基于mykernel 2.0编写一个操作系统内核
一、实验要求
- 按照https://github.com/mengning/mykernel 的说明配置mykernel 2.0,熟悉Linux内核的编译;
- 基于mykernel 2.0编写一个操作系统内核,参照https://github.com/mengning/mykernel提供的范例代码;
- 简要分析操作系统内核核心功能及运行工作机制。
二、实验环境
Host OS:
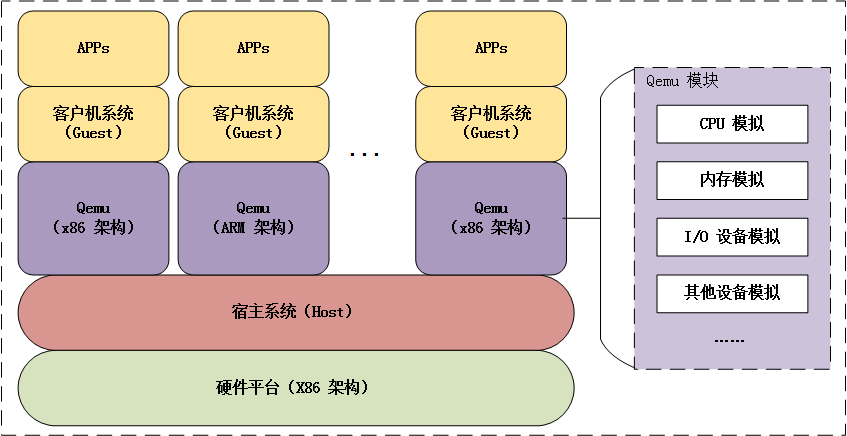
虚拟化环境:QMenu,用于模拟一个x86硬件环境
三、实验步骤
- 在Linux终端依次执行,如下命令来下载mykernel与配置构建环境与虚拟化环境。
wget https://raw.github.com/mengning/mykernel/master/mykernel-2.0_for_linux-5.4.34.patch sudo apt install axel axel -n 20 https://mirrors.edge.kernel.org/pub/linux/kernel/v5.x/linux-5.4.34.tar.xz xz -d linux-5.4.34.tar.xz tar -xvf linux-5.4.34.tar cd linux-5.4.34 patch -p1 < ../mykernel-2.0_for_linux-5.4.34.patch sudo apt install build-essential gcc-multilib libncurses5-dev bison flex libssl-dev libelf-dev sudo apt install qemu # install QEMU make defconfig # Default configuration is based on 'x86_64_defconfig' make -j$(nproc)
- 在Linux终端中使用QMenu运行mykernel:
qemu-system-x86_64 -kernel arch/x86/boot/bzImage

- 定义mykernel中用到的重要数据结构:
my_thread_struct中存储一个进程中的主线程ip和sp值
my_task_struct中定义了进程的pid,运行状态,栈空间,my_thread_struct,进程入口地址,进程链表。
my_curr_task指向当前运行的进程结构体
need_schedule由myinterrupter.c中的my_timer_handler中断处理函数修改其为有效
typedef struct my_thread_struct{ unsigned long ip; unsigned long sp; }my_thread_struct; #define KERNEL_STACK_SIZE 4096 #define MAX_TASK_NUM 1000 typedef struct my_task_struct { int pid; volatile long state; // -1 unrunnable, 0 runnable, >0 stopped char stack[KERNEL_STACK_SIZE]; my_thread_struct thread; unsigned long task_entry; struct my_task_struct *next; }my_task_struct; extern struct my_task_struct tasks[MAX_TASK_NUM]; extern struct my_task_struct *my_curr_task; extern volatile int need_schedule;
- 定义my_start_kernel函数用于初始化内核:
初始化my_task_struct数组,修改next域使其成为一个循环单链表。将curr_task指针指向init 0号进程。
每个进程的ip都指向my_process(void)函数地址,将init进程ip压栈后执行ret指令,来达到跳转rip到init进程入口的目的。
1 void __init my_start_kernel(void) 2 { 3 int init_pid=0; 4 int i; 5 printk(KERN_NOTICE "__init my_start_kernel(void)"); 6 7 tasks[init_pid].pid=init_pid; 8 tasks[init_pid].state=0; 9 tasks[init_pid].task_entry=tasks[init_pid].thread.ip=(unsigned long)my_proess; 10 tasks[init_pid].thread.sp=(unsigned long)&tasks[init_pid].stack[KERNEL_STACK_SIZE-1]; 11 tasks[init_pid].next=&tasks[init_pid]; 12 13 for(i=1;i<MAX_TASK_NUM;i++){ 14 memcpy(&tasks[i],&tasks[init_pid],sizeof(my_task_struct)); 15 tasks[i].pid=i; 16 tasks[i].state=-1; 17 tasks[i].thread.sp=(unsigned long)&tasks[i].stack[KERNEL_STACK_SIZE-1]; 18 tasks[i].next=tasks[i-1].next; 19 tasks[i-1].next=&tasks[i]; 20 } 21 //start init process 22 my_curr_task=&tasks[init_pid]; 23 asm volatile( 24 "movq %1, %%rsp\n\t" 25 "pushq %1\n\t" 26 "pushq %0\n\t" //push init process's ip 27 "ret\n\t" //pop init process's ip to eip- 28 : 29 :"c"(tasks[init_pid].thread.ip), "d"(tasks[init_pid].thread.sp) 30 ); 31 }
- 定义进程上下文切换的my_schedule(void)函数:
顺序遍历进程单链表,找到下一个状态为runnable的进程,保存正在运行的进程上下文,恢复该进程的上下文以继续执行。
先通过pushq %%rbp将当前进程ebp压入自己的内核栈中
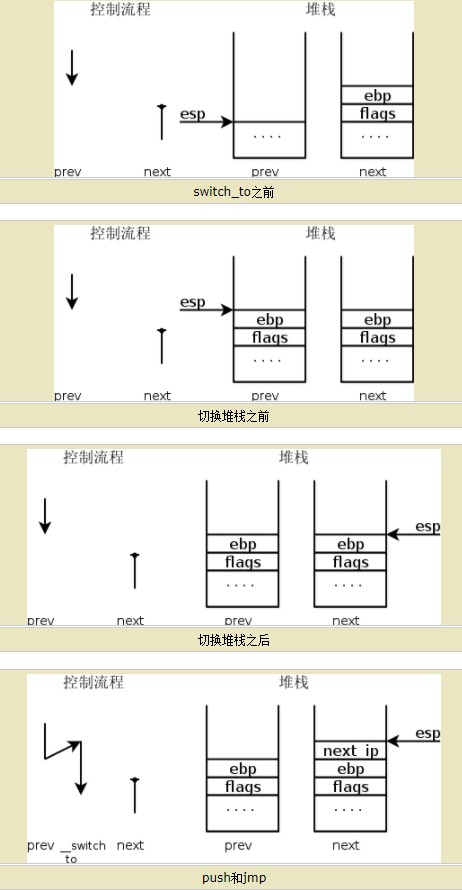
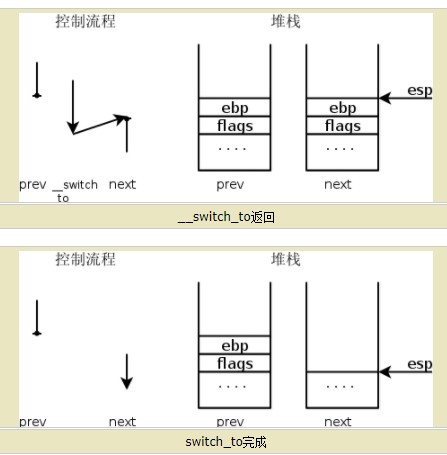
void my_schedule(void){ struct my_task_struct *prev=my_curr_task; struct my_task_struct *next=my_curr_task->next; printk(KERN_NOTICE ">>>my_schedule<<<\n"); if(next->state==0){ //runnable //switch to next process my_curr_task=next; printk(KERN_NOTICE ">>>switch %d to %d<<<\n",prev->pid,next->pid); asm volatile( "pushq %%rbp\n\t" "movq %%rsp, %0\n\t" "movq %2, %%rsp\n\t" "movq $1f, %1\n\t" "pushq %3\n\t" "ret\n\t" "1:\t" "popq %%rbp\n\t" :"=m"(prev->thread.sp),"=m"(prev->thread.ip) :"m"(next->thread.sp),"m"(next->thread.ip) ); } }
- 设置need_schedule
在my_timer_handler中周期性地设置need_schedule标记来表明是否需要重新执行一次调度;在真实的Linux内核中,某个进程应该被抢占时,scheduler_ticker()会设置这个标志;当一个优先级高的进程进入可执行状态时,try_to_wake_up()也会设置这个标志。该标记对于内核来讲是一个信息,它表示有其他进程应当被运行了,要尽快调用调度程序。当系统调用返回用户空间或中断处理程序返回用户空间时,内核会检查need_schedule标志,如果已经被设置则导致schedule()被调用。因为内核返回用户空间时,它知道自己是安全的,因为它既然可以继续执行当前进程,那么它当然可以再去选择一个新的进程去执行。两种情况的抢占都属于用户抢占。
/* * Called by timer interrupt. */ long time_count=0; void my_timer_handler(void) { if(time_count%1000==0&&need_schedule!=1){ printk(KERN_NOTICE ">>>my_timer_handler here<<<\n"); need_schedule=1; } time_count++; }
在本次实验中,我们让进程主动去调用my_schedule(),当进程上下文恢复时会继续执行schedule()之后的代码。
void my_proess(void){ int i=0; while(1){ i++; if(i%10000000==0){ printk(KERN_NOTICE "this is process %d -\n",my_curr_task->pid); if(need_schedule==1){ need_schedule=0; my_schedule(); } printk(KERN_NOTICE "this is process %d+\n",my_curr_task->pid); } } }
四、实验结果
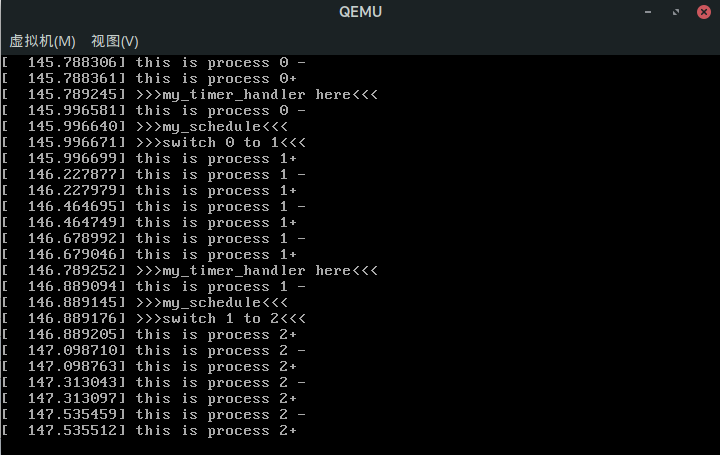
重新编译运行,可以看到如下结果:
1号进程执行print 1-的时候调用my_schedule,切换为进程2,当再次恢复上下文时执行的是print 1+,说明my_schedule()后的代码被继续执行,印证了上述理论。

参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号