Java 8 Streams API 详解
流式编程作为Java 8的亮点之一,是继Java 5之后对集合的再一次升级,可以说Java 8几大特性中,Streams API 是作为Java 函数式的主角来设计的,夸张的说,有了Streams API之后,万物皆可一行代码。
什么是Stream
Stream被翻译为流,它的工作过程像将一瓶水导入有很多过滤阀的管道一样,水每经过一个过滤阀,便被操作一次,比如过滤,转换等,最后管道的另外一头有一个容器负责接收剩下的水。
示意图如下:
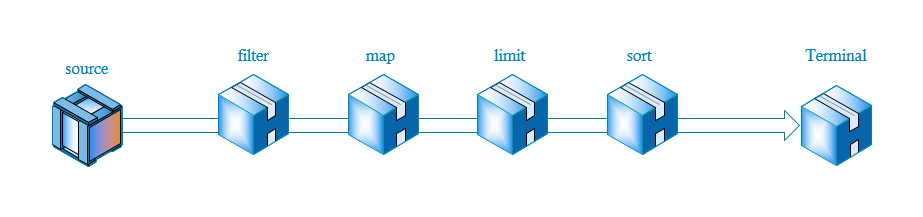
首先通过source产生流,然后依次通过一些中间操作,比如过滤,转换,限制等,最后结束对流的操作。
Stream也可以理解为一个更加高级的迭代器,主要的作用便是遍历其中每一个元素。
为什么需要Stream
Stream作为Java 8的一大亮点,它专门针对集合的各种操作提供各种非常便利,简单,高效的API,Stream API主要是通过Lambda表达式完成,极大的提高了程序的效率和可读性,同时Stram API中自带的并行流使得并发处理集合的门槛再次降低,使用Stream API编程无需多写一行多线程的大门就可以非常方便的写出高性能的并发程序。使用Stream API能够使你的代码更加优雅。
流的另一特点是可无限性,使用Stream,你的数据源可以是无限大的。
在没有Stream之前,我们想提取出所有年龄大于18的学生,我们需要这样做:
List<Student> result=new ArrayList<>();
for(Student student:students){
if(student.getAge()>18){
result.add(student);
}
}
return result;
使用Stream,我们可以参照上面的流程示意图来做,首先产生Stream,然后filter过滤,最后归并到容器中。
转换为代码如下:
return students.stream().filter(s->s.getAge()>18).collect(Collectors.toList());
- 首先
stream()获得流 - 然后
filter(s->s.getAge()>18)过滤 - 最后
collect(Collectors.toList())归并到容器中
是不是很像在写sql?
如何使用Stream
我们可以发现,当我们使用一个流的时候,主要包括三个步骤:
- 获取流
- 对流进行操作
- 结束对流的操作
获取流
获取流的方式有多种,对于常见的容器(Collection)可以直接.stream()获取
例如:
Collection.stream()Collection.parallelStream()Arrays.stream(T array) or Stream.of()
对于IO,我们也可以通过lines()方法获取流:
java.nio.file.Files.walk()java.io.BufferedReader.lines()
最后,我们还可以从无限大的数据源中产生流:
Random.ints()
值得注意的是,JDK中针对基本数据类型的昂贵的装箱和拆箱操作,提供了基本数据类型的流:
IntStreamLongStreamDoubleStream
这三种基本数据类型和普通流差不多,不过他们流里面的数据都是指定的基本数据类型。
Intstream.of(new int[]{1,2,3});
Intstream.rang(1,3);
对流进行操作
这是本章的重点,产生流比较容易,但是不同的业务系统的需求会涉及到很多不同的要求,明白我们能对流做什么,怎么做,才能更好的利用Stream API的特点。
流的操作类型分为两种:
-
Intermediate:中间操作,一个流可以后面跟随零个或多个
intermediate操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后会返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered -
Terminal:终结操作,一个流只能有一个
terminal操作,当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。Terminal操作的执行,才会真正开始流的遍历,并且会生成一个结果,或者一个 side effect。forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
Intermediate和Terminal完全可以按照上图的流程图理解,Intermediate表示在管道中间的过滤器,水会流入过滤器,然后再流出去,而Terminal操作便是最后一个过滤器,它在管道的最后面,流入Terminal的水,最后便会流出管道。
下面依次详细的解读下每一个操作所能产生的效果:
中间操作
对于中间操作,所有的API的返回值基本都是Stream<T>,因此以后看见一个陌生的API也能通过返回值判断它的所属类型。
map/flatMap
map顾名思义,就是映射,map操作能够将流中的每一个元素映射为另外的元素。
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
可以看到map接受的是一个Function,也就是接收参数,并返回一个值。
比如:
//提取 List<Student> 所有student 的名字
List<String> studentNames = students.stream().map(Student::getName)
.collect(Collectors.toList());
上面的代码等同于以前的:
List<String> studentNames=new ArrayList<>();
for(Student student:students){
studentNames.add(student.getName());
}
再比如:将List中所有字母转换为大写:
List<String> words=Arrays.asList("a","b","c");
List<String> upperWords=words.stream().map(String::toUpperCase)
.collect(Collectors.toList());
flatMap顾名思义就是扁平化映射,它具体的操作是将多个stream连接成一个stream,这个操作是针对类似多维数组的,比如容器里面包含容器等。
List<List<Integer>> ints=new ArrayList<>(Arrays.asList(Arrays.asList(1,2),
Arrays.asList(3,4,5)));
List<Integer> flatInts=ints.stream().flatMap(Collection::stream).
collect(Collectors.toList());
可以看到,相当于降维。
filter
filter顾名思义,就是过滤,通过测试的元素会被留下来并生成一个新的Stream
Stream<T> filter(Predicate<? super T> predicate);
同理,我们可以filter接收的参数是Predicate,也就是推断型函数式接口,接收参数,并返回boolean值。
比如:
//获取所有大于18岁的学生
List<Student> studentNames = students.stream().filter(s->s.getAge()>18)
.collect(Collectors.toList());
distinct
distinct是去重操作,它没有参数
Stream<T> distinct();
sorted
sorted排序操作,默认是从小到大排列,sorted方法包含一个重载,使用sorted方法,如果没有传递参数,那么流中的元素就需要实现Comparable<T>方法,也可以在使用sorted方法的时候传入一个Comparator<T>
Stream<T> sorted(Comparator<? super T> comparator);
Stream<T> sorted();
值得一说的是这个Comparator在Java 8之后被打上了@FunctionalInterface,其他方法都提供了default实现,因此我们可以在sort中使用Lambda表达式
例如:
//以年龄排序
students.stream().sorted((s,o)->Integer.compare(s.getAge(),o.getAge()))
.forEach(System.out::println);;
然而还有更方便的,Comparator默认也提供了实现好的方法引用,使得我们更加方便的使用:
例如上面的代码可以改成如下:
//以年龄排序
students.stream().sorted(Comparator.comparingInt(Student::getAge))
.forEach(System.out::println);;
或者:
//以姓名排序
students.stream().sorted(Comparator.comparing(Student::getName)).
forEach(System.out::println);
是不是更加简洁。
peek
peek有遍历的意思,和forEach一样,但是它是一个中间操作。
peek接受一个消费型的函数式接口。
Stream<T> peek(Consumer<? super T> action);
例如:
//去重以后打印出来,然后再归并为List
List<Student> sortedStudents= students.stream().distinct().peek(System.out::println).
collect(Collectors.toList());
limit
limit裁剪操作,和String::subString(0,x)有点先沟通,limit接受一个long类型参数,通过limit之后的元素只会剩下min(n,size)个元素,n表示参数,size表示流中元素个数
Stream<T> limit(long maxSize);
例如:
//只留下前6个元素并打印
students.stream().limit(6).forEach(System.out::println);
skip
skip表示跳过多少个元素,和limit比较像,不过limit是保留前面的元素,skip是保留后面的元素
Stream<T> skip(long n);
例如:
//跳过前3个元素并打印
students.stream().skip(3).forEach(System.out::println);
终结操作
一个流处理中,有且只能有一个终结操作,通过终结操作之后,流才真正被处理,终结操作一般都返回其他的类型而不再是一个流,一般来说,终结操作都是将其转换为一个容器。
forEach
forEach是终结操作的遍历,操作和peek一样,但是forEach之后就不会再返回流
void forEach(Consumer<? super T> action);
例如:
//遍历打印
students.stream().forEach(System.out::println);
上面的代码和一下代码效果相同:
for(Student student:students){
System.out.println(sudents);
}
toArray
toArray和List##toArray()用法差不多,包含一个重载。
默认的toArray()返回一个Object[],
也可以传入一个IntFunction<A[]> generator指定数据类型
一般建议第二种方式。
Object[] toArray();
<A> A[] toArray(IntFunction<A[]> generator);
例如:
Student[] studentArray = students.stream().skip(3).toArray(Student[]::new);
max/min
max/min即使找出最大或者最小的元素。max/min必须传入一个Comparator。
Optional<T> min(Comparator<? super T> comparator);
Optional<T> max(Comparator<? super T> comparator);
count
count返回流中的元素数量
long count();
例如:
long count = students.stream().skip(3).count();
reduce
reduce为归纳操作,主要是将流中各个元素结合起来,它需要提供一个起始值,然后按一定规则进行运算,比如相加等,它接收一个二元操作 BinaryOperator函数式接口。从某种意义上来说,sum,min,max,average都是特殊的reduce
reduce包含三个重载:
T reduce(T identity, BinaryOperator<T> accumulator);
Optional<T> reduce(BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
例如:
List<Integer> integers = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
long count = integers.stream().reduce(0,(x,y)->x+y);
以上代码等同于:
long count = integers.stream().reduce(Integer::sum).get();
reduce两个参数和一个参数的区别在于有没有提供一个起始值,
如果提供了起始值,则可以返回一个确定的值,如果没有提供起始值,则返回Opeational防止流中没有足够的元素。
anyMatch\ allMatch\ noneMatch
测试是否有任意元素\所有元素\没有元素匹配表达式
他们都接收一个推断类型的函数式接口:Predicate
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate)
例如:
boolean test = integers.stream().anyMatch(x->x>3);
findFirst、 findAny
获取元素,这两个API都不接受任何参数,findFirt返回流中第一个元素,findAny返回流中任意一个元素。
Optional<T> findFirst();
Optional<T> findAny();
也有有人会问
findAny()这么奇怪的操作谁会用?这个API主要是为了在并行条件下想要获取任意元素,以最大性能获取任意元素
例如:
int foo = integers.stream().findAny().get();
collect
collect收集操作,这个API放在后面将是因为它太重要了,基本上所有的流操作最后都会使用它。
我们先看collect的定义:
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
<R, A> R collect(Collector<? super T, A, R> collector);
可以看到,collect包含两个重载:
一个参数和三个参数,
三个参数我们很少使用,因为JDK提供了足够我们使用的Collector供我们直接使用,我们可以简单了解下这三个参数什么意思:
Supplier:用于产生最后存放元素的容器的生产者accumulator:将元素添加到容器中的方法combiner:将分段元素全部添加到容器中的方法
前两个元素我们都很好理解,第三个元素是干嘛的呢?因为流提供了并行操作,因此有可能一个流被多个线程分别添加,然后再将各个子列表依次添加到最终的容器中。
↓ - - - - - - - - -
↓ --- --- ---
↓ ---------
如上图,分而治之。
例如:
List<String> result = stream.collect(ArrayList::new, List::add, List::addAll);
接下来看只有一个参数的collect
一般来说,只有一个参数的collect,我们都直接传入Collectors中的方法引用即可:
List<Integer> = integers.stream().collect(Collectors.toList());
Collectors中包含很多常用的转换器。toList(),toSet()等。
Collectors中还包括一个groupBy(),他和Sql中的groupBy一样都是分组,返回一个Map
例如:
//按学生年龄分组
Map<Integer,List<Student>> map= students.stream().
collect(Collectors.groupingBy(Student::getAge));
groupingBy可以接受3个参数,分别是
- 第一个参数:分组按照什么分类
- 第二个参数:分组最后用什么容器保存返回(当只有两个参数是,此参数默认为
HashMap)- 第三个参数:按照第一个参数分类后,对应的分类的结果如何收集
有时候单参数的
groupingBy不满足我们需求的时候,我们可以使用多个参数的groupingBy
例如:
//将学生以年龄分组,每组中只存学生的名字而不是对象
Map<Integer,List<String>> map = students.stream().
collect(Collectors.groupingBy(Student::getAge,Collectors.mapping(Student::getName,Collectors.toList())));
toList默认生成的是ArrayList,toSet默认生成的是HashSet,如果想要指定其他容器,可以如下操作:
students.stream().collect(Collectors.toCollection(TreeSet::new));
Collectors还包含一个toMap,利用这个API我们可以将List转换为Map
Map<Integer,Student> map=students.stream().
collect(Collectors.toMap(Student::getAge,s->s));
值得注意的一点是,
IntStream,LongStream,DoubleStream是没有collect()方法的,因为对于基本数据类型,要进行装箱,拆箱操作,SDK并没有将它放入流中,对于基本数据类型流,我们只能将其toArray()
优雅的使用Stream
了解了Stream API,下面详细介绍一下如果优雅的使用Steam
-
了解流的惰性操作
前面说到,流的中间操作是惰性的,如果一个流操作流程中只有中间操作,没有终结操作,那么这个流什么都不会做,整个流程中会一直等到遇到终结操作操作才会真正的开始执行。
例如:
students.stream().peek(System.out::println);这样的流操作只有中间操作,没有终结操作,那么不管流里面包含多少元素,他都不会执行任何操作。
-
明白流操作的顺序的重要性
在
Stream API中,还包括一类Short-circuiting,它能够改变流中元素的数量,一般这类API如果是中间操作,最好写在靠前位置:考虑下面两行代码:
students.stream().sorted(Comparator.comparingInt(Student::getAge)). peek(System.out::println). limit(3). collect(Collectors.toList());students.stream().limit(3). sorted(Comparator.comparingInt(Student::getAge)). peek(System.out::println). collect(Collectors.toList());两段代码所使用的
API都是相同的,但是由于顺序不同,带来的结果都非常不一样的,第一段代码会先排序所有的元素,再依次打印一遍,最后获取前三个最小的放入
list中,第二段代码会先截取前3个元素,在对这三个元素排序,然后遍历打印,最后放入
list中。 -
明白
Lambda的局限性由于
Java目前只能Pass-by-value,因此对于Lambda也和有匿名类一样的final的局限性。具体原因可以参考Java 干货之深人理解内部类
因此我们无法再
lambda表达式中修改外部元素的值。同时,在
Stream中,我们无法使用break提前返回。 -
合理编排
Stream的代码格式由于可能在使用流式编程的时候会处理很多的业务逻辑,导致
API非常长,此时最后使用换行将各个操作分离开来,使得代码更加易读。例如:
students.stream().limit(3). sorted(Comparator.comparingInt(Student::getAge)). peek(System.out::println). collect(Collectors.toList());而不是:
students.stream().limit(3).sorted(Comparator.comparingInt(Student::getAge)).peek(System.out::println).collect(Collectors.toList());同时由于
Lambda表达式省略了参数类型,因此对于变量,尽量使用完成的名词,比如student而不是s,增加代码的可读性。尽量写出敢在代码注释上留下你的名字的代码!
总结
总之,Stream是Java 8 提供的简化代码的神器,合理使用它,能让你的代码更加优雅。
尊重劳动成功,转载注明出处
参考链接:
《Effective Java》3th
java8 stream groupby后的数据结构是否可以重构
如果觉得写得不错,欢迎关注微信公众号:逸游Java ,每天不定时发布一些有关Java干货的文章,感谢关注


 浙公网安备 33010602011771号
浙公网安备 33010602011771号