
Hadoop
HADOOP是apache旗下的一套开源软件平台
HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
HADOOP的核心组件有
- HDFS(分布式文件系统)
- YARN(运算资源调度系统)
- MAPREDUCE(分布式运算编程框架)
Hdfs模拟实现思路:
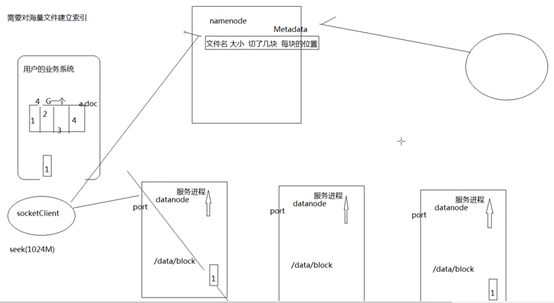
Mapreduce模拟实现思路:
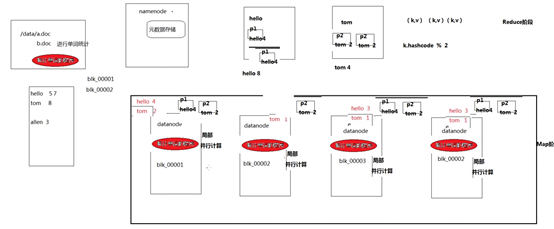
Yarn:
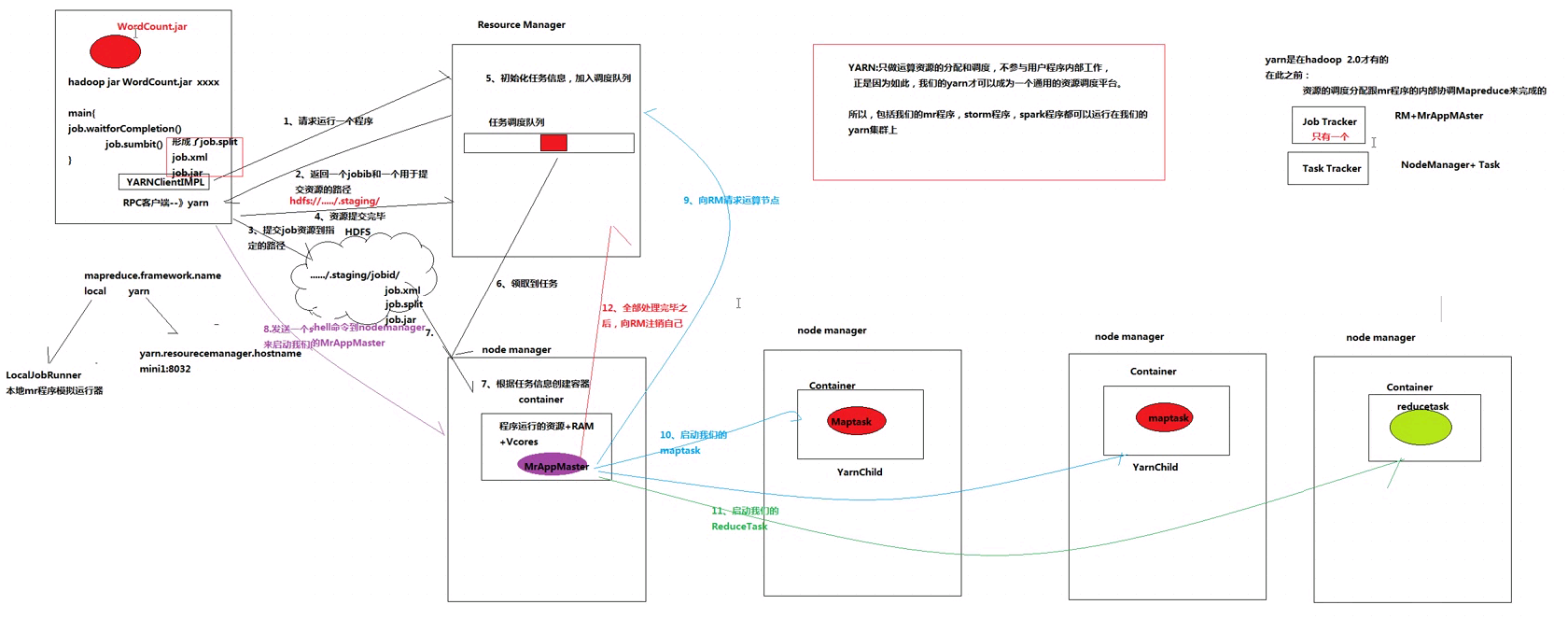

HADOOP在大数据、云计算中的位置和关系
- 云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
- 现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
- 而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
国内外HADOOP应用案例介绍
1、HADOOP应用于数据服务基础平台建设
2、HADOOP用于用户画像
3、HADOOP用于网站点击流日志数据挖掘
- 金融行业: 个人征信分析
- 证券行业: 投资模型分析
- 交通行业: 车辆、路况监控分析
- 电信行业:用户上网行为分析
......
总之:hadoop并不会跟某种具体的行业或者某个具体的业务挂钩,它只是一种用来做海量数据分析处理的工具
就HADOOP而言,通常都需要具备以下技能或知识:
- HADOOP分布式集群的平台搭建
- HADOOP分布式文件系统HDFS的原理理解及使用
- HADOOP分布式运算框架MAPREDUCE的原理理解及编程
- Hive数据仓库工具的熟练应用:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
- Flume、sqoop、oozie等辅助工具的熟练使用:Oozie:工作流调度框架;Sqoop:数据导入导出工具;Flume:日志数据采集框架
- Shell/python等脚本语言的开发能力
- HBASE:基于HADOOP的分布式海量数据库
- ZOOKEEPER:分布式协调服务基础组件
- Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
分布式软件系统(Distributed Software Systems)
- 该软件系统会划分成多个子系统或模块,各自运行在不同的机器上,子系统或模块之间通过网络通信进行协作,实现最终的整体功能
- 比如分布式操作系统、分布式程序设计语言及其编译(解释)系统、分布式文件系统和分布式数据库系统等。
- 利用多个节点共同协作完成一项或多项具体业务功能的系统就是分布式系统。
数据处理流程
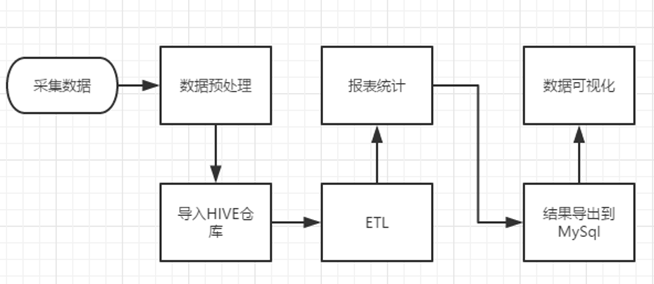
1) 数据采集:定制开发采集程序,或使用开源框架FLUME
2) 数据预处理:定制开发mapreduce程序运行于hadoop集群
3) 数据仓库技术:基于hadoop之上的Hive
4) 数据导出:基于hadoop的sqoop数据导入导出工具
5) 数据可视化:定制开发web程序或使用kettle等产品
6) 整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
精准广告推送平台系统:
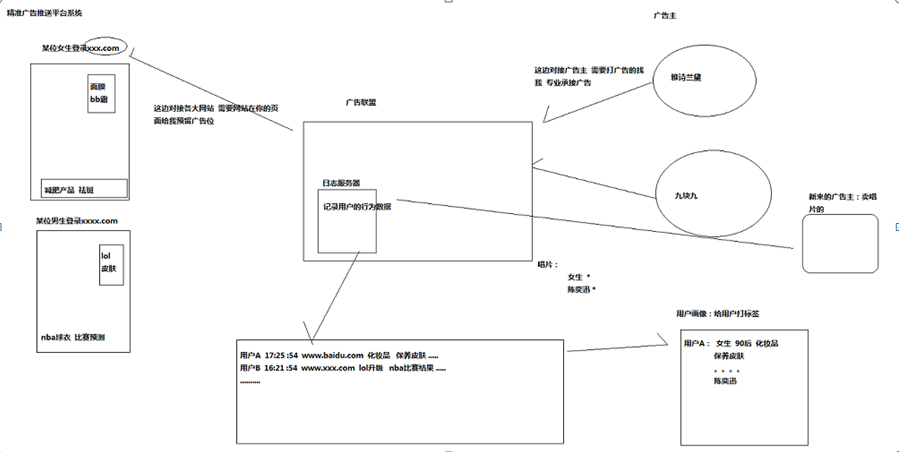
HADOOP集群搭建
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包)
本集群搭建案例,以5节点为例进行搭建,角色分配如下:

1.准备Linux环境
- 先将虚拟机的网络模式选为NAT
- 修改主机名vi /etc/hostname
- 修改IP :vim /etc/sysconfig/network-scripts/ifcfg-eth33
DEVICE="eth33" BOOTPROTO="static" ### HWADDR="00:0C:29:3C:BF:E7" IPV6INIT="yes" NM_CONTROLLED="yes" ONBOOT="yes" TYPE="Ethernet" UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c" IPADDR="192.168.1.101" ### NETMASK="255.255.255.0" ### GATEWAY="192.168.1.1" ###
- 修改主机名和IP的映射关系 vim /etc/hosts
192.168.126.13 mini1 192.168.126.14 mini2 192.168.126.15 mini3
发送到其他机器:
[root@mini1 etc]# scp -r /etc/hosts root@192.168.126.15:/etc/
- 关闭防火墙
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
- 重启Linux:reboot
- 配置ssh免登陆
#生成ssh免登陆密钥
#进入到我的home目录
cd ~/.ssh
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上
[root@mini1 ~]# ssh-copy-id root@mini2
[root@mini1 ~]# ssh-copy-id root@mini3
[root@mini1 ~]# ssh-copy-id root@mini1
5.远程控制机器:
[root@mini3 ~]# ssh mini1
退出:exit
安装JDK
- 上传alt+p 后出现sftp窗口,然后put d:\xxx\yy\ll\jdk-7u_65-i585.tar.gz
- 解压jdk
#创建文件夹 mkdir /root/apps #解压 tar -zxvf jdk-7u55-linux-i586.tar.gz -C /root/apps
- 将java添加到环境变量中:vim /etc/profile
#在文件最后添加 export JAVA_HOME=/root/apps/jdk-7u_65-i585 export PATH=$PATH:$JAVA_HOME/bin #刷新配置 source /etc/profile
安装hadoop
先上传hadoop的安装包到服务器上去/root/apps/
注意:hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
伪分布式需要修改5个配置文件
配置hadoop
/root/apps/hadoop/etc/hadoop/ 目录下
第一个:hadoop-env.sh
vim hadoop-env.sh #第27行 export JAVA_HOME=/root/apps/jdk1.7.0_80
第二个:core-site.xml
<configuration> <!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://mini1:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/root/apps/hadoop/tmp</value> </property> </configuration>
第三个:hdfs-site.xml
<!-- 指定HDFS副本的数量 --> <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.secondary.http.address</name> <value>mini1:50090</value> </property> </configuration>
第四个:mapred-site.xml (mv mapred-site.xml.template mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
第五个:yarn-site.xml
<configuration> <!-- 指定YARN的老大(ResourceManager)的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>mini1</value> </property> <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
将hadoop添加到环境变量
vim /etc/proflie export JAVA_HOME=/root/apps/jdk1.7.0_80 export HADOOP_HOME=/root/apps/hadoop export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
把文件拷贝到其他机器:
[root@mini1 hadoop]# scp -r /root/apps/hadoop/ root@mini2:/root/apps/
[root@mini1 hadoop]# scp -r /root/apps/hadoop/ root@mini3:/root/apps/
[root@mini1 hadoop]# scp -r /etc/profile root@mini2:/etc/
[root@mini1 hadoop]# scp -r /etc/profile root@mini3:/etc/
对所有机器:source /etc/profile
格式化namenode(是对namenode进行初始化)
hdfs namenode -format (hadoop namenode -format)
启动hadoop
启动单个:
启动单个:hadoop-daemon.sh start namenode [root@mini1 hadoop]# hadoop-daemon.sh start secondarynamenode [root@mini1 hadoop]# hadoop-daemon.sh start datanode [root@mini2 hadoop]# hadoop-daemon.sh start datanode [root@mini3 apps]# hadoop-daemon.sh start datanode 访问192.168.126.13:50070 (要关闭防火墙)
多个一起启动HDFS
vi slaves 添加: mini1 mini2 mini3 [root@mini1 hadoop]# scp -r slaves root@mini2:/root/apps/hadoop/etc/hadoop/ [root@mini1 hadoop]# scp -r slaves root@mini3:/root/apps/hadoop/etc/hadoop/ start-dfs.sh 再启动YARN sbin/start-yarn.sh
验证是否启动成功
使用jps命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
http://192.168.126.13:50070 (HDFS管理界面)
http://192.168.126.13:8088 (MR管理界面)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号