对象字节流、序列化和反序列化
1.什么是序列化和反序列化?
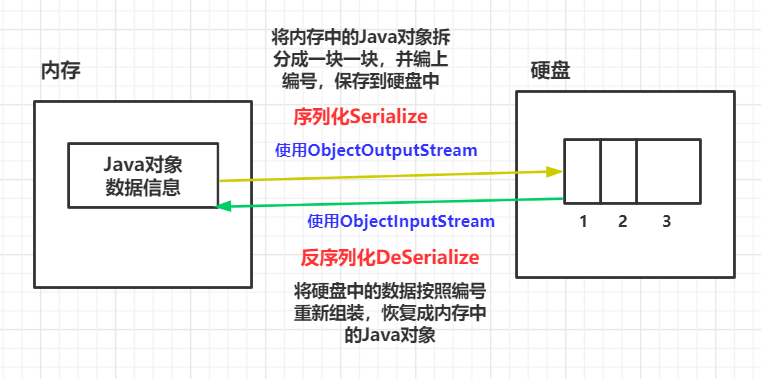
我们知道存在内存中的对象,当关机时就会消失,所以有的对象我们需要保存到硬盘中,这时候就需要借助对象字节流了。
内存中的对象数据保存到硬盘中的过程,我们称之为序列化;
硬盘中的对象数据重新恢复到硬盘中,称之为反序列化。
如图:
2.序列化和反序列化的实现
(1)准备一个实体类:无参构造、有参构造、setter/getter、重写toString()
要序列化的对象必须实现Serializable接口!不实现该接口就无法序列化,在运行时会报异常。
接口分为普通接口和标识接口,Serializable接口是一个标识接口,没有代码,只是起一个标识作用,虚拟机可以识别该标识,并对持有该标识的类做特殊的处理。
package com.dh.io;
import java.io.Serializable;
//重点:一定要实现Serializable接口!
public class Student implements Serializable {
private String name;
private int age;
private int no;
public Student() {
}
public Student(String name, int age, int no) {
this.name = name;
this.age = age;
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", no=" + no +
'}';
}
}
(2)序列化:ObjectOutputStream对象的writeObjectt()
package com.dh.io;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class ObjectOutputStream01 {
public static void main(String[] args) {
ObjectOutputStream oos = null;
//ObjectOutputStream的构造方法所需的是一个OutputStream对象
try {
oos = new ObjectOutputStream(new FileOutputStream("student"));
Student student = new Student("Jerry", 18, 1);
oos.writeObject(student);
} catch (IOException e) {
e.printStackTrace();
}finally {
if(oos != null){
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
(3)反序列化:ObjectInputStream对象的readObject()方法
package com.dh.io;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class ObjectInputStream01 {
public static void main(String[] args) {
ObjectInputStream ois = null;
try {
//ObjectInputStream的构造方法所需的是一个InputStream对象
ois = new ObjectInputStream(new FileInputStream("student"));
//强制类型转换
Student student = (Student)ois.readObject();
System.out.println(student);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
结果:
Student{name='Jerry', age=18, no=1}
3.序列化多个对象
当要同时序列化多个对象时,如果直接序列化的话,会发现反序列化时只能反序列化第一个,这时就需要借助集合,将需要序列化的多个对象放在集合中,再序列化该集合对象。
序列化代码:
package com.dh.io;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.List;
public class ObjectOutputStream02 {
public static void main(String[] args) {
ObjectOutputStream oos = null;
//ObjectOutputStream的构造方法所需一个OutputStream对象
try {
oos = new ObjectOutputStream(new FileOutputStream("student2"));
//声明一个ArrayList
List<Student> list = new ArrayList<>();
//添加多个对象
Student student = new Student("Jerry", 18, 1);
list.add(student);
Student student1 = new Student("Tom", 20, 2);
list.add(student1);
//序列化集合对象
oos.writeObject(list);
} catch (IOException e) {
e.printStackTrace();
}finally {
if(oos != null){
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
反序列化代码:
package com.dh.io;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.util.List;
public class ObjectInputStream02 {
public static void main(String[] args) {
ObjectInputStream ois = null;
try {
ois = new ObjectInputStream(new FileInputStream("student2"));
//强制类型转换
List<Student> list = (List<Student>) ois.readObject();
for (Student student : list) {
System.out.println(student);
}
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
结果:
Student{name='Jerry', age=18, no=1}
Student{name='Tom', age=20, no=2}
4.transient关键字
如果类中的某一些属性不想被序列化的话,就可以使用transient关键字修饰。在反序列化时,该属性不会输出对象的实际数据,而是输出属性的默认值。
如:
在上述Student类中的age属性加上transient
private transient int age;
重新运行3中的序列化集合对象和反序列化集合。
结果:age为int类型的默认值0
Student{name='Jerry', age=0, no=1}
Student{name='Tom', age=0, no=2}
5.序列化版本号
上述提到,需要序列化对象的类必须实现Serializable接口,实现了Serializable接口的类,会自动生成一个序列化版本号。
Java语言是采用什么机制来区分类的呢?
- 类名不同,必然是不同的类;
- 若类名相同,则比较序列化版本号,序列化版本号一样,则为同一个类,序列化版本号不同则为不同的类。
所以,序列化版本号的作用:用来区分类的。
但是现在又有一个问题,如果有一个之前写的类,但是后来又改变了需求,需要修改这个类的代码,修改了代码必然需要重新编译成新的字节码文件,新的字节码文件运行时又会生成一个新的序列化版本号,这显然是不太符合现实逻辑的,不应该认为这是两个不同的类。所以,这就是自动生成序列化版本号的缺陷。
建议给实现了Serializable接口的类,手动的提供一个固定的序列化版本号,此时系统将不再自动生成序列化版本号了,无论后期如何修改这个类的代码,都能保证在虚拟机看来,是同一个类。
private static final long serialVersionUID = 1L;//任意值,因为只有类名相同时才会比较序列化版本号,所以冲突的概率还是比较小的。
IDEA自动生成序列化版本号:

然后将鼠标移到类名上,就会有提示可以自动生成序列化版本号了:

水平有限,若有错误望纠正~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号