

正则表达式

1 基础
正则表达式就是以某种方式来描述字符串。
-? 表示可能有一个或0个负号在最前面
\d 表示一个整数,在Java中对反斜线有不同处理,所有应该是“\\d”
+ 表示一个或多个之前的表达式
-?\\d+ 表示“可能有一个负号,后面跟着一位或多位数字”
public static void main(String args[]){ System.out.println("-1234".matches("-?\\d+"));//true System.out.println("1234".matches("-?\\d+"));//true System.out.println("+1234".matches("-?\\d+"));//false System.out.println("+1234".matches("(-|\\+)?\\d+"));//true "+"在正则表达式里面有特殊意义,也要用\\将其转义 }
String类还自带了一个非常有用的正则表达式工具----split(),其功能是“将字符串从正则表达式匹配的地方切开”
\W 表示非单词字符,如果W小写,则表示一个单词。
import java.util.*; public class Splitting { public static String knights = "Then, when you have found the shrubbery, you must " + "cut down the mightiest tree in the forest... " + "with... a herring!"; public static void split(String regex) { System.out.println( Arrays.toString(knights.split(regex))); } public static void main(String[] args) { split(" "); // Doesn't have to contain regex chars split("\\W+"); // Non-word characters split("n\\W+"); // 'n' followed by non-word characters 字母n后面跟着一个或多个非单词字符 } } /* Output: [Then,, when, you, have, found, the, shrubbery,, you, must, cut, down, the, mightiest, tree, in, the, forest..., with..., a, herring!] [Then, when, you, have, found, the, shrubbery, you, must, cut, down, the, mightiest, tree, in, the, forest, with, a, herring] [The, whe, you have found the shrubbery, you must cut dow, the mightiest tree i, the forest... with... a herring!] *///:~
String.split()还有一个重载的版本,它允许你限制字符串分割的次数
String类自带的最后一个正则表达式工具是“替换”,你可以只替换正则表达式第一个匹配的子串,或是替换所有匹配的地方
import static net.mindview.util.Print.*; public class Replacing { static String s = Splitting.knights; public static void main(String[] args) { print(s.replaceFirst("f\\w+", "located")); print(s.replaceAll("shrubbery|tree|herring","banana")); } } /* Output: Then, when you have located the shrubbery, you must cut down the mightiest tree in the forest... with... a herring! Then, when you have found the banana, you must cut down the mightiest banana in the forest... with... a banana! *///:~
创建正则表达式
正则表达式的完整构造自列表,参考JDK文档java.util.regex包中的Pattern类





量词


CharSequence


Pattern和Matcher

给args赋值:{Args: abcabcabcdefabc "abc+" "(abc)+" "(abc){2,}" }
//: strings/TestRegularExpression.java // Allows you to easily try out regular expressions. // {Args: abcabcabcdefabc "abc+" "(abc)+" "(abc){2,}" } import java.util.regex.*; import static net.mindview.util.Print.*; public class TestRegularExpression { public static void main(String[] args) { if(args.length < 2) { print("Usage:\njava TestRegularExpression " + "characterSequence regularExpression+"); System.exit(0); } print("Input: \"" + args[0] + "\""); for(String arg : args) { print("Regular expression: \"" + arg + "\""); Pattern p = Pattern.compile(arg); Matcher m = p.matcher(args[0]);//在args[0]中查找与正则表达式p匹配的字符串 while(m.find()) { print("Match \"" + m.group() + "\" at positions " + m.start() + "-" + (m.end() - 1)); } } } } /* Output: Input: "abcabcabcdefabc" Regular expression: "abcabcabcdefabc" Match "abcabcabcdefabc" at positions 0-14 Regular expression: "abc+" Match "abc" at positions 0-2 Match "abc" at positions 3-5 Match "abc" at positions 6-8 Match "abc" at positions 12-14 Regular expression: "(abc)+" Match "abcabcabc" at positions 0-8 Match "abc" at positions 12-14 Regular expression: "(abc){2,}" Match "abcabcabc" at positions 0-8 *///:~
Pattern类还提供了static方法

String str="Java now has regular expressions"; Pattern p1=Pattern.compile("^Java"); Pattern p2=Pattern.compile("n.w\\s+h(a|i)s"); // Pattern p=Pattern.compile("s+");//s?:一次或0次 s*:0次或多次 s+:一次或多次 //s{4}:恰好4次 s{1,}:至少一次 s{0,3}:至少0次,不超過3次 System.out.println(p1.matcher(str).lookingAt()); System.out.println(p2.matcher(str).find());

import java.util.regex.*; import static net.mindview.util.Print.*; public class Finding { public static void main(String[] args) { Matcher m = Pattern.compile("\\w+") .matcher("Evening is full of the linnet's wings"); while(m.find()) printnb(m.group() + " "); print(); int i = 0; while(m.find(i)) { printnb(m.group() + " "); i++; } } } /* Output: Evening is full of the linnet s wings Evening vening ening ning ing ng g is is s full full ull ll l of of f the the he e linnet linnet innet nnet net et t s s wings wings ings ngs gs s *///:~

import java.util.regex.*; import static net.mindview.util.Print.*; public class Groups { static public final String POEM = "Twas brillig, and the slithy toves\n" + "Did gyre and gimble in the wabe.\n" + "All mimsy were the borogoves,\n" + "And the mome raths outgrabe.\n\n" + "Beware the Jabberwock, my son,\n" + "The jaws that bite, the claws that catch.\n" + "Beware the Jubjub bird, and shun\n" + "The frumious Bandersnatch."; public static void main(String[] args) { Matcher m = Pattern.compile("(?m)(\\S+)\\s+((\\S+)\\s+(\\S+))$") .matcher(POEM); while(m.find()) { for(int j = 0; j <= m.groupCount(); j++) printnb("[" + m.group(j) + "]"); print(); } } } /* Output: [the slithy toves][the][slithy toves][slithy][toves] [in the wabe.][in][the wabe.][the][wabe.] [were the borogoves,][were][the borogoves,][the][borogoves,] [mome raths outgrabe.][mome][raths outgrabe.][raths][outgrabe.] [Jabberwock, my son,][Jabberwock,][my son,][my][son,] [claws that catch.][claws][that catch.][that][catch.] [bird, and shun][bird,][and shun][and][shun] [The frumious Bandersnatch.][The][frumious Bandersnatch.][frumious][Bandersnatch.] *///:~
这个正则表达式模式有许多圆括号分组,有任意数目的非空格字符及随后的任意数目的空格字符所组成。目的是捕获每行的最后3个词,每行最后以$结束。不过,在正常情况下是将$与整个输入序列的末端相匹配。所以我们一定要显式地告知正则表达式注意输入序列中的换行符。这可以有序列开头的模式标记(?m)来完成

package regex; import java.util.regex.*; public class StartEnd { public static String input = "As long as there is injustice, whenever a\n" + "Targathian baby cries out, wherever a distress\n" + "signal sounds among the stars ... We'll be there.\n" + "This fine ship, and this fine crew ...\n" + "Never give up! Never surrender!"; private static class Display { private boolean regexPrinted = false; private String regex; Display(String regex) { this.regex = regex; } void display(String message) { if(!regexPrinted) { System.out.println(regex); regexPrinted = true; } System.out.println(message); } } static void examine(String s, String regex) { Display d = new Display(regex); Pattern p = Pattern.compile(regex); Matcher m = p.matcher(s); while(m.find()) d.display("find() '" + m.group() + "' start = "+ m.start() + " end = " + m.end()); if(m.lookingAt()) // No reset() necessary d.display("lookingAt() start = " + m.start() + " end = " + m.end()); if(m.matches()) // No reset() necessary d.display("matches() start = " + m.start() + " end = " + m.end()); } public static void main(String[] args) { for(String in : input.split("\n")) { System.out.println("input : " + in); for(String regex : new String[]{"\\w*ere\\w*", "\\w*ever", "T\\w+", "Never.*?!"}) examine(in, regex); } } }
input : As long as there is injustice, whenever a
\w*ere\w*
find() 'there' start = 11 end = 16
\w*ever
find() 'whenever' start = 31 end = 39
input : Targathian baby cries out, wherever a distress
\w*ere\w*
find() 'wherever' start = 27 end = 35
\w*ever
find() 'wherever' start = 27 end = 35
T\w+
find() 'Targathian' start = 0 end = 10
lookingAt() start = 0 end = 10
input : signal sounds among the stars ... We'll be there.
\w*ere\w*
find() 'there' start = 43 end = 48
input : This fine ship, and this fine crew ...
T\w+
find() 'This' start = 0 end = 4
lookingAt() start = 0 end = 4
input : Never give up! Never surrender!
\w*ever
find() 'Never' start = 0 end = 5
find() 'Never' start = 15 end = 20
lookingAt() start = 0 end = 5
Never.*?!
find() 'Never give up!' start = 0 end = 14
find() 'Never surrender!' start = 15 end = 31
lookingAt() start = 0 end = 14
matches() start = 0 end = 31
*///:~

split

String input = "This!!unusual use!!of exclamation!!points"; System.out.println(Arrays.toString(Pattern.compile("!!").split(input))); // Only do the first three: System.out.println(Arrays.toString(Pattern.compile("!!").split(input, 3)));
运用


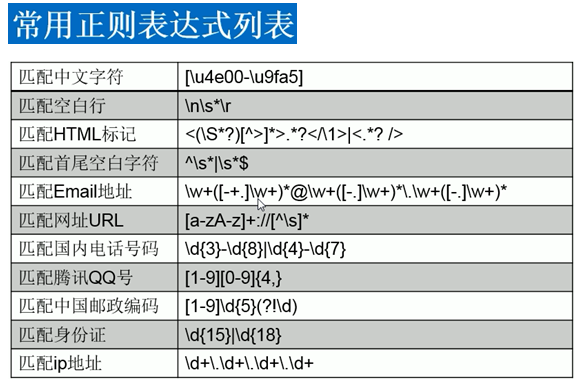
/** * 测试正则表达式对象的基本用法 * * @author Administrator * */ public class Demo01 { public static void main(String[] args) { // 在这个字符串:asfsdf23323,是否符合指定的正则表达式:\w+ // 表达式对象 Pattern p = Pattern.compile("\\w+"); // 创建Matcher对象 Matcher m = p.matcher("asfsdf2&&3323"); // boolean yesorno = m.matches(); //尝试将整个字符序列与该模式匹配 // System.out.println(yesorno); // boolean yesorno2 = m.find(); //该方法扫描输入的序列,查找与该模式匹配的下一个子序列 // System.out.println(yesorno2); // System.out.println(m.find()); // System.out.println(m.group()); // System.out.println(m.find()); // System.out.println(m.group()); while (m.find()) { System.out.println(m.group()); // group(),group(0)匹配整个表达式的子字符串 System.out.println(m.group(0)); } } } /** * 测试正则表达式对象中分组的处理 * * @author Administrator * */ public class Demo02 { public static void main(String[] args) { // 在这个字符串:asfsdf23323,是否符合指定的正则表达式:\w+ // 表达式对象 Pattern p = Pattern.compile("([a-z]+)([0-9]+)"); // 创建Matcher对象 Matcher m = p.matcher("aa232**ssd445*sds223"); while (m.find()) { // group(),group(0)匹配整个表达式的子字符串 System.out.println(m.group()); System.out.println(m.group(1)); System.out.println(m.group(2)); } } } /** * 测试正则表达式对象的替换操作 */ public class Demo03 { public static void main(String[] args) { // 表达式对象 Pattern p = Pattern.compile("[0-9]"); // 创建Matcher对象 Matcher m = p.matcher("aa232**ssd445*sds223"); // 替换 String newStr = m.replaceAll("#"); System.out.println(newStr); } } /** * 测试正则表达式对象的分割字符串的操作 */ public class Demo04 { public static void main(String[] args) { String str = "a232b4334c3434"; String[] arrs = str.split("\\d+"); System.out.println(Arrays.toString(arrs)); } } /** * 网络爬虫取链接 */ public class WebSpiderTest { /** * 获得urlStr对应的网页的源码内容 */ public static String getURLContent(String urlStr, String charset) { StringBuilder sb = new StringBuilder(); try { URL url = new URL(urlStr); BufferedReader reader = new BufferedReader( new InputStreamReader(url.openStream(), Charset.forName(charset))); String temp = ""; while ((temp = reader.readLine()) != null) { sb.append(temp); } } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return sb.toString(); } public static List<String> getMatherSubstrs(String destStr, String regexStr) { Pattern p = Pattern.compile(regexStr); // 取到的超链接的地址 Matcher m = p.matcher(destStr); List<String> result = new ArrayList<String>(); while (m.find()) { result.add(m.group(1)); } return result; } public static void main(String[] args) { String destStr = getURLContent("http://www.163.com", "gbk"); // Pattern p = Pattern.compile("<a[\\s\\S]+?</a>"); //取到的超链接的整个内容 List<String> result = getMatherSubstrs(destStr, "href=\"([\\w\\s./:]+?)\""); for (String temp : result) { System.out.println(temp); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号