
ThreadPoolExecutor自定义线程池需知
在看文章之前可以先看看这篇文章https://www.cnblogs.com/yaoxiaowen/p/6576898.html
jdk自带的线程池四种创建方式,自定义线程池以及各个参数的含义我想大家都有个认识了。
写这篇文章之前,是因为最近面了几家公司,问的很频繁,楼主太菜就答了一下创建方式,怎么自定义自己的线程池,及参数含义等。
23333..............如果是像楼主一样,处理策略答不上来,或者懵懵懂懂的,就耐心看看吧。
先来看看线程池的处理策略:

(1),如果当前线程池线程数目小于 corePoolSize(核心池还没满呢),那么就创建一个新线程去处理任务。
(2),如果核心池已经满了,来了一个新的任务后,会尝试将其添加到任务队列中,如果成功,则等待空闲线程将其从队列中取出并且执行,如果队列已经满了,则继续下一步。
(3),此时,如果线程池线程数量 小于 maximumPoolSize,则创建一个新线程执行任务,否则,那就说明线程池到了最大饱和能力了,没办法再处理了,此时就按照拒绝策略来处理。(就是构造函数当中的Handler对象)。
(4),如果线程池的线程数量大于corePoolSize,则当某个线程的空闲时间超过了keepAliveTime,那么这个线程就要被销毁了,直到线程池中线程数量不大于corePoolSize为止。
我想大家都看得懂,可面试的时候却因不太熟,支支吾吾的......,理论有了,得实践才行,不然记不牢.
上代码吧,如下:
package com.example.test; import java.util.concurrent.*; /** * Created by Administrator on 2017/11/26. */ public class TestClass { public static void main(String[] args) { try { ArrayBlockingQueue<Runnable> blockingQueue = new ArrayBlockingQueue<Runnable>(2); ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(3,5,5000L,TimeUnit.SECONDS,blockingQueue); for(int i = 0;i<7; i++){ Custem custem = new Custem(i); System.out.println(threadPoolExecutor.getPoolSize()+":"+threadPoolExecutor.getActiveCount()+":"+threadPoolExecutor.getTaskCount()); threadPoolExecutor.execute(custem); } threadPoolExecutor.shutdown(); }catch(Exception ex){ ex.printStackTrace(); } } } class Custem implements Runnable{ private int id; public Custem(int id){ this.id = id; } @Override public void run() { System.out.println("#"+id+" current thread is "+Thread.currentThread().getName()); try { //延时两秒 TimeUnit.MILLISECONDS.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } }
执行结果:
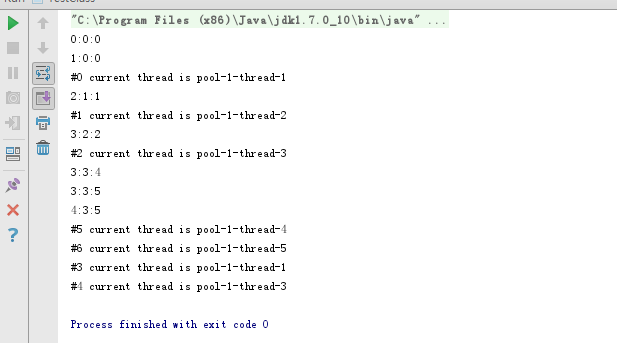
通过打印线程池的大小,活跃的线程数目,以及已执行的任务数量可以明确的看到,核心线程池大小,与最大线程池数以及队列大小之间的关系
把阻塞队列的大小变成1时候,执行会报错:

7个任务只执行了6个,也就是说,是最大线程数5+阻塞队列的大小1的个数。多了就报拒绝错误了 。
结合这个来看上面的线程池处理策略会不会更好的理解了呢,希望能帮到大家.......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号