记一次 OutOfMemoryError: Java heap space 的排错
1、情况概述
公司以前的某报名系统,项目启动后,在经过用户一段时间的使用之后,项目响应便开始变得极其缓慢,最后几乎毫无反应。日志里输出了一些似乎无关痛痒的异常,逐步修复,项目仍然出现这种情况,且 “项目启动 -> 服务无响应” 这段时间并不稳定。直到在被反复折磨的这几天里终于日志抓到了几个异常,都是 javax.servlet.ServletException: java.lang.OutOfMemoryError: Java heap space
2、异常分析
JVM在启动时默认设置可调配的内存空间为物理内存的1/64但小于1G,如果该空间的可用空间不足 2%,则抛出异常 OutOfMemoryError : Java heap space
项目中的日志模块并没能输出可追溯的内存溢出,只能先排除一些猜想:
- 项目中几乎不涉及大图片加载,流不关闭等情况可以排除
- 项目中的对象模型并不复杂,JVM的初始参数足够使用,所以单纯调整JVM的参数设置不是个好办法
在了解一下定位排错的方式后,发现这么个东西:JVM Heap Dump(堆转储文件),Heap Dump 记录了JVM中堆内存运行的情况,可以使用JDK提供的命令 jmap 生成,命令格式如下:
jmap -dump:live,format=b,file=heap-dump.bin <pid>1
1
jmap -dump:live,format=b,file=heap-dump.bin <pid>其中 pid 是JVM进程的id,heap-dump.bin 是生成的文件名称,会在执行命令的目录下生成该文件
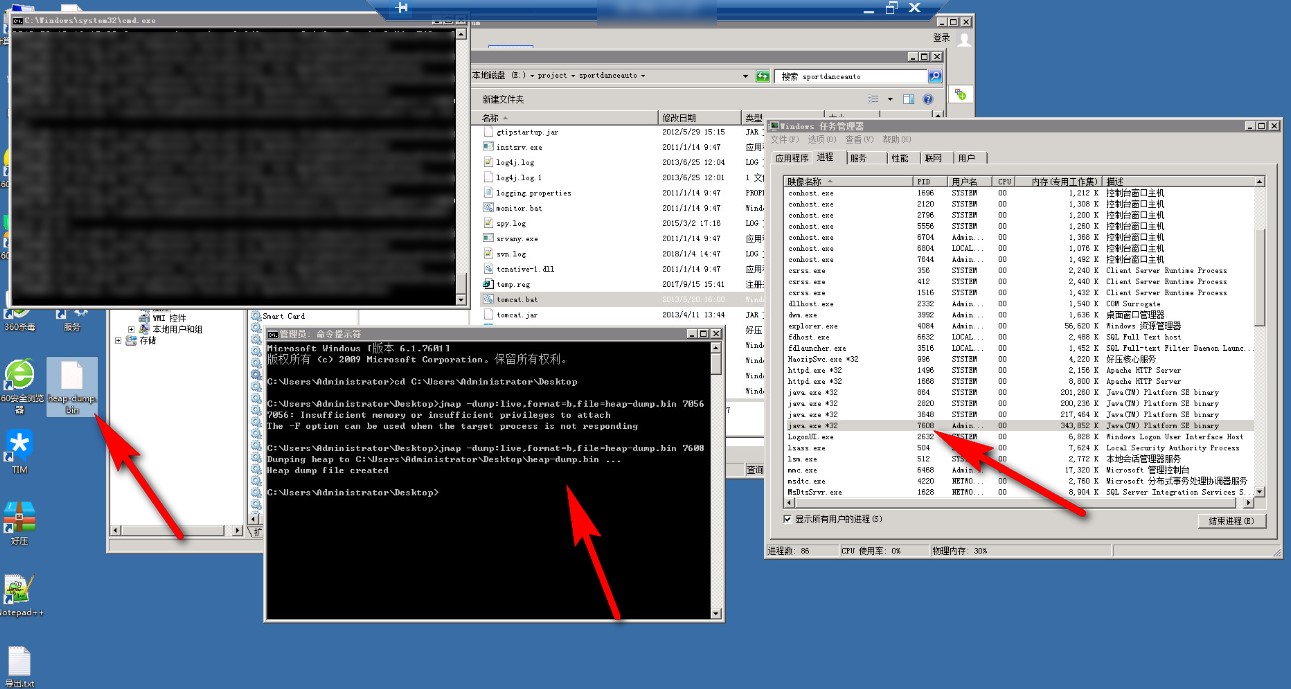
注:在执行命令生成 dump 文件的过程中,曾报错 "Insufficient memory or insufficient privileges to attach",这是因为权限问题,调用系统服务启动的tomcat和命令行执行命令看上去都在同个administrator用户下,其实不然。解决方法是将 tomcat 以 startup.bat 启动,再在命令行调用 jmap 即可。
分析 dump 文件的工具也有不少,这里使用了很多人都推荐的 Eclipse Memory Analyzer(MAT),这是 Eclipse 提供的一款用于 Heap Dump 文件的工具,有插件的形式,也可以独立运行。
使用该工具打开生成的 dump 文件,缓慢分析载入后弹出选框,选择 Leak Suspects Report:
 Dominator Tree :支配树,列出Heap Dump中处于活跃状态中的最大的几个对象,默认按 retained size进行排序,因此很容易找到占用内存最多的对象。
Dominator Tree :支配树,列出Heap Dump中处于活跃状态中的最大的几个对象,默认按 retained size进行排序,因此很容易找到占用内存最多的对象。使用工具的支配树功能,看到如下:
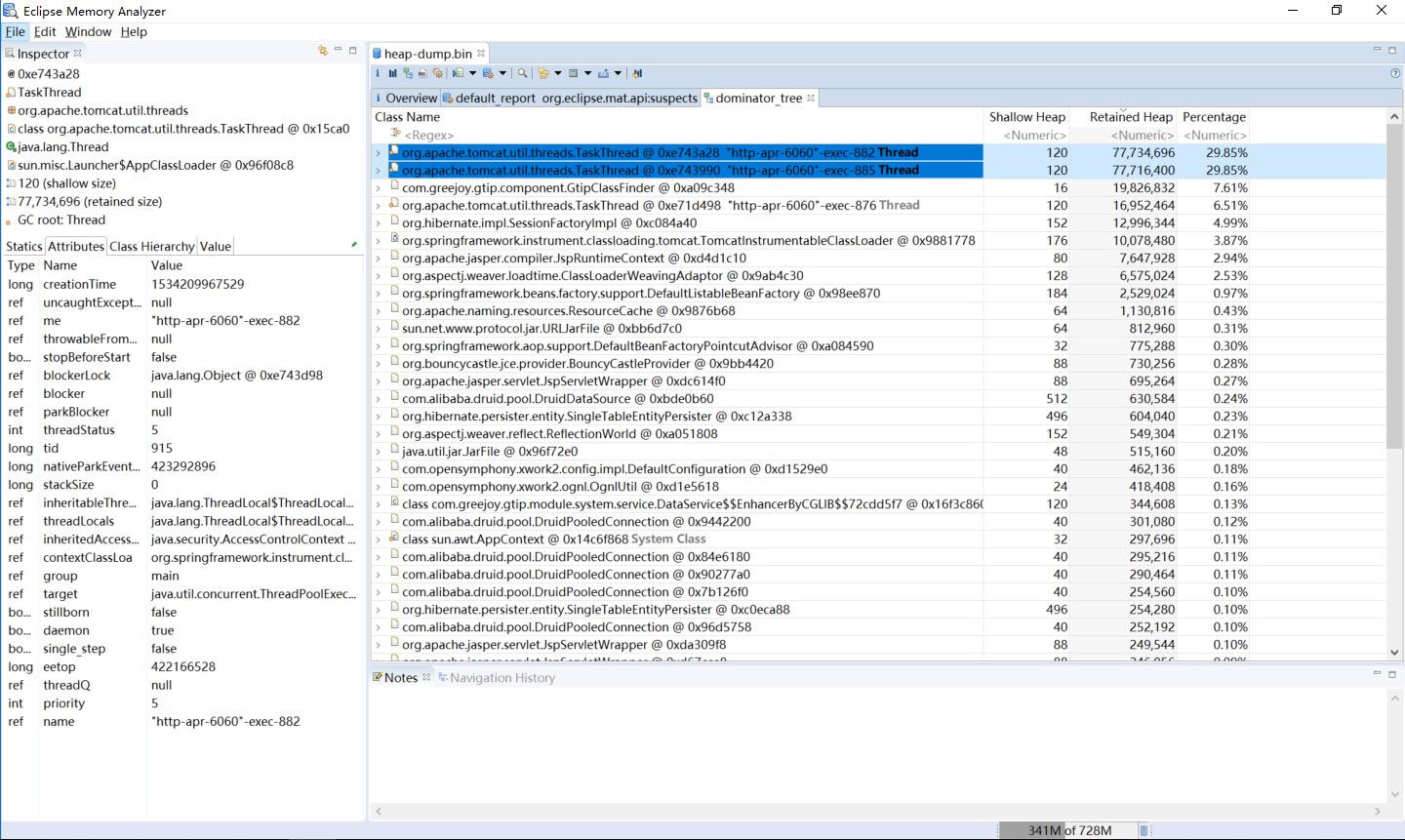
两个最高占比,而奇怪的在于之中:
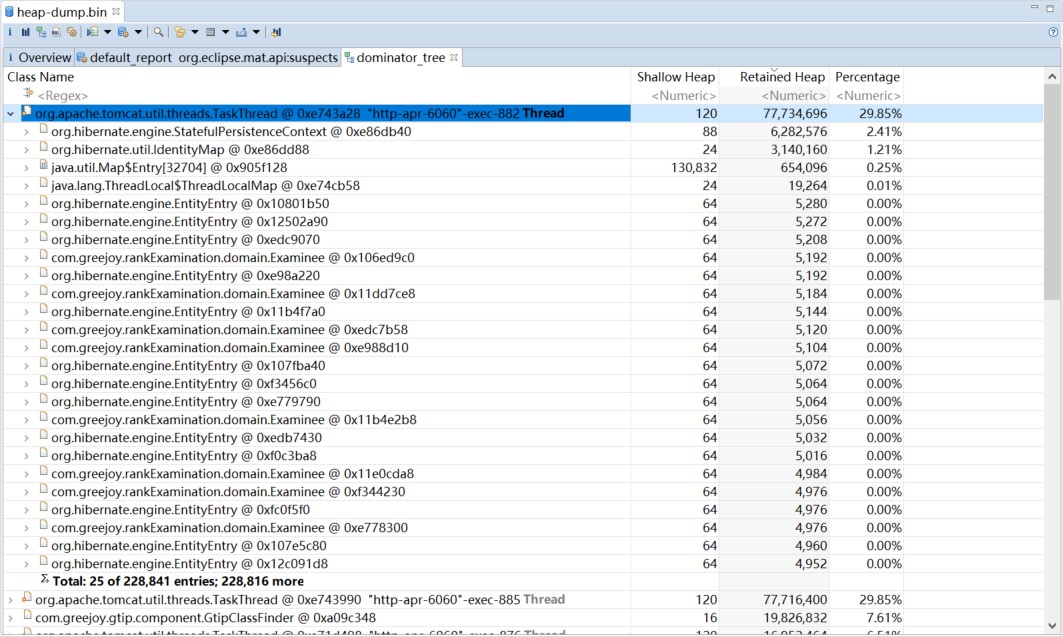
总占比 29.85%,但是之中最大的对象竟然也就只占了 2.41%,怎么回事?仔细一看,除开前几个对象之外,后面全部都是 Examinee 对象,数量之多,下面的黑体提示 "Total: 25 of 228,841 entries; 228,816",剩余二十多万个对象,展开一看全是 Examinee 和相关 Hibernate 的 EntityEntry 对象!那么造成内存溢出的问题就显而易见了,内存中加载的数据量过于庞大,可能是循环引用造成的内存泄漏,也可能是对象产出过快垃圾回收无法及时处理。
3、错误定位
跟用户进行沟通后,了解到其主要是在进行考生报名添加的操作,于是进行了模拟,发现在添加报名时发送了一个请求响应很慢,数据量也很大:
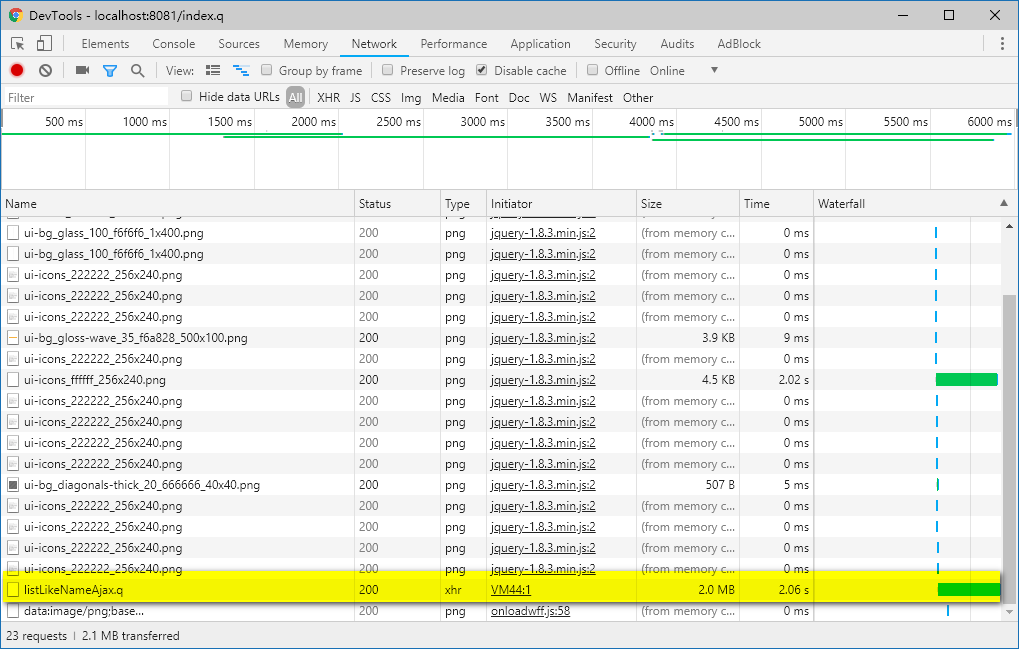
响应耗时2s,数据量竟然有2MB,点开一看,正是大量的考生信息数据,足足有30000+条:
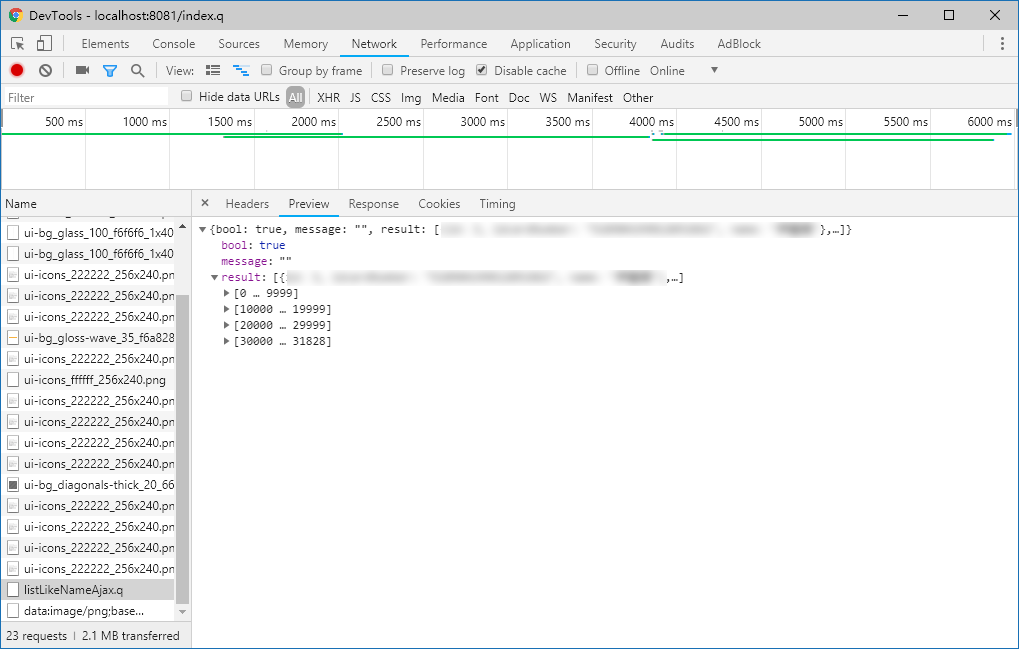
看了下这个请求数据的作用,是在拿给前端的一个插件进行自动选择用的:
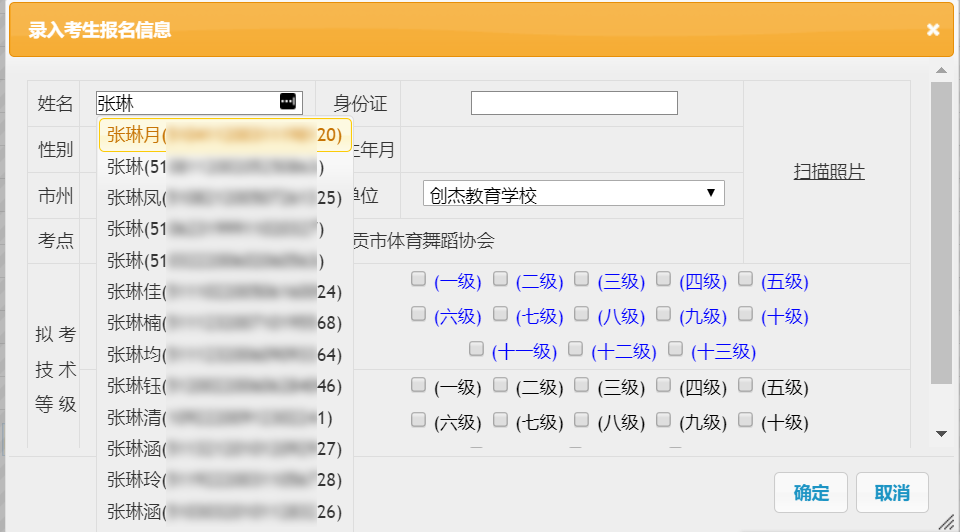
再看后台的代码也很粗暴,数据没做处理,抓出来直接全丢给前台了,这个过程中当然也就生成了成千上万个 Examinee 对象:

因为这个方法是在每次添加考生报名的时候都会触发,而用户在进行考生报名时添加操作很频繁,如果多个用户同时进行添加操作,那么短时间内产生的考生对象 Examinee 将直线上升,垃圾回收清理不及时,于是内存溢出的异常也就随之而来了。
知道了因果,那么把前端的数据抓取方式改一下就解决了。
修改之前,系统异常时的 dump 文件足有 280MB,修改之后系统稳定运行,生成的 dump 文件大概只有 100MB 左右了,完结撒花。
4、回顾和经验
这个项目前年就投入使用,去年也仅是增加了微信支付等和核心业务没有太大关联的相关功能,直到今年才暴露这个问题,其原因也正是因为数据量随着时间在不断增加,以往数据量小,哪怕数据完全加载也没有压力,但是现在完全加载的话,内存就吃不消了。
这也是为什么我之前使用 "项目重启" 的方式来恢复使用,但每次的效果却越来越差的原因,因为随着使用数据量也越来越大了。
这次排错的两点收获:
- 学会了最基本的内存分析方式,通过 dump 文件和 MAT 工具
- 明白了某些功能在生产运行的过程中,可能会随着数据量和业务情况的不断庞大而性能下降,在编写代码初期就要尽量预估将来数据量的发展趋势,以做出稳定合理的算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号