深入理解Linux系统调用
一、实验要求
- 找一个系统调用,系统调用号为学号最后2位相同的系统调用;
- 通过汇编指令触发该系统调用;
- 通过gdb跟踪该系统调用的内核处理过程;
- 重点阅读分析系统调用入口的保存现场、恢复现场和系统调用返回,以及重点关注系统调用过程中内核堆栈状态的变化。
二、环境准备
1. 下载Linux内核源码并配置QMenu虚拟环境,具体过程见https://www.cnblogs.com/demonatic/p/12875318.html
2. 配置内核选项
make defconfig #Default configuration is based on 'x86_64_defconfig' make menuconfig #打开debug相关选项 Kernel hacking ---> Compile-time checks and compiler options ---> [*] Compile the kernel with debug info [*] Provide GDB scripts for kernel debugging [*] Kernel debugging #关闭KASLR,否则会导致打断点失败 Processor type and features ----> [] Randomize the address of the kernel image (KASLR)
3. 编译和运行内核
make -j$(nproc) # nproc gives the number of CPU cores/threads available # 测试一下内核能不能正常加载运行,因为没有文件系统最终会kernel panic qemu-system-x86_64 -kernel arch/x86/boot/bzImage
4.制作根文件系统
我们这里为了简化实验环境,仅制作内存根文件系统。这里借助BusyBox 构建极简内存根文件系统,提供基本的用户态可执行程序。
axel -n 20 https://busybox.net/downloads/busybox-1.31.1.tar.bz2 tar -jxvf busybox-1.31.1.tar.bz2 cd busybox-1.31.1
make menuconfig 记得要编译成静态链接,不用动态链接库。 Settings ---> [*] Build static binary (no shared libs) 然后编译安装,默认会安装到源码目录下的 _install 目录中。 make -j$(nproc) && make install
mkdir rootfs cd rootfs cp ../busybox-1.31.1/_install/* ./ -rf mkdir dev proc sys home sudo cp -a /dev/{null,console,tty,tty1,tty2,tty3,tty4} dev/
准备init脚本文件放在根文件系统跟目录下(rootfs/init),添加如下内容到init文件。
#!/bin/sh mount -t proc none /proc mount -t sysfs none /sys echo "Wellcome MengningOS!" echo "--------------------" cd home /bin/sh
给init脚本添加可执行权限
chmod +x init
打包成内存根文件系统镜像
find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../rootfs.cpio.gz
打包后的内存根文件系统镜像如下:

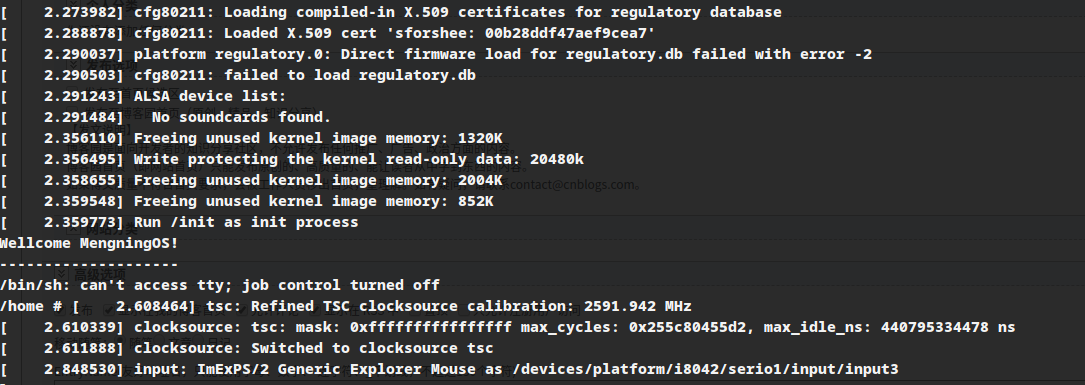
测试挂载根文件系统,看内核启动完成后是否执行init脚本
qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz
运行结果如下:
5.使用gdb server调试linux内核
使用gdb跟踪调试内核,需要加两个参数,一个是-s,在TCP 1234端口上创建了一个gdb-server。可以另外打开一个窗口,用gdb把带有符号表的内核镜像vmlinux加载进来,然后连接gdb server,设置断点跟踪内核。若不想使用1234端口,可以使用-gdb tcp:xxxx来替代-s选项),另一个是-S代表启动时暂停虚拟机,等待 gdb 执行 continue指令。
qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz -S -s -nographic -append "console=ttyS0"
用以上命令先启动,然后可以看到虚拟机一启动就暂停了。加-nographic - append "console=ttyS0"参数启动不会弹出QEMU虚拟机窗口,可以在纯命令行下启动虚拟机
再打开一个窗口,启动gdb,把内核符号表加载进来,建立连接:
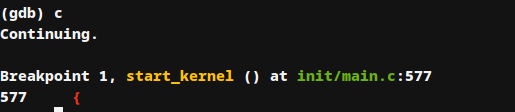
cd linux-5.4.34/ gdb vmlinux #一个包含linux kernel的静态链接的可执行文件,我们在编译时已经为其加上了符号表 (gdb) target remote:1234 #连接运行在QMenu上的gdb-server (gdb) b start_kernel #给start_kernel函数打断点 (gdb) c #运行到断点处
可以看到成功在start_kernel()处停下来,说明gdb调试linux内核环境已配置成功
三、系统调用概述
系统调用是内核为用于进程提供的与内核进行交互的一组接口,这些接口让应用程序受限地访问硬件设备,提供了创建新进程并与已有进程进行通信的机制,也提供了申请操作系统其他资源的能力。
在Linux中,每个系统调用被赋予一个系统调用号,用于指明到底是要执行哪个系统调用。内核记录了系统调用表中的所有已注册过的系统调用的列表,存储在sys_call_table中。每一个体系结构中都定义了这个表,x86-64中它定义于arch/x86/entry/syscall_64.c文件中。 这个表为每一个有效的系统调用都指定了唯一的系统调用号。
asmlinkage const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = { /* * Smells like a compiler bug -- it doesn't work * when the & below is removed. */ [0 ... __NR_syscall_max] = &__x64_sys_ni_syscall, #include <asm/syscalls_64.h> };
系统调用属于一种特殊的中断,使用陷阱(trap)这种软中断方式主动从用户态进入内核态,需要经历中断上下文的切换。
Linux通过执行int $0x80或者syscall指令来触发系统调用的执行。前者产生中断向量号为128的异常(trap),硬件找到在中断描述符表(IDT)中的表项,在自动切换到内核栈 (tss.ss0 : tss.esp0) 后根据中断描述符的 segment selector 在 GDT / LDT 中找到对应的段描述符,从段描述符拿到段的基址,加载到 cs ,将 offset 加载到 eip,由此跳转到linux处理系统调用的例程,最后硬件将 ss / sp / eflags / cs / ip / error code 依次压到内核栈。返回时,iret 将先前压栈的 ss / sp / eflags / cs / ip 弹出,恢复用户态调用时的寄存器上下文。
MSR寄存器是CPU中一堆特殊的寄存器,全名为 Model-Specific Register,这些寄存器在操作系统运行过程中起着重要作用。对于这些寄存器,需要采用专门的指令 RDMSR 和 WRMSR 进行读写。MSR IA32_LSTAR (MSR_LSTAR) 和 IA32_STAR (MSR_STAR) 在 arch/x86/kernel/cpu/common.c 的 syscall_init 中初始化:
void syscall_init(void) { wrmsr(MSR_STAR, 0, (__USER32_CS << 16) | __KERNEL_CS); wrmsrl(MSR_LSTAR, (unsigned long)entry_SYSCALL_64); #ifdef CONFIG_IA32_EMULATION wrmsrl(MSR_CSTAR, (unsigned long)entry_SYSCALL_compat); /* * This only works on Intel CPUs. * On AMD CPUs these MSRs are 32-bit, CPU truncates MSR_IA32_SYSENTER_EIP. * This does not cause SYSENTER to jump to the wrong location, because * AMD doesn't allow SYSENTER in long mode (either 32- or 64-bit). */ wrmsrl_safe(MSR_IA32_SYSENTER_CS, (u64)__KERNEL_CS); wrmsrl_safe(MSR_IA32_SYSENTER_ESP, 0ULL); wrmsrl_safe(MSR_IA32_SYSENTER_EIP, (u64)entry_SYSENTER_compat); #else wrmsrl(MSR_CSTAR, (unsigned long)ignore_sysret); wrmsrl_safe(MSR_IA32_SYSENTER_CS, (u64)GDT_ENTRY_INVALID_SEG); wrmsrl_safe(MSR_IA32_SYSENTER_ESP, 0ULL); wrmsrl_safe(MSR_IA32_SYSENTER_EIP, 0ULL); #endif /* Flags to clear on syscall */ wrmsrl(MSR_SYSCALL_MASK, X86_EFLAGS_TF|X86_EFLAGS_DF|X86_EFLAGS_IF| X86_EFLAGS_IOPL|X86_EFLAGS_AC|X86_EFLAGS_NT); }
可以看到 MSR_STAR 的第 32-47 位设置为 kernel mode 的 cs,48-63位设置为 user mode 的 cs。而 IA32_LSTAR 被设置为函数 entry_SYSCALL_64 的起始地址。由此,syscall指令使用MSR寄存器存放内核态的代码和栈的段号和偏移量,从而快速跳转到linux执行系统调用的中断处理例程的入口地址。此外,intel处理器还引入了sysenter快速系统调用。
四、追踪一个系统调用
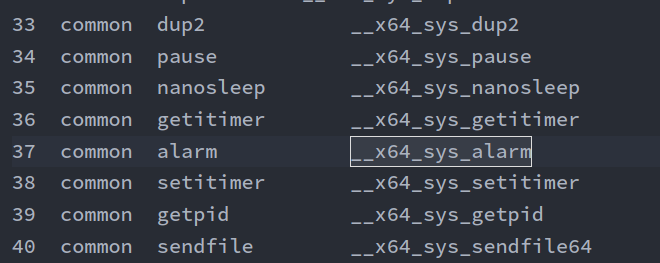
查看arch/x86/entry/syscalls/syscall_64.tbl对应的x86 64位系统调用表,可以看到37号系统调用为__x64_sys_alarm
编写一个简单的C语言程序,调用alarm系统调用,使程序在3秒后收到 SIGALRM 信号并调用该信号处理函数:
#include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <signal.h> void sig_alarm(int sig) { printf("sig is %d, sig_alarm is called\n", sig); } int main(int argc, char *argv[]) { signal(SIGALRM, sig_alarm); // 注册alarm信号对应的函数 alarm(3); // 3秒后,内核向进程发出alarm信号, 执行对应的信号注册函数 sleep(20); printf("main end!\n"); return 0; }
或者使用内联汇编直接调用alarm系统调用,两者效果等价:
int ret; int seconds=3; asm volatile( "movq %1, %%rdi\n\t" "movl $0x25, %%eax\n\t" "syscall\n\t" "movq %%rax,%0\n\t" :"=m"(ret) :"m"(seconds) );
使用gcc编译,将可执行文件放在rootfs的home目录下:
gcc alarm.c -o alarm -static
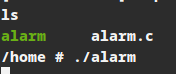
重新打包rootfs镜像,按前述方式重新挂载该内存文件系统。此时可以看到home目录下有了我们编译好的可执行程序:
使用gdb打断点,并调用alarm可执行程序,使用bt查看调用堆栈
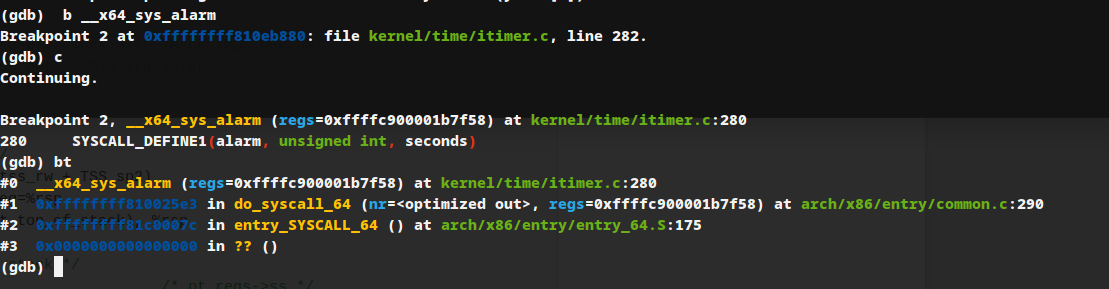
可以看出,系统调用入口点为entry_SYSCALL_64()函数,查看相应代码:
1 ENTRY(entry_SYSCALL_64) 2 UNWIND_HINT_EMPTY 3 /* 4 * Interrupts are off on entry. 5 * We do not frame this tiny irq-off block with TRACE_IRQS_OFF/ON, 6 * it is too small to ever cause noticeable irq latency. 7 */ 8 9 swapgs 10 /* tss.sp2 is scratch space. */ 11 movq %rsp, PER_CPU_VAR(cpu_tss_rw + TSS_sp2) 12 SWITCH_TO_KERNEL_CR3 scratch_reg=%rsp 13 movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp 14 15 /* Construct struct pt_regs on stack */ 16 pushq $__USER_DS /* pt_regs->ss */ 17 pushq PER_CPU_VAR(cpu_tss_rw + TSS_sp2) /* pt_regs->sp */ 18 pushq %r11 /* pt_regs->flags */ 19 pushq $__USER_CS /* pt_regs->cs */ 20 pushq %rcx /* pt_regs->ip */ 21 GLOBAL(entry_SYSCALL_64_after_hwframe) 22 pushq %rax /* pt_regs->orig_ax */ 23 24 PUSH_AND_CLEAR_REGS rax=$-ENOSYS 25 26 TRACE_IRQS_OFF 27 28 /* IRQs are off. */ 29 movq %rax, %rdi 30 movq %rsp, %rsi 31 call do_syscall_64 /* returns with IRQs disabled */ 32 ... 33 END(entry_SYSCALL_64)
由于在system_call内核入口点时还没有取得内核栈,也没有直接的方式访问内核数据结构来获取内核栈指针,因此先执行swapgs指令。
swapgs指令是基于 syscall/sysret 这种“快速切入系统服务”方案而带来的附加指令,它用一个MSR寄存器(IA32_KERNEL_GS_BASE)的内容交换GS寄存器(IA32_GS_BASE)的内容;GS寄存器在intel手册中被大致描述为“be used as additional base registers in some linear address calculations”,因此linux操作系统可以利用它获取指向内核数据结构的指针,通过这个内核数据结构可以得到ring 0的rsp值。同时也为了保存当前GS值。
因为syscall指令不会保存栈指针,需要movq %rsp, PER_CPU_VAR(cpu_tss_rw + TSS_sp2)来将用户栈sp保存到 per-cpu 变量 rsp_scratch 中。
由于Page Table Islotion(PTI)的存在,linux需要为一个进程维护两个页表,一个为用户态另一个为内核态:

由于中断发生在用户态,为了尽可能快地切换页表以从用户态地址空间切换到内核态的地址空间,内核空间的PGD和用户空间的PGD被连续放置在一个8KB的内存空间中,CR3寄存器指向内核或用户PGD物理地址。这段空间必须是8K对齐的,这样将CR3的切换操作转换为将CR3值的第13位(由低到高)的置位或清零操作,提高了CR3切换的速度。
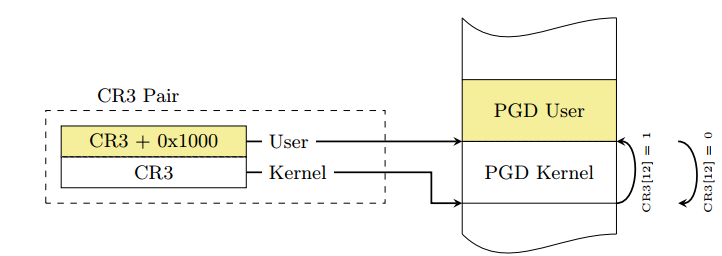
SWITCH_TO_KERNEL_CR3切换到内核页表,即得到master kernel pgd的物理地址。
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp 将per-cpu 变量cpu_current_top_of_stack,即内核态的栈偏移加载到 rsp。
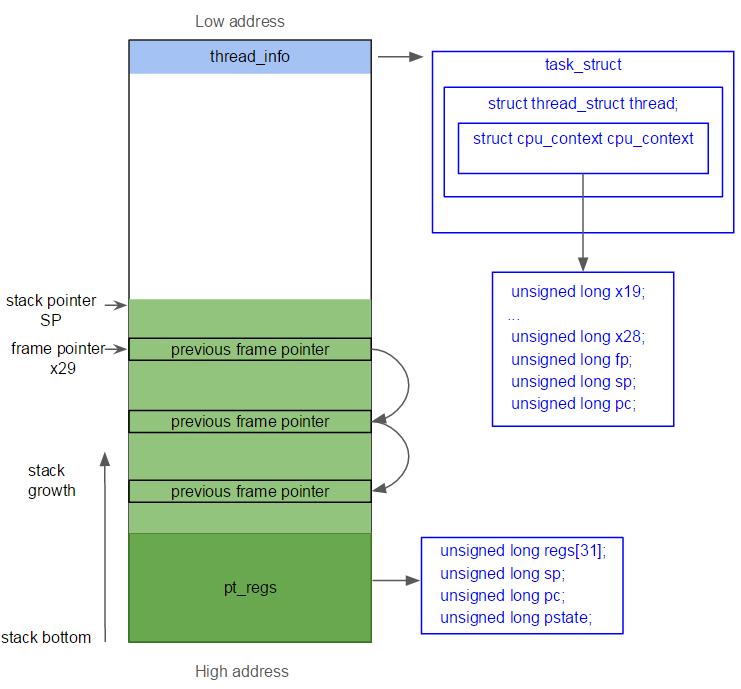
然后将用户态的寄存器值压到内核栈中,即构建出pt_regs结构体。pt_regs结构封装了需要在内核入口保存的所有寄存器如rsp、rip、eflags等,在系统调用、中断、陷阱、故障等涉及内核态用户态切换时都会使用到,具体保存的寄存器及其用途如下:
- rax system call number
- rcx return address
- r11 saved rflags (note: r11 is callee-clobbered register in C ABI)
- rdi arg0
- rsi arg1
- rdx arg2
- r10 arg3 (needs to be moved to rcx to conform to C ABI)
- r8 arg4
- r9 arg5
当程序返回用户态时,执行的下一条指令为pt_regs->rip。
struct pt_regs { /* * C ABI says these regs are callee-preserved. They aren't saved on kernel entry * unless syscall needs a complete, fully filled "struct pt_regs". */ unsigned long r15; unsigned long r14; unsigned long r13; unsigned long r12; unsigned long rbp; unsigned long rbx; /* These regs are callee-clobbered. Always saved on kernel entry. */ unsigned long r11; unsigned long r10; unsigned long r9; unsigned long r8; unsigned long rax; unsigned long rcx; unsigned long rdx; unsigned long rsi; unsigned long rdi; /* * On syscall entry, this is syscall#. On CPU exception, this is error code. * On hw interrupt, it's IRQ number: */ unsigned long orig_rax; /* Return frame for iretq */ unsigned long rip; unsigned long cs; unsigned long eflags; unsigned long rsp; unsigned long ss; /* top of stack page */ };
pg_regs处于内核栈的最高地址(栈底),thread_info位于内核栈最低地址。linux内核栈的layout如下所示:
TRACE_IRQS_OFF宏会调用trace_hardirqs_off函数来关闭中断追踪,用于调试。
再将rax系统调用号和rsp内核堆栈地址保存到rdi和rsi寄存器中作为do_syscall_64函数的两个参数,它在common.c中定义,代码如下:
#ifdef CONFIG_X86_64 __visible void do_syscall_64(unsigned long nr, struct pt_regs *regs) { struct thread_info *ti; enter_from_user_mode(); local_irq_enable(); ti = current_thread_info(); if (READ_ONCE(ti->flags) & _TIF_WORK_SYSCALL_ENTRY) nr = syscall_trace_enter(regs); if (likely(nr < NR_syscalls)) { nr = array_index_nospec(nr, NR_syscalls); regs->ax = sys_call_table[nr](regs); #ifdef CONFIG_X86_X32_ABI } else if (likely((nr & __X32_SYSCALL_BIT) && (nr & ~__X32_SYSCALL_BIT) < X32_NR_syscalls)) { nr = array_index_nospec(nr & ~__X32_SYSCALL_BIT, X32_NR_syscalls); regs->ax = x32_sys_call_table[nr](regs); #endif } syscall_return_slowpath(regs); } #endif
主要做的事为根据系统调用号nr查找sys_call_table,找到相应的系统调用函数并将存储了用户传递的寄存器值的pt_regs指针作为参数,将返回值放入pt_regs中的ax寄存器。
此时进入真正的系统调用函数alarm:

从alarm返回后真正的系统调用工作已经完成,可以看到alarm返回值0已存入eax中,并执行syscall_return_slowpath:
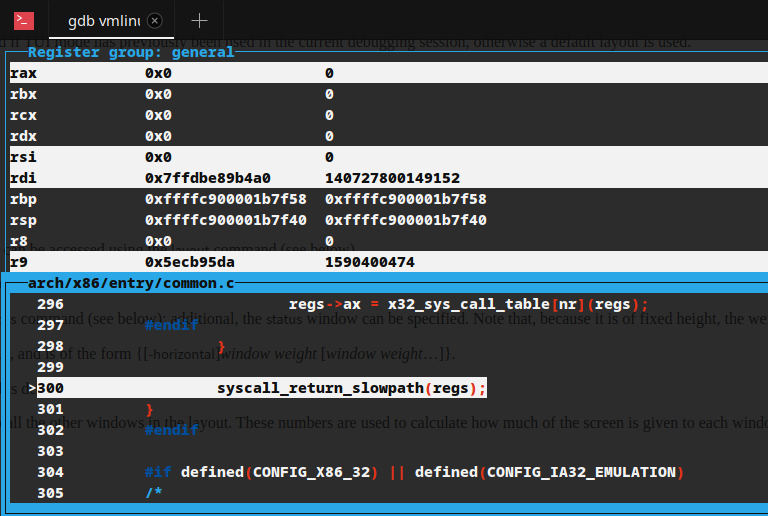
__visible inline void syscall_return_slowpath(struct pt_regs *regs) { struct thread_info *ti = current_thread_info(); u32 cached_flags = READ_ONCE(ti->flags); CT_WARN_ON(ct_state() != CONTEXT_KERNEL); if (IS_ENABLED(CONFIG_PROVE_LOCKING) && WARN(irqs_disabled(), "syscall %ld left IRQs disabled", regs->orig_ax)) local_irq_enable(); rseq_syscall(regs); /* * First do one-time work. If these work items are enabled, we * want to run them exactly once per syscall exit with IRQs on. */ if (unlikely(cached_flags & SYSCALL_EXIT_WORK_FLAGS)) syscall_slow_exit_work(regs, cached_flags); local_irq_disable(); prepare_exit_to_usermode(regs); }
这段代码主要进行关中断以便立即返回用户态。
do_syscall_64返回后,做的工作与函数开始时相对应。
call do_syscall_64 /* returns with IRQs disabled */ TRACE_IRQS_IRETQ /* we're about to change IF */ /* * Try to use SYSRET instead of IRET if we're returning to * a completely clean 64-bit userspace context. If we're not, * go to the slow exit path. */ movq RCX(%rsp), %rcx movq RIP(%rsp), %r11 cmpq %rcx, %r11 /* SYSRET requires RCX == RIP */ jne swapgs_restore_regs_and_return_to_usermode /* * On Intel CPUs, SYSRET with non-canonical RCX/RIP will #GP * in kernel space. This essentially lets the user take over * the kernel, since userspace controls RSP. * * If width of "canonical tail" ever becomes variable, this will need * to be updated to remain correct on both old and new CPUs. * * Change top bits to match most significant bit (47th or 56th bit * depending on paging mode) in the address. */ #ifdef CONFIG_X86_5LEVEL ALTERNATIVE "shl $(64 - 48), %rcx; sar $(64 - 48), %rcx", \ "shl $(64 - 57), %rcx; sar $(64 - 57), %rcx", X86_FEATURE_LA57 #else shl $(64 - (__VIRTUAL_MASK_SHIFT+1)), %rcx sar $(64 - (__VIRTUAL_MASK_SHIFT+1)), %rcx #endif /* If this changed %rcx, it was not canonical */ cmpq %rcx, %r11 jne swapgs_restore_regs_and_return_to_usermode cmpq $__USER_CS, CS(%rsp) /* CS must match SYSRET */ jne swapgs_restore_regs_and_return_to_usermode movq R11(%rsp), %r11 cmpq %r11, EFLAGS(%rsp) /* R11 == RFLAGS */ jne swapgs_restore_regs_and_return_to_usermode /* * SYSCALL clears RF when it saves RFLAGS in R11 and SYSRET cannot * restore RF properly. If the slowpath sets it for whatever reason, we * need to restore it correctly. * * SYSRET can restore TF, but unlike IRET, restoring TF results in a * trap from userspace immediately after SYSRET. This would cause an * infinite loop whenever #DB happens with register state that satisfies * the opportunistic SYSRET conditions. For example, single-stepping * this user code: * * movq $stuck_here, %rcx * pushfq * popq %r11 * stuck_here: * * would never get past 'stuck_here'. */ testq $(X86_EFLAGS_RF|X86_EFLAGS_TF), %r11 jnz swapgs_restore_regs_and_return_to_usermode /* nothing to check for RSP */ cmpq $__USER_DS, SS(%rsp) /* SS must match SYSRET */ jne swapgs_restore_regs_and_return_to_usermode /* * We win! This label is here just for ease of understanding * perf profiles. Nothing jumps here. */ syscall_return_via_sysret: /* rcx and r11 are already restored (see code above) */ UNWIND_HINT_EMPTY POP_REGS pop_rdi=0 skip_r11rcx=1 /* * Now all regs are restored except RSP and RDI. * Save old stack pointer and switch to trampoline stack. */ movq %rsp, %rdi movq PER_CPU_VAR(cpu_tss_rw + TSS_sp0), %rsp pushq RSP-RDI(%rdi) /* RSP */ pushq (%rdi) /* RDI */ /* * We are on the trampoline stack. All regs except RDI are live. * We can do future final exit work right here. */ STACKLEAK_ERASE_NOCLOBBER SWITCH_TO_USER_CR3_STACK scratch_reg=%rdi popq %rdi popq %rsp USERGS_SYSRET64 END(entry_SYSCALL_64)
由于syscall指令将返回地址存入rcx,rflags存入r11,因此需要恢复初rcx和r11以外的所有通用寄存器。
然后SWITCH_USER_CR3将cr3恢复为用户PGD地址。
popq %rsp恢复rsp为用户态栈顶。
USERGS_SYSRET64宏其扩展调用 swapgs 指令交换用户 GS 和内核GS, sysret 指令执行从系统调用处理退出。
最后引用一张图来比较简明地总结Linux syscall的过程:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号