
Java-集合-八股文
- list、set
- arraylist、linkedlist
- concurrenthashmap扩容机理
- JDK版本变迁,hashmap的主要变更
- hashmap的put方法
- hashmap的get方法
- hashmap扩容机理
- copyonwriteArrayList
- concurrentHashMap为什么不能存储Null
- arraylist的扩容机制
- 为什么hashmap会出现死循环
- 为什么链表转红黑树的阈值是8,而红黑树转链表的阈值是6
- arraylist的fail-fast机制
- copyOnWriteArrayList的fail-safe机制
list:有序,可重复,允许多个null,支持下标随机访问
set:无序,不可重复,单一null,必须遍历访问
arraylist:基于数组实现,占用连续空间,有利于查找、修改,不利于插入、删除[适用场景不同]
linkedlist:基于链表实现,不要求占用空间连续,有利于插入、删除,不利于查找、修改[适用场景不同]
1.7之前:基于segment分段hashmap存储实现的,segment分段存储部分不扩容,仅内部的hashmap进行扩容[哪个线程对应的内部hashmap需要扩容,哪个线程就负责做这个事情]
1.8之后:不是基于segment分段存储实现的,所有的K-V对都包含在一个map中,只是扩容的时候,那就每个子线程都参与扩容
1.7:底层是数组+链表,哈希算法复杂 头插法
1.8:底层是数组+链表+红黑树,由于引入红黑树,哈希算法得到简化,从而优化hashmap的插入、查询效率 尾插法
大体流程:
1.依据key和哈希算法计算下标
2.如果下标位置为空,则封装成对象(1.7:entry对象,1.8:node对象),放置该位置
3.如果下标位置不空,
3.1 JDK1.7:判断是否需要扩容,然后,头插法插入到对应位置的链表中
3.2 JDK.8:判断是红黑树节点还是链表节点,然后插入到hashmap里面,最后判断扩容
3.2.1 红黑树节点:将KV对封装成红黑树节点,加入到红黑树中
3.2.2 链表节点:尾插法插入到对应位置的链表中,如果多于等于8个节点,将链表转为红黑树
大体流程:
1.计算hashcode,其本质是将存储地址转换成一个整数得到
2.hashcode高16位与低16位进行异或,得到一个整数值,将其对范围取模,从而限制下标的取值一定在范围之内
3.查看对应的下标数据,是否为空
3.1.哈希桶为空,直接返回空
3.2.哈希桶不为空,节点结构是红黑树还是链表
(1)、后续是红黑树,红黑树结构执行相应的 getTreeNode(hash,key) 查找操作。[hash 目标哈希值 key 目标键值]
(2)、后续是链表,则循环遍历链表根据key获取value
1.7:生成新数组,遍历原数组上的每个链表,将内部数据逐个转移至新数组
1.8:生成新数组,遍历原数组上的每个链表与红黑树
①如果原数组上是链表,遍历每个元素,重新计算下标并转移
②如果原数组上是红黑树,遍历每个元素,重新计算下标并转移,有冲突再购建链表与红黑树
线程安全的arrayList,底层也是用数组实现的,主要集中在读与写操作上
读:由于读写分别在老新数组上,因此,互相不干扰,也因此,读的性能不会受写的性能影响[适用于读多写少]
写:写操作会生成新数组,在完成之前,其他线程无法进行写操作[上了锁,线程安全];在完成之前,读的是原数组,写的是新数组,两者是不会互相干扰的。
因为concurrentHashMap一般的应用场景都是多线程的情况,
如果允许存储Null值,就会出现歧义,不确定
1.没有找到这个值
2.这个值本身就是Null
单线程不存在误判,因为逻辑都在一起,但是,多线程可能逻辑都是分开的。
触发扩容条件:初始默认情况下,arraylist容量为10,当10个容量已满,仍然需要往里添加时就会触发arraylist扩容。
扩容流程:
1.申请当前容量的 1.5倍的空间
2.将当前数据拷贝至新空间
3.将新数据存储至新空间,扩容完成
这个问题仅会出现在JDK7,JDK8以后 官方修复了
主要原因:hashmap扩容机制+并发机制
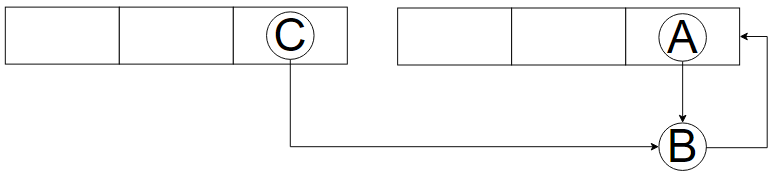
扩容机制:头插法
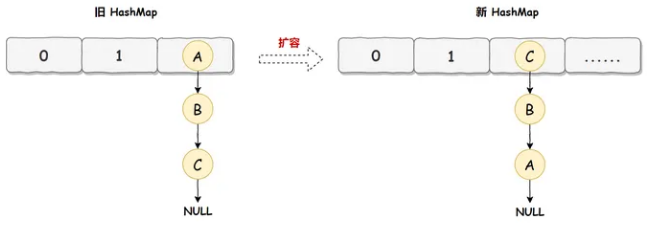
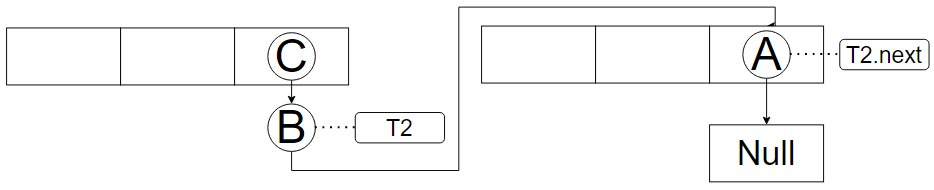
由图可知,头插法会导致链表元素反转
在并发机制下,指针的指向会变成
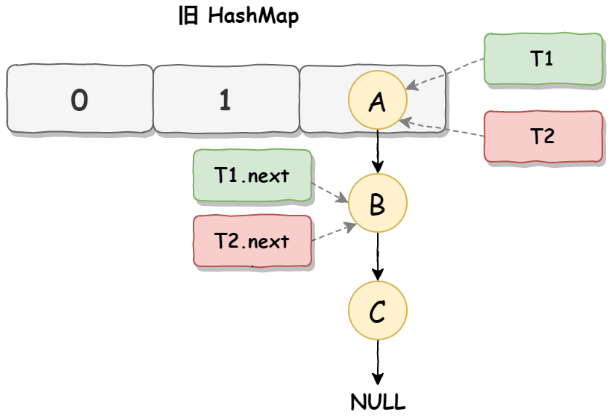
由图可知,两个线程的指针指向,此时都是一样的,且是“正确”的
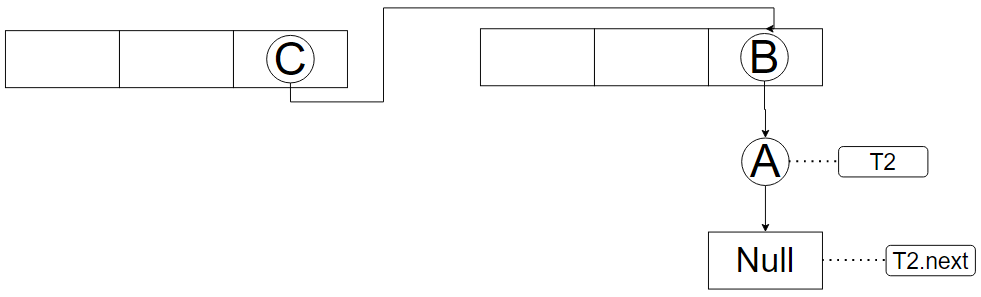
由于并发在微观上是串行的,因此,极端情况下,一个线程扩容完毕以后,另一个线程可能都没有开始扩容,就会导致如下情况
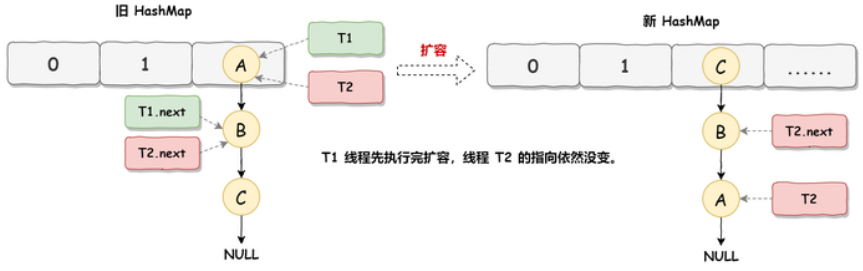
此时,线程2的指针逻辑与真实情况相反,如果继续扩容,就会形成死循环
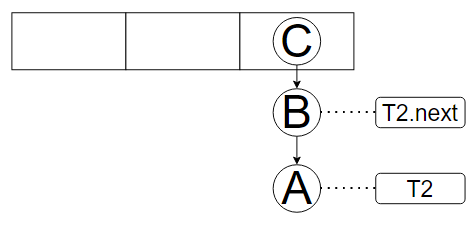
扩容基本逻辑:
next = T2.next
i = indexFor(T2.hash,newCapcity)
T2.next = newTable[i]
newTable[i] = T2
T2 = next
//循环上述 直至T2为 null
//这段逻辑带入T2情况 即可得到死循环
可能1.8 从头插法改成尾插法 也有这方面的考虑 毕竟尾插法是不会改变链表顺序的
1.当数量小于8的时候,链表性能并不太低
2.在默认的负载因子0.75的情况下,通过计算泊松分布,哈希冲突达到8次的概率已经小于百万分之一了,所以没必要再大了
3.红黑树本身单个节点的空间占用是链表单个节点的两倍,且红黑树本身的自平衡特性也会带来插入的开销[左旋右旋],因此,也不能单纯的替换掉链表,否则会带来空间上的浪费
之所以,链表转红黑树设置阈值为6
1.因为,如果两种转换设置成一样的,会造成两种数据结构不停的相互激荡转换
ps:当容量大于等于64时,也会将链表转换为红黑树
fail-fast:迭代的时候,发现了其他线程在修改,立即抛异常
成员变量:
迭代器:expectedModCount
集合:modCount
每次迭代会去检查两个成员变量是否一致 不一致就抛异常
fail-safe:迭代的时候,发现了其他线程在修改,可以牺牲部分一致性,使得迭代可以继续(类似copyOnWriteArrayList那种读写分离的方式)
区别在于
迭代器的内部数据 与 集合的数据 并不是同一份
集合每次写操作 都会在原数组上 拷贝一份 长度+1 的数组
因为是拷贝 因此地址与迭代器内的数据地址不是同一个
从而实现读写分离
读:old
写:new
参考:
1.https://zhuanlan.zhihu.com/p/458785543
2.https://blog.csdn.net/m0_68006260/article/details/125028368
3.https://blog.csdn.net/Liu_Wd/article/details/108052428
