.port = 52020
#set failover agent1.sinkgroups.g1.processor.type = failover agent1.sinkgroups.g1.processor.priority.k1 = 10 agent1.sinkgroups.g1.processor.priority.k2 = 5 agent1.sinkgroups.g1.processor.maxpenalty = 10000 #这里首先要申明一个sinkgroups,然后再设置2个sink ,k1与k2,其中2个优先级是10和5,#而processor的maxpenalty被设置为10秒,默认是30秒。‘ |
|
|
启动命令:
|
bin/flume-ng agent -n agent1 -c conf -f conf/flume-client.conf -Dflume.root.logger=DEBUG,console |
2、Itcast02和itcast03上的flume-server.conf配置
|
#set Agent name a1.sources = r1 a1.channels = c1 a1.sinks = k1
#set channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
# other node,nna to nns a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 52020 a1.sources.r1.channels = c1 a1.sources.r1.interceptors = i1 i2 a1.sources.r1.interceptors.i1.type = timestamp a1.sources.r1.interceptors.i2.type = host a1.sources.r1.interceptors.i2.hostHeader=hostname
#set sink to hdfs a1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.path=/data/flume/logs/%{hostname} a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.writeFormat=TEXT a1.sinks.k1.hdfs.rollInterval=10 a1.sinks.k1.channel=c1
|
启动命令:
|
bin/flume-ng agent -n agent1 -c conf -f conf/flume-server.conf -Dflume.root.logger=DEBUG,console |
(3)测试failover
1、先在itcast02和itcast03上启动脚本
|
bin/flume-ng agent -n a1 -c conf -f conf/flume-server.conf -Dflume.root.logger=DEBUG,console |
2、然后启动itcast01上的脚本
|
bin/flume-ng agent -n agent1 -c conf -f conf/flume-client.conf -Dflume.root.logger=DEBUG,console |
3、Shell脚本生成数据
|
while true;do date >> test.log; sleep 1s ;done |
4、观察HDFS上生成的数据目录。只观察到itcast02在接受数据

5、Itcast02上的agent被干掉之后,继续观察HDFS上生成的数据目录,itcast03对应的ip目录出现,此时数据收集切换到itcast03上

6、Itcast02上的agent重启后,继续观察HDFS上生成的数据目录。此时数据收集切换到itcast02上,又开始继续工作!

(二)、load balance负载均衡
(1)节点分配
如failover故障转移的节点分配
(2)配置
在failover故障转移的配置上稍作修改
itcast01上的flume-client-loadbalance.conf配置
|
#agent1 name agent1.channels = c1 agent1.sources = r1 agent1.sinks = k1 k2
#set gruop agent1.sinkgroups = g1
#set channel agent1.channels.c1.type = memory agent1.channels.c1.capacity = 1000 agent1.channels.c1.transactionCapacity = 100 agent1.sources.r1.channels = c1 agent1.sources.r1.type = exec agent1.sources.r1.command = tail -F /root/log/test.log
# set sink1 agent1.sinks.k1.channel = c1 agent1.sinks.k1.type = avro agent1.sinks.k1.hostname = itcast02 agent1.sinks.k1.port = 52020
# set sink2 agent1.sinks.k2.channel = c1 agent1.sinks.k2.type = avro agent1.sinks.k2.hostname = itcast03 agent1.sinks.k2.port = 52020
#set sink group agent1.sinkgroups.g1.sinks = k1 k2
#set load-balance agent1.sinkgroups.g1.processor.type = load_balance # 默认是round_robin,还可以选择random agent1.sinkgroups.g1.processor.selector = round_robin #如果backoff被开启,则 sink processor会屏蔽故障的sink agent1.sinkgroups.g1.processor.backoff = true
|
Itcast02和itcast03上的flume-server-loadbalance.conf配置
|
#set Agent name a1.sources = r1 a1.channels = c1 a1.sinks = k1
#set channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
# other node,nna to nns a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 52020 a1.sources.r1.channels = c1 a1.sources.r1.interceptors = i1 i2 a1.sources.r1.interceptors.i1.type = timestamp a1.sources.r1.interceptors.i2.type = host a1.sources.r1.interceptors.i2.hostHeader=hostname a1.sources.r1.interceptors.i2.useIP=false #set sink to hdfs a1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.path=/data/flume/loadbalance/%{hostname} a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.writeFormat=TEXT a1.sinks.k1.hdfs.rollInterval=10 a1.sinks.k1.channel=c1 a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d |
(3)测试load balance
1、先在itcast02和itcast03上启动脚本
|
bin/flume-ng agent -n a1 -c conf -f conf/flume-server-loadbalance.conf -Dflume.root.logger=DEBUG,console |
2、然后启动itcast01上的脚本
|
bin/flume-ng agent -n agent1 -c conf -f conf/flume-client-loadbalance.conf -Dflume.root.logger=DEBUG,console |
3、Shell脚本生成数据
|
while true;do date >> test.log; sleep 1s ;done |
4、观察HDFS上生成的数据目录,由于轮训机制都会收集到数据

5、Itcast02上的agent被干掉之后,itcast02上不在产生数据

6、Itcast02上的agent重新启动后,两者都可以接受到数据

1.2.3.5、Flume日志分类采集汇总
1. 案例场景
A、B两台日志服务机器实时生产日志主要类型为access.log、nginx.log、web.log
现在要求:
把A、B 机器中的access.log、nginx.log、web.log 采集汇总到C机器上然后统一收集到hdfs中。
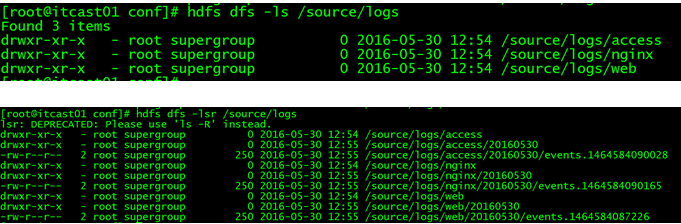
但是在hdfs中要求的目录为:
/source/logs/access/20160101/**
/source/logs/nginx/20160101/**
/source/logs/web/20160101/**
2. 场景分析
图一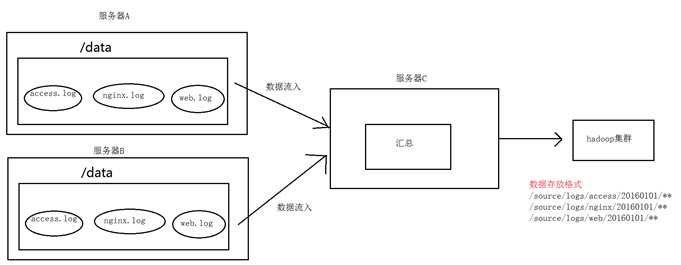
3. 数据流程处理分析
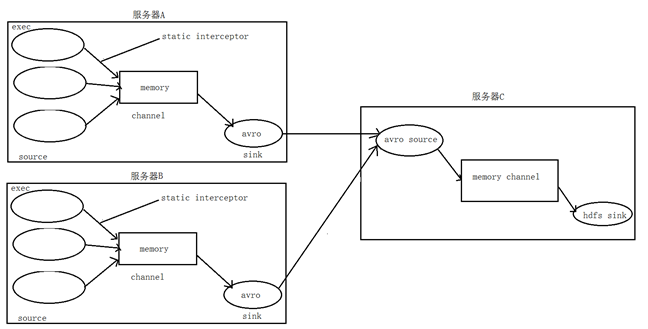
4. 实现
服务器A对应的IP为 192.168.200.102 服务器B对应的IP为 192.168.200.103 服务器C对应的IP为 192.168.200.101
① 在服务器A和服务器B上的$FLUME_HOME/conf 创建配置文件 exec_source_avro_sink.conf 文件内容为
# Name the components on this agent a1.sources = r1 r2 r3 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /root/data/access.log a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static ## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对 a1.sources.r1.interceptors.i1.key = type a1.sources.r1.interceptors.i1.value = access a1.sources.r2.type = exec a1.sources.r2.command = tail -F /root/data/nginx.log a1.sources.r2.interceptors = i2 a1.sources.r2.interceptors.i2.type = static a1.sources.r2.interceptors.i2.key = type a1.sources.r2.interceptors.i2.value = nginx a1.sources.r3.type = exec a1.sources.r3.command = tail -F /root/data/web.log a1.sources.r3.interceptors = i3 a1.sources.r3.interceptors.i3.type = static a1.sources.r3.interceptors.i3.key = type a1.sources.r3.interceptors.i3.value = web # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = 192.168.200.101 a1.sinks.k1.port = 41414 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 20000 a1.channels.c1.transactionCapacity = 10000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sources.r2.channels = c1 a1.sources.r3.channels = c1 a1.sinks.k1.channel = c1
② 在服务器C上的$FLUME_HOME/conf 创建配置文件 avro_source_hdfs_sink.conf 文件内容为
#定义agent名, source、channel、sink的名称 a1.sources = r1 a1.sinks = k1 a1.channels = c1 #定义source a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port =41414 #添加时间拦截器 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder #定义channels a1.channels.c1.type = memory a1.channels.c1.capacity = 20000 a1.channels.c1.transactionCapacity = 10000 #定义sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path=hdfs://192.168.200.101:9000/source/logs/%{type}/%Y%m%d a1.sinks.k1.hdfs.filePrefix =events a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.writeFormat = Text #时间类型 a1.sinks.k1.hdfs.useLocalTimeStamp = true #生成的文件不按条数生成 a1.sinks.k1.hdfs.rollCount = 0 #生成的文件按时间生成 a1.sinks.k1.hdfs.rollInterval = 30 #生成的文件按大小生成 a1.sinks.k1.hdfs.rollSize = 10485760 #批量写入hdfs的个数 a1.sinks.k1.hdfs.batchSize = 10000 flume操作hdfs的线程数(包括新建,写入等) a1.sinks.k1.hdfs.threadsPoolSize=10 #操作hdfs超时时间 a1.sinks.k1.hdfs.callTimeout=30000 #组装source、channel、sink a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
③ 配置完成之后,在服务器A和B上的/root/data有数据文件access.log、nginx.log、web.log。先启动服务器C上的flume,启动命令
在flume安装目录下执行 : bin/flume-ng agent -c conf -f conf/avro_source_hdfs_sink.conf -name a1 -Dflume.root.logger=DEBUG,console 然后在启动服务器上的A和B,启动命令 在flume安装目录下执行 : bin/flume-ng agent -c conf -f conf/exec_source_avro_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
5. 项目实现截图
1.2.3.6、Flume自定义拦截器
1. 背景介绍
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume有各种自带的拦截器,比如:TimestampInterceptor、HostInterceptor、RegexExtractorInterceptor等,通过使用不同的拦截器,实现不同的功能。但是以上的这些拦截器,不能改变原有日志数据的内容或者对日志信息添加一定的处理逻辑,当一条日志信息有几十个甚至上百个字段的时候,在传统的Flume处理下,收集到的日志还是会有对应这么多的字段,也不能对你想要的字段进行对应的处理。
2. 自定义拦截器
根据实际业务的需求,为了更好的满足数据在应用层的处理,通过自定义Flume拦截器,过滤掉不需要的字段,并对指定字段加密处理,将源数据进行预处理。减少了数据的传输量,降低了存储的开销。
13601249301 100 200 300 400 500 600 700 13601249302 100 200 300 400 500 600 700 13601249303 100 200 300 400 500 600 700 13601249304 100 200 300 400 500 600 700 13601249305 100 200 300 400 500 600 700 13601249306 100 200 300 400 500 600 700 13601249307 100 200 300 400 500 600 700 13601249308 100 200 300 400 500 600 700 13601249309 100 200 300 400 500 600 700 13601249310 100 200 300 400 500 600 700 13601249311 100 200 300 400 500 600 700 13601249312 100 200 300 400 500 600 700
3. 实现
本技术方案核心包括二部分:
① 编写java代码,自定义拦截器;
内容包括:
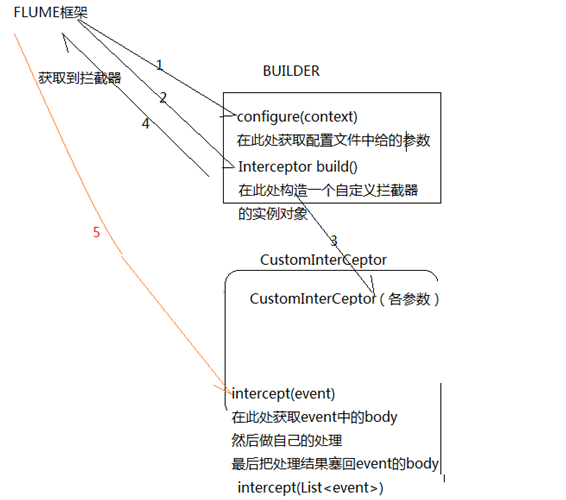
1. 定义一个类CustomParameterInterceptor实现Interceptor接口。
2. 在CustomParameterInterceptor类中定义变量,这些变量是需要到 Flume的配置文件中进行配置使用的。每一行字段间的分隔符(fields_separator)、通过分隔符分隔后,所需要列字段的下标(indexs)、多个下标使用的分隔符(indexs_separator)、多个下标使用的分隔符(indexs_separator)。
3. 添加CustomParameterInterceptor的有参构造方法。并对相应的变量进行处理。将配置文件中传过来的unicode编码进行转换为字符串。
4. 写具体的要处理的逻辑intercept()方法,一个是单个处理的,一个是批量处理。
5. 接口中定义了一个内部接口Builder,在configure方法中,进行一些参数配置。并给出,在flume的conf中没配置一些参数时,给出其默认值。通过其builder方法,返回一个CustomParameterInterceptor对象。
6. 定义一个静态类,类中封装MD5加密方法
7. 通过以上步骤,自定义拦截器的代码开发已完成,然后打包成jar, 放到Flume的根目录下的lib中
package cn.itcast.interceptor; import static cn.itcast.interceptor.CustomParameterInterceptor.Constants.FIELD_SEPARATOR; import static cn.itcast.interceptor.CustomParameterInterceptor.Constants.DEFAULT_FIELD_SEPARATOR; import static cn.itcast.interceptor.CustomParameterInterceptor.Constants.INDEXS; import static cn.itcast.interceptor.CustomParameterInterceptor.Constants.DEFAULT_INDEXS; import static cn.itcast.interceptor.CustomParameterInterceptor.Constants.INDEXS_SEPARATOR; import static cn.itcast.interceptor.CustomParameterInterceptor.Constants.DEFAULT_INDEXS_SEPARATOR; import static cn.itcast.interceptor.CustomParameterInterceptor.Constants.ENCRYPTED_FIELD_INDEX; import static cn.itcast.interceptor.CustomParameterInterceptor.Constants.DEFAULT_ENCRYPTED_FIELD_INDEX; import java.security.MessageDigest; import java.security.NoSuchAlgorithmException; import java.util.ArrayList; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interceptor; import com.google.common.base.Charsets; /** * @author lishas * */ public class CustomParameterInterceptor implements Interceptor{ /** The field_separator.指明每一行字段的分隔符 */ private final String fields_separator; /** The indexs.通过分隔符分割后,指明需要那列的字段 下标*/ private final String indexs; /** The indexs_separator. 多个下标的分隔符*/ private final String indexs_separator; /** The encrypted_field_index. 需要加密的字段下标*/ private final String encrypted_field_index; /** * * @param regex * @param field_separator * @param indexs * @param indexs_separator */ public CustomParameterInterceptor( String fields_separator, String indexs, String indexs_separator,String encrypted_field_index) { String f = fields_separator.trim(); String i = indexs_separator.trim(); this.indexs = indexs; this.encrypted_field_index=encrypted_field_index.trim(); if (!f.equals("")) { f = UnicodeToString(f); } this.fields_separator =f; if (!i.equals("")) { i = UnicodeToString(i); } this.indexs_separator = i; } /* * * \t 制表符 ('\u0009') \n 新行(换行)符 (' ') \r 回车符 (' ') \f 换页符 ('\u000C') \a 报警 * (bell) 符 ('\u0007') \e 转义符 ('\u001B') \cx 空格(\u0020)对应于 x 的控制符 * * @param str * @return * @data:2015-6-30 */ public static String UnicodeToString(String str) { Pattern pattern = Pattern.compile("(\\\\u(\\p{XDigit}{4}))"); Matcher matcher = pattern.matcher(str); char ch; while (matcher.find()) { ch = (char) Integer.parseInt(matcher.group(2), 16); str = str.replace(matcher.group(1), ch + ""); } return str; } /* * @see org.apache.flume.interceptor.Interceptor#intercept(org.apache.flume.Event) */ public Event intercept(Event event) { if (event == null) { return null; } try { String line = new String(event.getBody(), Charsets.UTF_8); String[] fields_spilts = line.split(fields_separator); String[] indexs_split = indexs.split(indexs_separator); String newLine=""; for (int i = 0; i < indexs_split.length; i++) { int parseInt = Integer.parseInt(indexs_split[i]); //对加密字段进行加密 if(!"".equals(encrypted_field_index)&&encrypted_field_index.equals(indexs_split[i])){ newLine+=StringUtils.GetMD5Code(fields_spilts[parseInt]); }else{ newLine+=fields_spilts[parseInt]; } if(i!=indexs_split.length-1){ newLine+=fields_separator; } } event.setBody(newLine.getBytes(Charsets.UTF_8)); return event; } catch (Exception e) { return event; } } /* * @see org.apache.flume.interceptor.Interceptor#intercept(java.util.List) */ public List<Event> intercept(List<Event> events) { List<Event> out = new ArrayList<Event>(); for (Event event : events) { Event outEvent = intercept(event); if (outEvent != null) { out.add(outEvent); } } return out; } /* * @see org.apache.flume.interceptor.Interceptor#initialize() */ public void initialize() { // TODO Auto-generated method stub } /* * @see org.apache.flume.interceptor.Interceptor#close() */ public void close() { // TODO Auto-generated method stub } public static class Builder implements Interceptor.Builder { /** The fields_separator.指明每一行字段的分隔符 */ private String fields_separator; /** The indexs.通过分隔符分割后,指明需要那列的字段 下标*/ private String indexs; /** The indexs_separator. 多个下标下标的分隔符*/ private String indexs_separator; /** The encrypted_field. 需要加密的字段下标*/ private String encrypted_field_index; /* * @see org.apache.flume.conf.Configurable#configure(org.apache.flume.Context) */ public void configure(Context context) { fields_separator = context.getString(FIELD_SEPARATOR, DEFAULT_FIELD_SEPARATOR); indexs = context.getString(INDEXS, DEFAULT_INDEXS); indexs_separator = context.getString(INDEXS_SEPARATOR, DEFAULT_INDEXS_SEPARATOR); encrypted_field_index= context.getString(ENCRYPTED_FIELD_INDEX, DEFAULT_ENCRYPTED_FIELD_INDEX); } /* * @see org.apache.flume.interceptor.Interceptor.Builder#build() */ public Interceptor build() { return new CustomParameterInterceptor(fields_separator, indexs, indexs_separator,encrypted_field_index); } } /** * The Class Constants. * * @author lishas */ public static class Constants { /** The Constant FIELD_SEPARATOR. */ public static final String FIELD_SEPARATOR = "fields_separator"; /** The Constant DEFAULT_FIELD_SEPARATOR. */ public static final String DEFAULT_FIELD_SEPARATOR =" "; /** The Constant INDEXS. */ public static final String INDEXS = "indexs"; /** The Constant DEFAULT_INDEXS. */ public static final String DEFAULT_INDEXS = "0"; /** The Constant INDEXS_SEPARATOR. */ public static final String INDEXS_SEPARATOR = "indexs_separator"; /** The Constant DEFAULT_INDEXS_SEPARATOR. */ public static final String DEFAULT_INDEXS_SEPARATOR = ","; /** The Constant ENCRYPTED_FIELD_INDEX. */ public static final String ENCRYPTED_FIELD_INDEX = "encrypted_field_index"; /** The Constant DEFAUL_TENCRYPTED_FIELD_INDEX. */ public static final String DEFAULT_ENCRYPTED_FIELD_INDEX = ""; /** The Constant PROCESSTIME. */ public static final String PROCESSTIME = "processTime"; /** The Constant PROCESSTIME. */ public static final String DEFAULT_PROCESSTIME = "a"; } /** * 字符串md5加密 */ public static class StringUtils { // 全局数组 private final static String[] strDigits = { "0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "a", "b", "c", "d", "e", "f" }; // 返回形式为数字跟字符串 private static String byteToArrayString(byte bByte) { int iRet = bByte; // System.out.println("iRet="+iRet); if (iRet < 0) { iRet += 256; } int iD1 = iRet / 16; int iD2 = iRet % 16; return strDigits[iD1] + strDigits[iD2]; } // 返回形式只为数字 private static String byteToNum(byte bByte) { int iRet = bByte; System.out.println("iRet1=" + iRet); if (iRet < 0) { iRet += 256; } return String.valueOf(iRet); } // 转换字节数组为16进制字串 private static String byteToString(byte[] bByte) { StringBuffer sBuffer = new StringBuffer(); for (int i = 0; i < bByte.length; i++) { sBuffer.append(byteToArrayString(bByte[i])); } return sBuffer.toString(); } public static String GetMD5Code(String strObj) { String resultString = null; try { resultString = new String(strObj); MessageDigest md = MessageDigest.getInstance("MD5"); // md.digest() 该函数返回值为存放哈希值结果的byte数组 resultString = byteToString(md.digest(strObj.getBytes())); } catch (NoSuchAlgorithmException ex) { ex.printStackTrace(); } return resultString; } } }
② 修改Flume的配置信息
新增配置文件spool-interceptor-hdfs.conf,内容为:
a1.channels = c1 a1.sources = r1 a1.sinks = s1 #channel a1.channels.c1.type = memory a1.channels.c1.capacity=100000 a1.channels.c1.transactionCapacity=50000 #source a1.sources.r1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/data/ a1.sources.r1.batchSize= 50 a1.sources.r1.inputCharset = UTF-8 a1.sources.r1.interceptors =i1 i2 a1.sources.r1.interceptors.i1.type =cn.itcast.interceptor.CustomParameterInterceptor$Builder a1.sources.r1.interceptors.i1.fields_separator=\\u0009 a1.sources.r1.interceptors.i1.indexs =0,1,3,5,6 a1.sources.r1.interceptors.i1.indexs_separator =\\u002c a1.sources.r1.interceptors.i1.encrypted_field_index =0 a1.sources.r1.interceptors.i2.type = timestamp #sink a1.sinks.s1.channel = c1 a1.sinks.s1.type = hdfs a1.sinks.s1.hdfs.path =hdfs://192.168.200.101:9000/flume/%Y%m%d a1.sinks.s1.hdfs.filePrefix = event a1.sinks.s1.hdfs.fileSuffix = .log a1.sinks.s1.hdfs.rollSize = 10485760 a1.sinks.s1.hdfs.rollInterval =20 a1.sinks.s1.hdfs.rollCount = 0 a1.sinks.s1.hdfs.batchSize = 1500 a1.sinks.s1.hdfs.round = true a1.sinks.s1.hdfs.roundUnit = minute a1.sinks.s1.hdfs.threadsPoolSize = 25 a1.sinks.s1.hdfs.useLocalTimeStamp = true a1.sinks.s1.hdfs.minBlockReplicas = 1 a1.sinks.s1.hdfs.fileType =DataStream a1.sinks.s1.hdfs.writeFormat = Text a1.sinks.s1.hdfs.callTimeout = 60000 a1.sinks.s1.hdfs.idleTimeout =60
启动:
bin/flume-ng agent -c conf -f conf/spool-interceptor-hdfs.conf -name a1 -Dflume.root.logger=DEBUG,console
5. 项目实现截图:


1.3、Flume实际使用时需要注意的事项
1) 注意启动脚本命令的书写
agent 的名称别写错了,后台执行加上nohup ... &
2) channel参数
capacity:默认该通道中最大的可以存储的event数量
trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量
keep-alive:event添加到通道中或者移出的允许时间
注意:capacity > trasactionCapacity
3) 日志采集到HDFS配置说明1(sink端)
#定义sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://192.168.200.101:9000/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
#时间类型
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件不按条数生成
a1.sinks.k1.hdfs.rollCount = 0
#生成的文件按时间生成
a1.sinks.k1.hdfs.rollInterval = 30
#生成的文件按大小生成
a1.sinks.k1.hdfs.rollSize = 10485760
#批量写入hdfs的个数
a1.sinks.k1.hdfs.batchSize = 10000
flume操作hdfs的线程数(包括新建,写入等)
a1.sinks.k1.hdfs.threadsPoolSize=10
#操作hdfs超时时间
a1.sinks.k1.hdfs.callTimeout=30000
4) 日志采集到HDFS配置说明2(sink端)
|
hdfs.round |
false |
Should the timestamp be rounded down (if true, affects all time based escape sequences except %t) |
|
hdfs.roundValue |
1 |
Rounded down to the highest multiple of this (in the unit configured usinghdfs.roundUnit), less than current time. |
|
hdfs.roundUnit |
second |
The unit of the round down value - second, minute or hour. |
- round: 默认值:false 是否启用时间上的”舍弃”,这里的”舍弃”,类似于”四舍五入”
- roundValue:默认值:1 时间上进行“舍弃”的值;
- roundUnit: 默认值:seconds时间上进行”舍弃”的单位,包含:second,minute,hour
案例(1):
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H:%M/%S
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
当时间为2015-10-16 17:38:59时候,hdfs.path依然会被解析为:
/flume/events/2015-10-16/17:30/00
/flume/events/2015-10-16/17:40/00
/flume/events/2015-10-16/17:50/00
因为设置的是舍弃10分钟内的时间,因此,该目录每10分钟新生成一个。
案例(2):
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H:%M/%S
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
现象:10秒为时间梯度生成对应的目录,目录下面包括很多小文件!!!
HDFS产生的数据目录格式如下:
/flume/events/2016-07-28/18:45/10
/flume/events/2016-07-28/18:45/20
/flume/events/2016-07-28/18:45/30
/flume/events/2016-07-28/18:45/40
/flume/events/2016-07-28/18:45/50
/flume/events/2016-07-28/18:46/10
/flume/events/2016-07-28/18:46/20
/flume/events/2016-07-28/18:46/30
/flume/events/2016-07-28/18:46/40
/flume/events/2016-07-28/18:46/50
5)日志采集使用tail -F 监控一个文件新增的内容(断点续传)
(详细见案例:flume的第6个配置案例-分类收集数据-使用static拦截器)
Source端的代码:
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /root/data/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx
这里会出现这样一个情况,当你的这个flume agent程序挂了或者是服务器宕机了,那么随着文件内容的增加,下次重启时,会消费到重复的数据, 怎么办呢?
解决方案:使用改进版的配置信息,修改信息
a1.sources.r2.command= tail -n +$(tail -n1 /root/log) -F /root/data/nginx.log | awk 'ARGIND==1{i=$0;next}{i++;if($0~/^tail/){i=0};print $0;print i >> "/root/log";fflush("")}' /root/log-
意思就是说:Source每次读取一条信息,就往/root/log文件记住当前消息的行数。这样的话当你的程序挂了之后,重启时先获取上次读取所在的行数,依次从下读,这样避免了数据重复。
而在flume1.7已经集成了该功能
配置文件:
|
配置案例: a1.channels = ch1 a1.sources = s1 a1.sinks = hdfs-sink1 #channel a1.channels.ch1.type = memory a1.channels.ch1.capacity=100000 a1.channels.ch1.transactionCapacity=50000 #source a1.sources.s1.channels = ch1 #监控一个目录下的多个文件新增的内容 a1.sources.s1.type = taildir #通过 json 格式存下每个文件消费的偏移量,避免从头消费 a1.sources.s1.positionFile = /var/local/apache-flume-1.7.0-bin/taildir_position.json a1.sources.s1.filegroups = f1 f2 f3 a1.sources.s1.filegroups.f1 = /root/data/access.log a1.sources.s1.filegroups.f2 = /root/data/nginx.log a1.sources.s1.filegroups.f3 = /root/data/web.log a1.sources.s1.headers.f1.headerKey = access a1.sources.s1.headers.f2.headerKey = nginx a1.sources.s1.headers.f3.headerKey = web a1.sources.s1.fileHeader = true ##sink a1.sinks.hdfs-sink1.channel = ch1 a1.sinks.hdfs-sink1.type = hdfs a1.sinks.hdfs-sink1.hdfs.path =hdfs://master:9000/demo/data a1.sinks.hdfs-sink1.hdfs.filePrefix = event_data a1.sinks.hdfs-sink1.hdfs.fileSuffix = .log a1.sinks.hdfs-sink1.hdfs.rollSize = 10485760 a1.sinks.hdfs-sink1.hdfs.rollInterval =20 a1.sinks.hdfs-sink1.hdfs.rollCount = 0 a1.sinks.hdfs-sink1.hdfs.batchSize = 1500 a1.sinks.hdfs-sink1.hdfs.round = true a1.sinks.hdfs-sink1.hdfs.roundUnit = minute a1.sinks.hdfs-sink1.hdfs.threadsPoolSize = 25 a1.sinks.hdfs-sink1.hdfs.useLocalTimeStamp = true a1.sinks.hdfs-sink1.hdfs.minBlockReplicas = 1 a1.sinks.hdfs-sink1.hdfs.fileType =DataStream a1.sinks.hdfs-sink1.hdfs.writeFormat = Text a1.sinks.hdfs-sink1.hdfs.callTimeout = 60000 |
6)flume的header参数配置讲解
|
#配置信息test-header.conf a1.channels = c1 a1.sources = r1 a1.sinks = k1 #channel a1.channels.c1.type = memory a1.channels.c1.capacity=100000 a1.channels.c1.transactionCapacity=50000 #source a1.sources.r1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /var/tmp a1.sources.r1.batchSize= 100 a1.sources.r1.inputCharset = UTF-8 a1.sources.r1.fileHeader = true a1.sources.r1.fileHeaderKey = mmm a1.sources.r1.basenameHeader = true a1.sources.r1.basenameHeaderKey = nnn #sink a1.sinks.k1.type = logger a1.sinks.k1.channel = c1 |
执行脚本:
bin/flume-ng agent -c conf -f conf/test-header.conf -name a1 -Dflume.root.logger=DEBUG,console
看到内容控制台打印的信息:
Event: { headers:{mmm=/var/tmp/bbb, nnn=bbb} body: 30 30 30 000 }
Event: { headers:{mmm=/var/tmp/aaa, nnn=aaa} body: 31 31 31 111 }
其中aaa bbb 为目录/var/tmp 下面的2个文件名称
官网描述:
2. 工作流调度器azkaban
2.1 概述
2.1.1为什么需要工作流调度系统
一个完整的数据分析系统通常都是由大量任务单元组成:shell脚本程序,java程序,mapreduce程序、hive脚本等
各任务单元之间存在时间先后及前后依赖关系
为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
例如,我们可能有这样一个需求,某个业务系统每天产生20G原始数据,我们每天都要对其进行处理,处理步骤如下所示:
1、 通过Hadoop先将原始数据同步到HDFS上;
2、 借助MapReduce计算框架对原始数据进行转换,生成的数据以分区表的形式存储到多张Hive表中;
3、 需要对Hive中多个表的数据进行JOIN处理,得到一个明细数据Hive大表;
4、 将明细数据进行复杂的统计分析,得到结果报表信息;
5、 需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
2.1.2 工作流调度实现方式
简单的任务调度:直接使用linux的crontab来定义;
复杂的任务调度:开发调度平台
或使用现成的开源调度系统,比如ooize、azkaban等
2.1.3 常见工作流调度系统
市面上目前有许多工作流调度器
在hadoop领域,常见的工作流调度器有Oozie, Azkaban,Cascading,Hamake等
2.1.4 各种调度工具特性对比
下面的表格对上述四种hadoop工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一致,但在设计理念,目标用户,应用场景等方面还是存在显著的区别,在做技术选型的时候,可以提供参考
|
特性 |
Hamake |
Oozie |
Azkaban |
Cascading |
|
工作流描述语言 |
XML |
XML (xPDL based) |
text file with key/value pairs |
Java API |
|
依赖机制 |
data-driven |
explicit |
explicit |
explicit |
|
是否要web容器 |
No |
Yes |
Yes |
No |
|
进度跟踪 |
console/log messages |
web page |
web page |
Java API |
|
Hadoop job调度支持 |
no |
yes |
yes |
yes |
|
运行模式 |
command line utility |
daemon |
daemon |
API |
|
Pig支持 |
yes |
yes |
yes |
yes |
|
事件通知 |
no |
no |
no |
yes |
|
需要安装 |
no |
yes |
yes |
no |
|
支持的hadoop版本 |
0.18+ |
0.20+ |
currently unknown |
0.18+ |
|
重试支持 |
no |
workflownode evel |
yes |
yes |
|
运行任意命令 |
yes |
yes |
yes |
yes |
|
Amazon EMR支持 |
yes |
no |
currently unknown |
yes |
2.1.5 Azkaban与Oozie对比
对市面上最流行的两种调度器,给出以下详细对比,以供技术选型参考。总体来说,ooize相比azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器azkaban是很不错的候选对象。
详情如下:
功能
两者均可以调度mapreduce,pig,java,脚本工作流任务
两者均可以定时执行工作流任务
工作流定义
Azkaban使用Properties文件定义工作流
Oozie使用XML文件定义工作流
工作流传参
Azkaban支持直接传参,例如${input}
Oozie支持参数和EL表达式,例如${fs:dirSize(myInputDir)}
定时执行
Azkaban的定时执行任务是基于时间的
Oozie的定时执行任务基于时间和输入数据
资源管理
Azkaban有较严格的权限控制,如用户对工作流进行读/写/执行等操作
Oozie暂无严格的权限控制
工作流执行
Azkaban有两种运行模式,分别是solo server mode(executor server和web server部署在同一台节点)和multi server mode(executor server和web server可以部署在不同节点)
Oozie作为工作流服务器运行,支持多用户和多工作流
工作流管理
Azkaban支持浏览器以及ajax方式操作工作流
Oozie支持命令行、HTTP REST、Java API、浏览器操作工作流
2.2 Azkaban介绍
Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
它有如下功能特点:
Web用户界面
方便上传工作流
方便设置任务之间的关系
调度工作流
认证/授权(权限的工作)
能够杀死并重新启动工作流
模块化和可插拔的插件机制
项目工作区
工作流和任务的日志记录和审计
2. 3 Azkaban安装部署
准备工作
Azkaban Web服务器
azkaban-web-server-2.5.0.tar.gz
Azkaban执行服务器
azkaban-executor-server-2.5.0.tar.gz
MySQL
目前azkaban只支持 mysql,需安装mysql服务器,本文档中默认已安装好mysql服务器,并建立了 root用户,密码 root.
下载地址:http://azkaban.github.io/downloads.html
安装
将安装文件上传到集群,最好上传到安装 hive、sqoop的机器上,方便命令的执行
在当前用户目录下新建 azkabantools目录,用于存放源安装文件.新建azkaban目录,用于存放azkaban运行程序
azkaban web服务器安装
解压azkaban-web-server-2.5.0.tar.gz
命令: tar –zxvf azkaban-web-server-2.5.0.tar.gz
将解压后的azkaban-web-server-2.5.0 移动到 azkaban目录中,并重新命名 webserver
命令: mv azkaban-web-server-2.5.0 ../azkaban
cd ../azkaban
mv azkaban-web-server-2.5.0 server
azkaban 执行服器安装
解压azkaban-executor-server-2.5.0.tar.gz
命令:tar –zxvf azkaban-executor-server-2.5.0.tar.gz
将解压后的azkaban-executor-server-2.5.0 移动到 azkaban目录中,并重新命名 executor
命令:mv azkaban-executor-server-2.5.0 ../azkaban
cd ../azkaban
mv azkaban-executor-server-2.5.0 executor
azkaban脚本导入
解压: azkaban-sql-script-2.5.0.tar.gz
命令:tar –zxvf azkaban-sql-script-2.5.0.tar.gz
将解压后的mysql 脚本,导入到mysql中:
进入mysql
mysql> create database azkaban;
mysql> use azkaban;
Database changed
mysql> source /home/hadoop/azkaban-2.5.0/create-all-sql-2.5.0.sql;
创建SSL配置
参考地址: http://docs.codehaus.org/display/JETTY/How+to+configure+SSL
命令: keytool -keystore keystore -alias jetty -genkey -keyalg RSA
运行此命令后,会提示输入当前生成 keystor的密码及相应信息,输入的密码请劳记,信息如下:
输入keystore密码:
再次输入新密码:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的州或省份名称是什么?
[Unknown]:
该单位的两字母国家代码是什么
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN 正确吗?
[否]: y
输入<jetty>的主密码
(如果和 keystore 密码相同,按回车):
再次输入新密码:
完成上述工作后,将在当前目录生成 keystore 证书文件,将keystore 考贝到 azkaban web服务器根目录中.如:cp keystore azkaban/webserver

配置文件

注:先配置好服务器节点上的时区
1、先生成时区配置文件Asia/Shanghai,用交互式命令 tzselect 即可

2、拷贝该时区文件,覆盖系统本地时区配置
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
azkaban web服务器配置
进入azkaban web服务器安装目录 conf目录
v 修改azkaban.properties文件
命令vi azkaban.properties
内容说明如下:
|
#Azkaban Personalization Settings azkaban.name=Test #服务器UI名称,用于服务器上方显示的名字 azkaban.label=My Local Azkaban #描述 azkaban.color=#FF3601 #UI颜色 azkaban.default.servlet.path=/index # web.resource.dir=web/ #默认根web目录 default.timezone.id=Asia/Shanghai #默认时区,已改为亚洲/上海 默认为美国
#Azkaban UserManager class user.manager.class=azkaban.user.XmlUserManager #用户权限管理默认类 user.manager.xml.file=conf/azkaban-users.xml #用户配置,具体配置参加下文
#Loader for projects executor.global.properties=conf/global.properties # global配置文件所在位置 azkaban.project.dir=projects #
database.type=mysql #数据库类型 mysql.port=3306 #端口号 mysql.host=hadoop03 #数据库连接IP mysql.database=azkaban #数据库实例名 mysql.user=root #数据库用户名 mysql.password=root #数据库密码 mysql.numconnections=100 #最大连接数
# Velocity dev mode velocity.dev.mode=false # Jetty服务器属性. jetty.maxThreads=25 #最大线程数 jetty.ssl.port=8443 #Jetty SSL端口 jetty.port=8081 #Jetty端口 jetty.keystore=keystore #SSL文件名 jetty.password=123456 #SSL文件密码 jetty.keypassword=123456 #Jetty主密码 与 keystore文件相同 jetty.truststore=keystore #SSL文件名 jetty.trustpassword=123456 # SSL文件密码
# 执行服务器属性 executor.port=12321 #执行服务器端口
# 邮件设置 mail.sender=xxxxxxxx@163.com #发送邮箱 mail.host=smtp.163.com #发送邮箱smtp地址 mail.user=xxxxxxxx #发送邮件时显示的名称 mail.password=********** #邮箱密码 job.failure.email=xxxxxxxx@163.com #任务失败时发送邮件的地址 job.success.email=xxxxxxxx@163.com #任务成功时发送邮件的地址 lockdown.create.projects=false # cache.directory=cache #缓存目录
|
azkaban 执行服务器配置
进入执行服务器安装目录conf,修改azkaban.properties
vi azkaban.properties
|
#Azkaban default.timezone.id=Asia/Shanghai #时区
# Azkaban JobTypes 插件配置 azkaban.jobtype.plugin.dir=plugins/jobtypes #jobtype 插件所在位置
#Loader for projects executor.global.properties=conf/global.properties azkaban.project.dir=projects
#数据库设置 database.type=mysql #数据库类型(目前只支持mysql) mysql.port=3306 #数据库端口号 mysql.host=192.168.20.200 #数据库IP地址 mysql.database=azkaban #数据库实例名 mysql.user=azkaban #数据库用户名 mysql.password=oracle #数据库密码 mysql.numconnections=100 #最大连接数
# 执行服务器配置 executor.maxThreads=50 #最大线程数 executor.port=12321 #端口号(如修改,请与web服务中一致) executor.flow.threads=30 #线程数 |
用户配置
进入azkaban web服务器conf目录,修改azkaban-users.xml
vi azkaban-users.xml 增加 管理员用户
|
<azkaban-users> <user username="azkaban" password="azkaban" roles="admin" groups="azkaban" /> <user username="metrics" password="metrics" roles="metrics"/> <user username="admin" password="admin" roles="admin,metrics" /> <role name="admin" permissions="ADMIN" /> <role name="metrics" permissions="METRICS"/> </azkaban-users> |
启动
web服务器
在azkaban web服务器目录下执行启动命令
bin/azkaban-web-start.sh
注:在web服务器根目录运行
执行服务器
在执行服务器目录下执行启动命令
bin/azkaban-executor-start.sh ./
注:只能要执行服务器根目录运行
启动完成后,在浏览器(建议使用谷歌浏览器)中输入https://服务器IP地址:8443 ,即可访问azkaban服务了.在登录中输入刚才新的户用名及密码,点击 login.
2.4.3 azkaban界面元素菜单说明
1、projects:azkaban最重要的一部分,创建一个工程,将所有的工作流放在工程中执行
2、scheduling:定时调度任务用的
3、executing: 显示当前运行的任务
4、History : 显示历史运行任务
一个project由3个按钮:
1、Flows:一个工作流,由多个job组成
2、Permissions:权限管理
3、Project Logs:工程日志信息
2.5 Azkaban实战
Azkaba内置的任务类型支持command、java
Command类型单一job示例
1、创建job描述文件
vi command.job
|
#command.job type=command command=echo 'hello' |
2、将job资源文件打包成zip文件
zip command.job
3、通过azkaban的web管理平台创建project并上传job压缩包
首先创建project
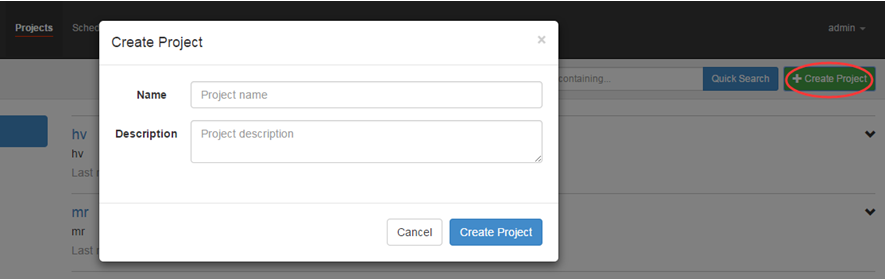
上传zip包

4、启动执行该job

Command类型多job工作流flow
1、创建有依赖关系的多个job描述
第一个job:foo.job
|
# foo.job type=command command=echo foo |
第二个job:bar.job依赖foo.job
|
# bar.job type=command dependencies=foo command=echo bar |
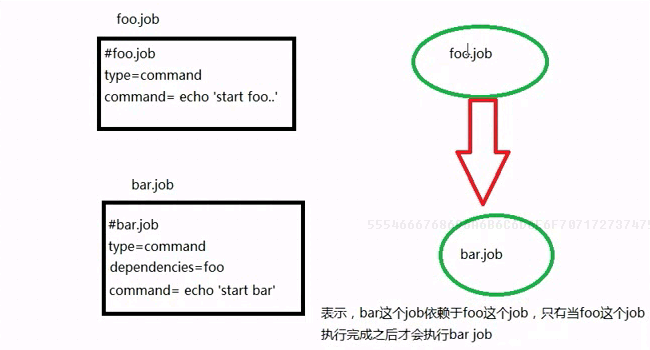
2、将所有job资源文件打到一个zip包中
3、在azkaban的web管理界面创建工程并上传zip包
4、启动工作流flow
HDFS操作任务
1、创建job描述文件
|
#fs.job type=command command=echo "start execute" command.1=/var/local/hadoop/bin/hadoop fs -mkdir /azkaban command.2=/var/local/hadoop/bin/hadoop fs -put /root/zk.log /azkaban |
command后面可以加上一个数字! 表现形式为command.N
表示可以执行多个command命令操作
2、将job资源文件打包成zip文件
3、通过azkaban的web管理平台创建project并上传job压缩包
4、启动集群,启动执行该job

MAPREDUCE任务
Mr任务依然可以使用command的job类型来执行
1、创建job描述文件,及mr程序jar包(示例中直接使用hadoop自带的example jar)
|
# mrwc.job type=command command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop jar hadoop-mapreduce-examples-2.6.1.jar wordcount /wordcount/input /wordcount/azout |
2、将所有job资源文件打到一个zip包中
3、在azkaban的web管理界面创建工程并上传zip包
4、启动yarm,启动job

HIVE脚本任务
l 创建job描述文件和hive脚本
Hive脚本: test.sql
|
use default; drop table aztest; create table aztest(id int,name string) row format delimited fields terminated by ','; load data inpath '/aztest/hiveinput' into table aztest; create table azres as select * from aztest; insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest; |
Job描述文件:hivef.job
|
# hivef.job type=command command=/home/hadoop/apps/hive/bin/hive -f 'test.sql' |
2、将所有job资源文件打到一个zip包中
3、在azkaban的web管理界面创建工程并上传zip包
4、启动job
3. sqoop数据迁移
3.1 概述
sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具。
导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;
导出数据:从Hadoop的文件系统中导出数据到关系数据库

3.2 工作机制
将导入或导出命令翻译成mapreduce程序来实现
在翻译出的mapreduce中主要是对inputformat和outputformat进行定制
3.3 sqoop实战及原理
3.3.1 sqoop安装
安装sqoop的前提是已经具备java和hadoop的环境
1、解压安装包

改名为sqoop
2、修改配置文件

$ cd $SQOOP_HOME/conf
$ mv sqoop-env-template.sh sqoop-env.sh
打开sqoop-env.sh并编辑下面几行:
export HADOOP_COMMON_HOME=/home/hadoop/apps/hadoop-2.6.1/
export HADOOP_MAPRED_HOME=/home/hadoop/apps/hadoop-2.6.1/
export HIVE_HOME=/home/hadoop/apps/hive-1.2.1
3、加入mysql的jdbc驱动包
cp ~/app/hive/lib/mysql-connector-java-5.1.28.jar $SQOOP_HOME/lib/
4、验证启动
$ cd $SQOOP_HOME/bin
$ sqoop-version
预期的输出:
15/12/17 14:52:32 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
Sqoop 1.4.6 git commit id 5b34accaca7de251fc91161733f906af2eddbe83
Compiled by abe on Fri Aug 1 11:19:26 PDT 2015
到这里,整个Sqoop安装工作完成。
3.4 Sqoop的数据导入
“导入工具”导入单个表从RDBMS到HDFS。表中的每一行被视为HDFS的记录。所有记录都存储为文本文件的文本数据(或者Avro、sequence文件等二进制数据)
3.4.1 语法
下面的语法用于将数据导入HDFS。
|
$ sqoop import (generic-args) (import-args) |
3.4.2 示例
表数据
在mysql中有一个库userdb中三个表:emp, emp_add和emp_contact
表emp:
|
id |
name |
deg |
salary |
dept |
|
1201 |
gopal |
manager |
50,000 |
TP |
|
1202 |
manisha |
Proof reader |
50,000 |
TP |
|
1203 |
khalil |
php dev |
30,000 |
AC |
|
1204 |
prasanth |
php dev |
30,000 |
AC |
|
1205 |
kranthi |
admin |
20,000 |
TP |
表emp_add:
|
id |
hno |
street |
city |
|
1201 |
288A |
vgiri |
jublee |
|
1202 |
108I |
aoc |
sec-bad |
|
1203 |
144Z |
pgutta |
hyd |
|
1204 |
78B |
old city |
sec-bad |
|
1205 |
720X |
hitec |
sec-bad |
表emp_conn:
|
id |
phno |
|
|
1201 |
2356742 |
gopal@tp.com |
|
1202 |
1661663 |
manisha@tp.com |
|
1203 |
8887776 |
khalil@ac.com |
|
1204 |
9988774 |
prasanth@ac.com |
|
1205 |
1231231 |
kranthi@tp.com |
导入表表数据到HDFS
下面的命令用于从MySQL数据库服务器中的emp表导入HDFS。
|
$bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --table emp --m 1 |
如果成功执行,那么会得到下面的输出。
|
14/12/22 15:24:54 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 14/12/22 15:24:56 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/cebe706d23ebb1fd99c1f063ad51ebd7/emp.jar ----------------------------------------------------- O mapreduce.Job: map 0% reduce 0% 14/12/22 15:28:08 INFO mapreduce.Job: map 100% reduce 0% 14/12/22 15:28:16 INFO mapreduce.Job: Job job_1419242001831_0001 completed successfully ----------------------------------------------------- ----------------------------------------------------- 14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Transferred 145 bytes in 177.5849 seconds (0.8165 bytes/sec) 14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Retrieved 5 records. |
为了验证在HDFS导入的数据,请使用以下命令查看导入的数据
|
$ $HADOOP_HOME/bin/hadoop fs -cat /user/hadoop/emp/part-m-00000 |
emp表的数据和字段之间用逗号(,)表示。
|
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP |
导入关系表到HIVE
|
bin/sqoop import --connect jdbc:mysql://hdp-node-01:3306/test --username root --password root --table emp --hive-import --m 1 |

案例二
|
sqoop import \ --connect jdbc:mysql://itcast01:3306/userdb \ --username root \ --password root123 \ --table emp_add \ --target-dir /emp_add_test \ --hive-table emp_add_test \ --hive-import --m 1
其本质:先将数据导入到HDFS上的/emp_add_test这个目录下面,然后将这个目录下的数据通过load data inpath ‘/emp_add_test’ into table emp_add_test 导入到hive表中,此时对应的数据目录被删除! |
导入到HDFS指定目录
在导入表数据到HDFS使用Sqoop导入工具,我们可以指定目标目录。
以下是指定目标目录选项的Sqoop导入命令的语法。
|
--target-dir <new or exist directory in HDFS> |
下面的命令是用来导入emp_add表数据到'/queryresult'目录。
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --target-dir /queryresult \ --table emp --m 1 |
下面的命令是用来验证 /queryresult 目录中 emp_add表导入的数据形式。
|
$HADOOP_HOME/bin/hadoop fs -cat /queryresult/part-m-* |
它会用逗号(,)分隔emp_add表的数据和字段。
|
1201, 288A, vgiri, jublee 1202, 108I, aoc, sec-bad 1203, 144Z, pgutta, hyd 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad |
导入表数据子集
我们可以导入表的使用Sqoop导入工具,"where"子句的一个子集。它执行在各自的数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。
where子句的语法如下。
|
--where <condition> |
下面的命令用来导入emp_add表数据的子集。子集查询检索员工ID和地址,居住城市为:Secunderabad
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --where "city ='sec-bad'" \ --target-dir /wherequery \ --table emp_add --m 1 |
按需导入
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --target-dir /wherequery2 \ --query 'select id,name,deg from emp WHERE id>1207 and $CONDITIONS' \ --split-by id \ --fields-terminated-by '\t' \ --m 1 |
下面的命令用来验证数据从emp_add表导入/wherequery目录
|
$HADOOP_HOME/bin/hadoop fs -cat /wherequery/part-m-* |
它用逗号(,)分隔 emp_add表数据和字段。
|
1202, 108I, aoc, sec-bad 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad |
增量导入
增量导入是仅导入新添加的表中的行的技术。
它需要添加‘incremental’, ‘check-column’, 和 ‘last-value’选项来执行增量导入。
下面的语法用于Sqoop导入命令增量选项。
|
--incremental <mode> --check-column <column name> --last value <last check column value>
|
假设新添加的数据转换成emp表如下:
1206, satish p, grp des, 20000, GR
下面的命令用于在EMP表执行增量导入。
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --table emp --m 1 \ --incremental append \ --check-column id \ --last-value 1205 |
以下命令用于从emp表导入HDFS emp/ 目录的数据验证。
|
$ $HADOOP_HOME/bin/hadoop fs -cat /user/hadoop/emp/part-m-* 它用逗号(,)分隔 emp_add表数据和字段。 1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR |
下面的命令是从表emp 用来查看修改或新添加的行
|
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*1 这表示新添加的行用逗号(,)分隔emp表的字段。 1206, satish p, grp des, 20000, GR |
3.5 Sqoop的数据导出
将数据从HDFS导出到RDBMS数据库
导出前,目标表必须存在于目标数据库中。
u 默认操作是从将文件中的数据使用INSERT语句插入到表中
u 更新模式下,是生成UPDATE语句更新表数据
语法
以下是export命令语法。
|
$ sqoop export (generic-args) (export-args) |
示例
数据是在HDFS 中“EMP/”目录的emp_data文件中。所述emp_data如下:
|
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR |
1、首先需要手动创建mysql中的目标表
|
$ mysql mysql> USE db; mysql> CREATE TABLE employee ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20), deg VARCHAR(20), salary INT, dept VARCHAR(10)); |
2、然后执行导出命令
|
bin/sqoop export \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --table emp2 \ --export-dir /user/hadoop/emp/ |
3、验证表mysql命令行。
|
mysql>select * from employee; 如果给定的数据存储成功,那么可以找到数据在如下的employee表。 +------+--------------+-------------+-------------------+--------+ | Id | Name | Designation | Salary | Dept | +------+--------------+-------------+-------------------+--------+ | 1201 | gopal | manager | 50000 | TP | | 1202 | manisha | preader | 50000 | TP | | 1203 | kalil | php dev | 30000 | AC | | 1204 | prasanth | php dev | 30000 | AC | | 1205 | kranthi | admin | 20000 | TP | | 1206 | satish p | grp des | 20000 | GR | +------+--------------+-------------+-------------------+--------+ |
3.6 Sqoop作业
注:Sqoop作业——将事先定义好的数据导入导出任务按照指定流程运行
语法
以下是创建Sqoop作业的语法。
|
$ sqoop job (generic-args) (job-args) [-- [subtool-name] (subtool-args)]
$ sqoop-job (generic-args) (job-args) [-- [subtool-name] (subtool-args)]
|
创建作业(--create)
在这里,我们创建一个名为myjob,这可以从RDBMS表的数据导入到HDFS作业。
|
bin/sqoop job --create myimportjob -- import --connect jdbc:mysql://hdp-node-01:3306/test --username root --password root --table emp --m 1 |
该命令创建了一个从db库的employee表导入到HDFS文件的作业。
验证作业 (--list)
‘--list’ 参数是用来验证保存的作业。下面的命令用来验证保存Sqoop作业的列表。
$ sqoop job --list
它显示了保存作业列表。
Available jobs:
myjob
检查作业(--show)
‘--show’ 参数用于检查或验证特定的工作,及其详细信息。以下命令和样本输出用来验证一个名为myjob的作业。
$ sqoop job --show myjob
它显示了工具和它们的选择,这是使用在myjob中作业情况。
|
Job: myjob Tool: import Options: ---------------------------- direct.import = true codegen.input.delimiters.record = 0 hdfs.append.dir = false db.table = employee ... incremental.last.value = 1206 ...
|
执行作业 (--exec)
‘--exec’ 选项用于执行保存的作业。下面的命令用于执行保存的作业称为myjob。
|
$ sqoop job --exec myjob 它会显示下面的输出。 10/08/19 13:08:45 INFO tool.CodeGenTool: Beginning code generation ... |
3.7 Sqoop的原理
概述
Sqoop的原理其实就是将导入导出命令转化为mapreduce程序来执行,sqoop在接收到命令后,都要生成mapreduce程序
使用sqoop的代码生成工具可以方便查看到sqoop所生成的java代码,并可在此基础之上进行深入定制开发
代码定制
以下是Sqoop代码生成命令的语法:
|
$ sqoop-codegen (generic-args) (codegen-args) $ sqoop-codegen (generic-args) (codegen-args) |
示例:以USERDB数据库中的表emp来生成Java代码为例。
下面的命令用来生成导入
|
$ sqoop-codegen \ --import --connect jdbc:mysql://localhost/userdb \ --username root \ --table emp |
如果命令成功执行,那么它就会产生如下的输出。
|
14/12/23 02:34:40 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 14/12/23 02:34:41 INFO tool.CodeGenTool: Beginning code generation ………………. 14/12/23 02:34:42 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop Note: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 14/12/23 02:34:47 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.jar |
验证: 查看输出目录下的文件
|
$ cd /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/ $ ls emp.class emp.jar emp.java
|
如果想做深入定制导出,则可修改上述代码文件
Source 到 Channel 到 Sink之间传递数据的形式是Event事件;Event事件是一个数据流单元。
sqoop详细教程
Apache Sqoop是用来实现结构型数据(如关系数据库)和Hadoop之间进行数据迁移的工具。它充分利用了MapReduce的并行特点以批处理的方式加快数据的传输,同时也借助MapReduce实现了容错。
项目地址: http://sqoop.apache.org/
目前为止,已经演化出了2个版本:sqoop1和sqoop2。
sqoop1的最新版本是1.4.5,sqoop2的最新版本是1.99.3;1.99.3和1.4.5是不兼容的,并且功能尚未开发完成,还不适合在生产环境部署。
sqoop支持的数据库:
|
Database |
version |
|
connect string matches |
|
HSQLDB |
1.8.0+ |
No |
|
|
MySQL |
5.0+ |
Yes |
|
|
Oracle |
10.2.0+ |
No |
|
|
PostgreSQL |
8.3+ |
Yes (import only) |
|
guojian@localtest:~/work$ sudo apt-get install sqoop
guojian@localtest:~/work$ sqoop help
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
See 'sqoop help COMMAND' for information on a specific command.
import是将关系数据库迁移到HDFS上
guojian@localtest:~/work$ sqoop import --connectjdbc:mysql://192.168.81.176/hivemeta2db --username root -password passwd --table sds
guojian@localtest:~/work$ hadoop fs -ls /user/guojian/sds
Found 5 items
-rw-r--r-- 3 guojian cug_test 0 2014-09-11 16:04 /user/guojian/sds/_SUCCESS
-rw-r--r-- 3 guojian cug_test 483 2014-09-11 16:03 /user/guojian/sds/part-m-00000.snappy
-rw-r--r-- 3 guojian cug_test 504 2014-09-11 16:04 /user/guojian/sds/part-m-00001.snappy
-rw-r--r-- 3 guojian cug_test 1001 2014-09-11 16:03 /user/guojian/sds/part-m-00002.snappy
-rw-r--r-- 3 guojian cug_test 952 2014-09-11 16:03 /user/guojian/sds/part-m-00003.snappy
可以通过--m设置并行数据,即map的数据,决定文件的个数。
默认目录是/user/${user.name}/${tablename},可以通过--target-dir设置hdfs上的目标目录。
如果想要将整个数据库中的表全部导入到hdfs上,可以使用import-all-tables命令。
sqoop import-all-tables –connect jdbc:mysql://192.168.81.176/hivemeta2db --username root -password passwd
如果想要指定所需的列,使用如下:
sqoop import --connect jdbc:mysql://192.168.81.176/hivemeta2db --username root -password passwd --table sds --columns "SD_ID,CD_ID,LOCATION"
指定导出文件为SequenceFiles,并且将生成的类文件命名为com.ctrip.sds:
sqoop import --connect jdbc:mysql://192.168.81.176/hivemeta2db --username root -password passwd --table sds --class-name com.ctrip.sds --as-sequencefile
导入文本时可以指定分隔符:
sqoop import --connect jdbc:mysql://192.168.81.176/hivemeta2db --username root -password passwd --table sds --fields-terminated-by '\t' --lines-terminated-by '\n' --optionally-enclosed-by '\"'
可以指定过滤条件:
sqoop import --connect jdbc:mysql://192.168.81.176/hivemeta2db --username root -password passwd --table sds --where "sd_id > 100"
export是import的反向过程,将hdfs上的数据导入到关系数据库中
sqoop export --connect jdbc:mysql://192.168.81.176/sqoop --username root -password passwd --table sds --export-dir /user/guojian/sds
上例中sqoop数据中的sds表需要先把表结构创建出来,否则export操作会直接失败。
由于sqoop是通过map完成数据的导入,各个map过程是独立的,没有事物的概念,可能会有部分map数据导入失败的情况。为了解决这一问题,sqoop中有一个折中的办法,即是指定中间 staging 表,成功后再由中间表导入到结果表。
这一功能是通过 --staging-table <staging-table-name> 指定,同时staging表结构也是需要提前创建出来的:
sqoop export --connect jdbc:mysql://192.168.81.176/sqoop --username root -password passwd --table sds --export-dir /user/guojian/sds --staging-table sds_tmp
需要说明的是,在使用 --direct , --update-key 或者--call存储过程的选项时,staging中间表是不可用的。
验证结果:
(1)数据会首先写到sds_tmp表,导入操作成功后,再由sds_tmp表导入到sds结果表中,同时会清除sds_tmp表。
(2)如果有map失败,则成功的map会将数据写入tmp表,export任务失败,同时tmp表的数据会被保留。
(3)如果tmp中已有数据,则此export操作会直接失败,可以使用 --clear-staging-table 指定在执行前清除中间表。
export选项:
|
|
直接使用 |
|
|
需要export的hdfs数据路径 |
|
|
并行export的map个数n |
|
|
导出到的目标表 |
|
|
调用存储过程 |
|
|
指定需要更新的列名,可以将数据库中已经存在的数据进行更新 |
|
|
更新模式,包括 |
|
前者只允许更新,后者允许新的列数据写入 |
|
|
|
The string to be interpreted as null for string columns |
|
|
The string to be interpreted as null for non-string columns |
|
|
指定中间staging表 |
|
|
执行export前将中间staging表数据清除 |
|
|
Use batch mode for underlying statement execution. |
|
Argument |
Description |
create-hive-table将关系数据库表导入到hive表中
|
参数 |
说明 |
|
–hive-home <dir> |
Hive的安装目录,可以通过该参数覆盖掉默认的hive目录 |
|
–hive-overwrite |
覆盖掉在hive表中已经存在的数据 |
|
–create-hive-table |
默认是false,如果目标表已经存在了,那么创建任务会失败 |
|
–hive-table |
后面接要创建的hive表 |
|
–table |
指定关系数据库表名 |
sqoop create-hive-table --connect jdbc:mysql://192.168.81.176/sqoop --username root -password passwd --table sds --hive-table sds_bak
默认sds_bak是在default数据库的。
这一步需要依赖HCatalog,需要先安装HCatalog,否则报如下错误:
Hive history file=/tmp/guojian/hive_job_log_cfbe2de9-a358-4130-945c-b97c0add649d_1628102887.txt
FAILED: ParseException line 1:44 mismatched input ')' expecting Identifier near '(' in column specification
list-databases列出一台server上可用的数据库
sqoop list-databases --connect jdbc:mysql://192.168.81.176/ --username root -password passwd
list-tables列出一个数据库中的表
sqoop list-tables --connect jdbc:mysql://192.168.81.176/sqoop --username root -password passwd
codegen:将关系数据库表映射为一个java文件、java class类、以及相关的jar包
sqoop codegen --connect jdbc:mysql://192.168.81.176/sqoop --username root -password passwd --table sds
Note: /tmp/sqoop-guojian/compile/d58f607b046a061593ba708ec5f3d608/sds.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
guojian@localtest:~/work$ ll /tmp/sqoop-guojian/compile/d58f607b046a061593ba708ec5f3d608/
total 48
drwxrwxr-x 2 guojian guojian 4096 9月 12 14:15 ./
drwxrwxr-x 11 guojian guojian 4096 9月 12 14:15 ../
-rw-rw-r-- 1 guojian guojian 11978 9月 12 14:15 sds.class
-rw-rw-r-- 1 guojian guojian 4811 9月 12 14:15 sds.jar
-rw-rw-r-- 1 guojian guojian 17525 9月 12 14:15 sds.java
merge是将两个数据集合并的工具,对于相同的key会覆盖老的值。
|
|
指定merge job使用的类名称 |
|
|
合并时引入的jar包,该jar包是通过Codegen工具生成的jar包 |
|
|
指定作为merge key的列名 |
|
|
指定newer数据目录 |
|
|
指定older数据目录 |
|
|
指定目标输出目录 |
|
参数 |
说明 |
sqoop merge --new-data /user/guojian/sds --onto /user/guojian/sqoop --target-dir /user/guojian/sds_new --jar-file sds.jar --class-name sds --merge-key SD_ID
值得注意的是,--target-dir如果设置为已经存在的目录,sqoop会报错退出。
eval用户可以很快的使用sql语句对数据库进行操作。这使得用户在执行import操作之前检查sql语句是否正确。
sqoop eval --connect jdbc:mysql://192.168.81.176/sqoop --username root -password passwd --query "SELECT SD_ID,CD_ID,LOCATION FROM sds LIMIT 10"
job用来生成sqoop任务。
|
|
创业一个新的sqoop作业. |
|
|
删除一个sqoop job |
|
|
执行一个 |
|
|
显示一个作业的参数 |
|
|
显示所有创建的sqoop作业 |
|
参数 |
说明 |
例子:
sqoop job --create myimportjob -- import --connectjdbc:mysql://192.168.81.176/hivemeta2db --username root -password passwd --table TBLS
guojian@localtest:~/work$ sqoop job --listAvailable jobs:
myimportjob
guojian@localtest:~/work$ sqoop job --show myimportjob
Job: myimportjob
Tool: import
Options:----------------------------
verbose = false
db.connect.string = jdbc:mysql://192.168.81.176/hivemeta2db
codegen.output.delimiters.escape = 0
codegen.output.delimiters.enclose.required = false
codegen.input.delimiters.field = 0
hbase.create.table = false
db.require.password = true
hdfs.append.dir = false
db.table = TBLS
import.fetch.size = null
accumulo.create.table = false
codegen.input.delimiters.escape = 0
codegen.input.delimiters.enclose.required = false
db.username = root
codegen.output.delimiters.record = 10
import.max.inline.lob.size = 16777216
hbase.bulk.load.enabled = false
hcatalog.create.table = false
db.clear.staging.table = false
codegen.input.delimiters.record = 0
enable.compression = false
hive.overwrite.table = false
hive.import = false
codegen.input.delimiters.enclose = 0
accumulo.batch.size = 10240000
hive.drop.delims = false
codegen.output.delimiters.enclose = 0
hdfs.delete-target.dir = false
codegen.output.dir = .
codegen.auto.compile.dir = true
mapreduce.num.mappers = 4
accumulo.max.latency = 5000
import.direct.split.size = 0
codegen.output.delimiters.field = 44
export.new.update = UpdateOnly
incremental.mode = None
hdfs.file.format = TextFile
codegen.compile.dir = /tmp/sqoop-guojian/compile/bd9c7f7b651276067b3f7b341b7fa4cb
direct.import = false
hive.fail.table.exists = false
db.batch = false
执行:
sqoop job -exec myimportjob
metastore 配置sqoop job的共享元数据信息,这样多个用户定义和执行sqoop job在这一 metastore中。默认存储在~/.sqoop
启动:sqoop metastore
关闭:sqoop metastore --shutdown
metastore文件的存储位置是在 conf/sqoop-site.xml中sqoop.metastore.server.location 配置,指向本地文件。
metastore可以通过TCP/IP访问,端口号可以通过sqoop.metastore.server.port 配置,默认是16000。
客户端可以通过 指定 sqoop.metastore.client.autoconnect.url 或使用 --meta-connect ,配置为 jdbc:hsqldb:hsql://<server-name>:<port>/sqoop,例如 jdbc:hsqldb:hsql://metaserver.example.com:16000/sqoop 。
更多说明见 http://sqoop.apache.org/docs/1.4.5/SqoopUserGuide.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号