FileInputStream、FileOutputStream
上篇文章中我们介绍了需要掌握的16个流,先来介绍其中最常用的文件流。
1.FileInputStream
FileInputStream是文件字节输入流,从硬盘中读数据(read)到内存,并且是万能流,可传输任何类型的数据。
(1)怎么new对象?
一个类可以怎么new对象,取决于它的构造方法,所以,面向api文档编程又来了。
它有三个构造方法,先拿一个我们现在看得懂的:
FileInputStream(String name) //name为文件系统中文件的路径名
利用该构造方法实例化一个对象:
package com.dh.io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class FileInputStream01 {
public static void main(String[] args) {
FileInputStream fis = null;
//参数为文件路径
try {
fis = new FileInputStream("C:\\Users\\DH\\Desktop\\test.txt");
} catch (FileNotFoundException e) {
e.printStackTrace();
}finally {
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
查看源码,发现FileInputStream的构造方法中thows了FileNotFoundException,这是一个编译时异常,所以我们在调用该方法时,需要对这个异常进行预处理,因为是在main方法中了,所以使用try...catch方式。
复制文件路径到参数时,会自动将\转换为\ \,因为在Java中,\代表转义字符,\ \ 代表\。
并且一定要记得在finally中关闭对象,因为finally中会使用到对象,所以要将对象放到外部去声明,在try中声明的话作用域范围就只在try中了,finally就不能使用了;关闭对象前需要先判断对象是否为空,如果为空就不需要关闭了,并且如果为空还有关闭操作的话,会造成空指针异常,close()方法也可能会发生IOException编译时异常,也需要进行预处理。
这样就new好一个文件字节输入流对象了。
(2)如何执行读操作?
输入流对应着read操作。
FileInputStream有三个方法可以执行read操作:
int read() //从该输入流读取一个字节的数据。
int read(byte[] b) //从该输入流读取最多 b.length个字节的数据为字节数组。
int read(byte[] b, int off, int len) //从该输入流读取最多 len字节的数据为字节数组。
我们学习常用的第一个和第二个。(主要是第2个)
准备一个txt文件,内容为:
abc 中国
-
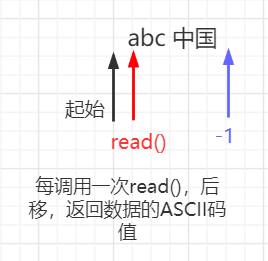
int read()
每次读取一个字节的数据,返回值为int类型,为当前读取到的数据的ASCII值,当没有数据时,返回值为-1。
![]()
所以我们可以知道,当read() == -1时代表着读完了数据,所以当read() != -1时,我们可以使用while循环读取,read() == -1时就停止。
只截取try{}中代码:
fis = new FileInputStream("C:\\Users\\DH\\Desktop\\test.txt"); int i = 0; while((i=fis.read()) != -1){ System.out.print(i + "\t"); //输出结果:97 98 99 32 228 184 173 229 155 189 }注意:read()也会抛出IOException编译时异常,需要预处理。
abc分别为97、98、99,空格为32,但是因为中文大于一个字节,所以控制台会乱码,输出乱码的ASCII码值。
但是这种效率实在是太低了,就像你买一袋苹果,你居然一个一个分别拿回家,当然是拿个袋子装啊。
-
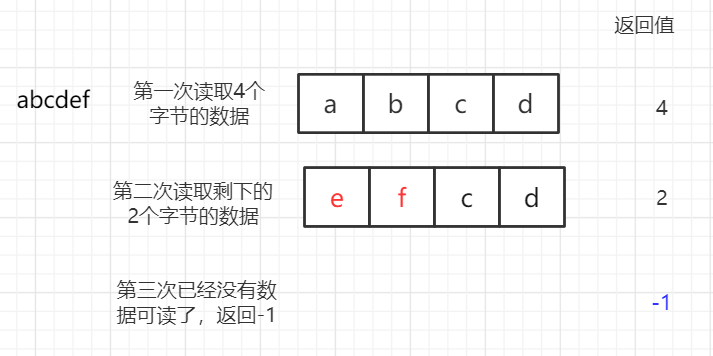
int read(byte[] b)
这里的byte数组,就相当于装苹果的袋子。
每次读取字节数组长度个字节的数据,
减少硬盘和内存的交互,提高程序的执行效率;返回值为int,为读取到的字节数据的数量,当没有读到数据时,输出-1。
![]()
所以每一次读取到的数据,为byte数组中前返回值数量个数据。
fis = new FileInputStream("C:\\Users\\DH\\Desktop\\test.txt"); byte[] bytes= new byte[4]; int readCount = 0; while ((readCount = fis.read(bytes)) != -1){ System.out.print(readCount +"\t"); System.out.println(new String(bytes,0,readCount)); }结果:
4 abc 4 中� 2 ��可以看到还是乱码了,如果我们能知道总共有多少个字节的数据,一次性读完就好了。
(3)其它常用方法
available()就可以解决上诉问题。
- available()
public int available() throws IOException //返回文件中没有读取的数据字节数
如果我们从一开始就获取到没有读取的数据字节数,然后一次读完,就不会乱码了:
fis = new FileInputStream("C:\\Users\\DH\\Desktop\\test.txt");
int available = fis.available(); //获取没有读的数据的字节数
byte[] bytes= new byte[available];
int readCount = 0;
while ((readCount = fis.read(bytes)) != -1){
System.out.print(readCount +"\t");
System.out.println(new String(bytes,0,readCount));
}
结果:
10 abc 中国
虽然很方便,但是也可以看出此种方法适合小文件,不适合大文件。
- skip(long n)
public long skip(long n) throws IOException //跳过n个字节的数据不读
在读取前跳过前三个数据:
fis = new FileInputStream("C:\\Users\\DH\\Desktop\\test.txt");
int available = fis.available();
byte[] bytes= new byte[available];
int readCount = 0;
fis.skip(3); //跳过3个字节的数据不读
while ((readCount = fis.read(bytes)) != -1){
System.out.print(readCount +"\t");
System.out.println(new String(bytes,0,readCount));
}
结果:
7 中国
2.FileOutputStream
FileOutputStream是文件字节输出流,用于内存写入(write)数据到硬盘,并且是万能流,可传输任何类型的数据。
(1)怎么new对象?
FileOutputStream有四个构造方法,还是先拿一个我们看得懂的
FileOutputStream(String name) //创建文件输出流以指定的名称写入文件。
利用该构造方法,实例化对象:
package com.dh.io;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileOutputStream01 {
public static void main(String[] args) {
FileOutputStream fos = null;
try {
fos = new FileOutputStream("C:\\Users\\DH\\Desktop\\test.txt");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
if(fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
同FileInputStream,在外部声明、处理预编译异常、关闭流。
注意:当文件不存在时,会自动新建。
还有一个,比它多了一个boolean类型的参数:
FileOutputStream(String name, boolean append) //append为是否在原文件中以追加的方式写入,true为是
在(2)中会详细说它们的区别
(2)如何执行写操作?
内存向硬盘中写入数据,即write。
void write(byte[] b) //将 b.length个字节从指定的字节数组写入此文件输出流。
void write(byte[] b, int off, int len) //将 len字节从位于偏移量 off的指定字节数组写入此文件输出流。
void write(int b) //将指定的字节写入此文件输出流。
看着又与read()老像老像的啊!
看看最常用的第一个:
-
void write(byte[] b)
将 b.length个字节从指定的字节数组写入此文件输出流。
fos = new FileOutputStream("C:\\Users\\DH\\Desktop\\test.txt");
byte[] bytes = {100,101,102}; //代表d、e、f
fos.write(bytes);
fos.flush();
记得一定要flush()!!!
去文件中查看结果:
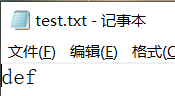
而且每次执行都是一样的结果。
诶?之前的abc 中国居然不见了!所以,使用FileOutputStream(String name)构造对象这种方式谨慎使用,会清空原本文件中的内容,再写入新的内容。
我们恢复原本文件的内容,再使用追加方式写入:
fos = new FileOutputStream("C:\\Users\\DH\\Desktop\\test.txt",true); //append参数为true
byte[] bytes = {100,101,102};
fos.write(bytes);
fos.flush();
结果:

执行多次:

可以看到,每次都是在源文件中直接追加内容的。
3.相对路径
不管是字节输出流还是字节输入流,都用到了一个文件的路径,上述案例中我们使用的都是电脑中的绝对路径,那在IDEA中的文件的相对路径怎么表示呢?
首先要知道,IDEA中的路径是相对于项目文件名的根目录下的。
如,我们在项目根下创建一个test01.txt文件:
package com.dh.io;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileOutputStream02 {
public static void main(String[] args) {
FileOutputStream fos = null;
try {
//IDEA默认的当前路径是:当前项目工程Project的根\
fos = new FileOutputStream("test01.txt");
byte[] bytes = {97,98,99};
fos.write(bytes);
fos.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
if(fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
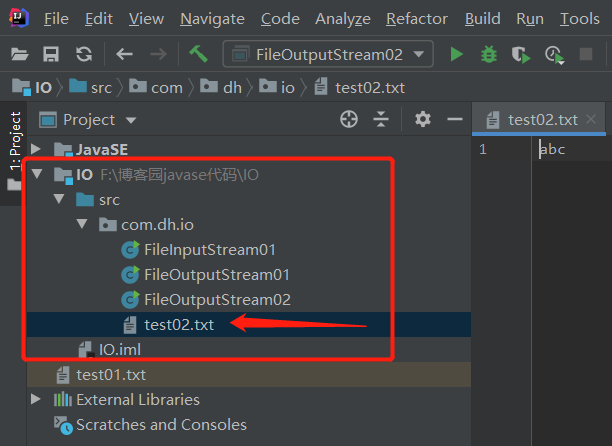
查看一下文件在哪里生成了?
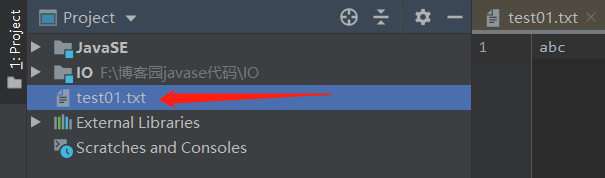
可以看到文件与Modules处于同一级,即在Project下。
再试着在Modules中建一个test02.txt:将上述文件的代码修改为:
fos = new FileOutputStream("IO\\src\\com\\dh\\io\\test02.txt");
本人水平有限,若有错误,望指出~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号