
基于React实现的【绿色版电子书阅读器】,支持离线下载
MyReader 绿色版电子书阅读器
在线地址:http://myreader.linxins.com
手机扫码体验:

目录索引
store的设计与实现
effects 的逻辑处理
UI部分
优化
最后
开始
本项目没有使用任何脚手架工具和ui框架,因为本项目比较小,在时间允许的情况下,还是希望尽可能自己走一遍流程。
开发环境依然是react全家桶,基于最新版的webpack3、react15.6、react-router4、redux、redux-saga实现,就是不折腾不痛快。过程中略有小坑,比如热更新啦,dll动态链接库啦,preact不兼容啦,以及最新版本带来的不兼容什么的,不过都已经被社区大神趟平了。
store的设计与实现
首先来实现阅读器部分,关于电子阅读器我们可以总结出三个核心概念:书源、章节列表和章节内容。换源就是在书源中切换、跳转章节就是在章节列表中切换,我们只需要记录当前书源和当前章节就可以完整保存用户阅读进度。至于书籍详情当然也不能少,我们得知道当前到底看的是那一本书。
reader代表阅读器和当前书籍,这里我们跳过优质书源,原因大家都懂。
╮( ̄▽ ̄)╭
阅读器
- src/store/reducer/reader.js
const initState = {
id: null, // 当前书籍id,默认没有书籍
currentSource: 1, // 当前源下标:默认为1,跳过优质书源
currentChapter: 0, // 当前章节下标
source: [], // 源列表
chapters: [], // 章节列表
chapter: {}, // 当前章节
detail: {}, // 书籍详情
menuState: false, // 底部菜单是否展开,默认不展开
};
function reader(state = initState, action) {
switch (action.type) {
case 'reader/save':
return {
...state,
...action.payload,
};
case 'reader/clear':
return initState;
default:
return {
...state,
};
}
}
export default reader;
书架
因为我们并不是要做只能阅读一本书的鸡肋,我们要的是能在多本书籍之间快速切换,不但能够保存阅读进度(当前书源和当前章节),并且可以在缓存中读取数据,过滤掉那些不必要的服务器请求。
为此,我们可以模仿现实中的书架来实现这个功能:前面提到的reader是当前正在阅读的书籍,它是完整的包含了一本书籍所有信息的个体,而书架则是很多个这样的个体的集合。因此切换书籍的动作,其实就是将书籍放回书架,再从书架中拿出一本书的过程,如果在书架中找到了这本书,便直接取出,进而得到上次阅读这本书的全部数据,如果没有找到这本书,就从服务器获取并初始化阅读器。
- src/store/reducer/store.js
function store(state = {}, action) {
switch (action.type) {
case 'store/put': { // 将书籍放入书架
if (action.key) {
return {
...state,
[action.key]: {
...state[action.key],
...action.payload,
},
};
} else {
return {
...state,
};
}
}
case 'store/save': // 初始化书架
return {
...state,
...action.payload,
};
case 'store/delete': // 删除书籍
return {
...state,
[action.key]: undefined,
};
case 'store/clear': // 清空书架
return {};
default:
return {
...state,
};
}
}
export default store;
effects 的逻辑处理
获取书源,可以说是项目中最核心的功能了。其实这个方法叫换源有些欠妥,应该叫做换书。主要功能就是实现了上文提到的将当前阅读书籍放回书架,并取出新书这个功能。并且这个方法只有在阅读一本新书时才会调用。
要考虑的情况基本就是用户第一次打开应用,没有当前阅读书籍,此时直接获取书源进行下一步下一步即可。当用户已经在看一本书,并且切换到同一本书时,直接返回,如果切换到另一本书,则将当前数据连同书籍信息一起打包放回书架,当然在此之前要先查看书架中有无这本书,有则取出,无则继续获取书源。需要注意的是,这里不要使用数组,而是将书籍id作为键值存在书架中,这会使得获取和查找都十分方便。
需要注意的一点是,项目本质上是web应用,用户可能从url进入任意页面,所以要做好异常情况的处理,例如没有书籍详情等。
获取书源
- src/store/effects/reader.js
/**
* 获取书源
* @param query
*/
function* getSource({ query }) {
try {
const { id } = query;
// 这里获得整个缓存中的store,并对应上reader的store。其reader的store结构参考store/reducer/reader.js initState
const { reader: { id: currentId, detail: { title } } } = yield select();
if (currentId) {
if (id !== currentId) {
const { reader, store: { [id]: book } } = yield select();
console.log(`将《${title}》放回书架`);
yield put({ type: 'store/put', payload: { ...reader }, key: currentId });
yield put({ type: 'reader/clear' });
if (book && book.detail && book.source) {
console.log(`从书架取回《${book.detail.title}》`);
yield put({ type: 'reader/save', payload: { ...book } });
return;
}
} else {
return;
}
}
let { search: { detail } } = yield select();
yield put({ type: 'common/save', payload: { loading: true } });
if (!detail._id) {
console.log('详情不存在,前往获取');
detail = yield call(readerServices.getDetail, id);
}
const data = yield call(readerServices.getSource, id);
console.log(`从网络获取《${detail.title}》`);
yield put({ type: 'reader/save', payload: { source: data, id, detail } });
console.log(`阅读:${detail.title}`);
yield getChapterList();
} catch (error) {
console.log(error);
}
yield put({ type: 'common/save', payload: { loading: false } });
}
章节列表-章节内容
获取章节列表和章节内容比较简单,只需稍稍做些异常情况的处理即可。
- src/store/effects/reader.js
/**
* 章节列表
*/
function* getChapterList() {
try {
const { reader: { source, currentSource } } = yield select();
console.log('获取章节列表', currentSource, source.length, JSON.stringify(source));
if (currentSource >= source.length) {
console.log('走到这里说明所有书源都已经切换完了');
yield put({ type: 'reader/save', payload: { currentSource: 0 } });
yield getChapterList();
return;
}
const { _id, name = '未知来源' } = source[currentSource];
console.log(`书源: ${name}`);
const { chapters } = yield call(readerServices.getChapterList, _id);
yield put({ type: 'reader/save', payload: { chapters } });
yield getChapter();
} catch (error) {
console.log(error);
}
}
/**
* 获取章节内容
*/
function* getChapter() {
try {
const { reader: { chapters, currentChapter,
downloadStatus, chaptersContent } } = yield select();
if (downloadStatus) { // 已下载直接从本地获取
const chapter = chaptersContent[currentChapter || 0];
console.log(`章节: ${chapter.title}`);
yield put({ type: 'reader/save', payload: { chapter } });
window.scrollTo(0, 0);
} else {
const { link } = chapters[currentChapter || 0];
yield put({ type: 'common/save', payload: { loading: true } });
const { chapter } = yield call(readerServices.getChapter, link);
if (chapter) {
console.log(`章节: ${chapter.title}`);
yield put({ type: 'reader/save', payload: { chapter } });
window.scrollTo(0, 0);
} else {
console.log('章节获取失败');
yield getNextSource();
}
}
} catch (error) {
console.log(error);
}
yield put({ type: 'common/save', payload: { loading: false } });
}
换源实现
同是核心功能,这个必须有。换源其实非常简单,做一个智(sha)能(gua)换源吧(根据书源获取具体章节,如果获取不到就拿下一个书源再获取其具体章节,直到获取到正确的为止)。
换源其实就是操作标记书源的指针,这很容易,我们关心的是何时换源。经过测试,发现获取章节列表这一步几乎都没有问题,错误基本上是发生在获取具体章节这一步。因此,我们只要在章节列表中稍作判断即可实现自动换源。换源方法如下。
- src/store/effects/reader.js
/**
* 获取下一个书源。
* 在获取书源后无法获取 具体章节 便会获取下一个书源。直到所有书源换完为止
*/
function* getNextSource() {
try {
const { reader: { source, currentSource } } = yield select();
let nextSource = (currentSource || 1) + 1;
console.log(`开始第${nextSource}个书源`);
if (nextSource >= source.length) {
console.log('没有可用书源,切换回优质书源');
nextSource = 0;
}
console.log(`正在尝试切换到书源: ${source[nextSource] && source[nextSource].name}`);
yield put({ type: 'reader/save', payload: { currentSource: nextSource } });
yield getChapterList();
} catch (error) {
console.log(error);
}
}
效果如下,当1号书源出错后我们自动跳转到下一个书源,很方便有木有。
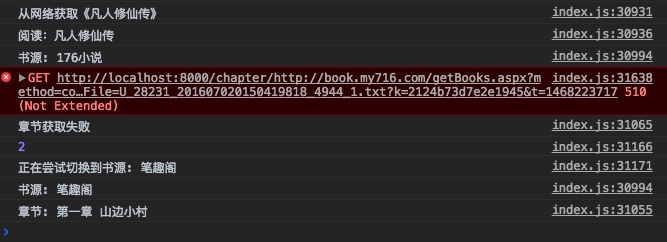
切换章节
非常简单,稍微做下异常处理就好。
- src/store/effects/reader.js
function* goToChapter({ payload }) {
try {
const { reader: { chapters } } = yield select();
const nextChapter = payload.nextChapter;
if (nextChapter > chapters.length) {
console.log('没有下一章啦');
return;
}
if (nextChapter < 0) {
console.log('没有上一章啦');
return;
}
yield put({ type: 'reader/save', payload: { currentChapter: nextChapter } });
yield getChapter();
} catch (error) {
console.log(error);
}
}
离线下载
考虑到节约流量问题,获取一个可用的书源后对每个章节去下载相应的章节内容,然后存储在本地(chaptersContent)。
- src/store/effects/reader.js
/**
* 离线下载书籍 获取书源
* @param query
*/
function* downGetSource({ query }) {
try {
const { id, download } = query;
// 这里获得整个缓存中的store,并对应上reader的store。其reader的store结构参考store/reducer/reader.js initState
// 同时获取该书是否下载的状态
const { reader: { id: currentId, detail: { title } } } = yield select();
console.log(`当前书信息currentId:${currentId} , id:${id}, title:${title}`);
if (download) {
const judgeRet = yield findBookByStoreId(id);
console.log('判断返回的结果:', judgeRet);
if (judgeRet.has && judgeRet.downloadStatus) {
console.log('已下载,直接阅读');
yield put({ type: 'reader/save', payload: { downloadStatus: true } });
return;
}
yield put({ type: 'common/save', payload: { loading: true } });
let { search: { detail } } = yield select();
if (!detail._id) {
console.log('下载时详情不存在,前往获取');
detail = yield call(readerServices.getDetail, id);
}
// 获得的所有书源
const sourceList = yield call(readerServices.getSource, id);
let sourceIndex = 0; // 标记书源当前脚标
let chapterList = []; // 初始化可用章节列表
// 循环获得一个可用的书源,达到自动换源的效果
for (let i = 0, len = sourceList.length; i < len; i += 1) {
if (sourceList[i].name !== '优质书源') {
const { chapters } = yield call(readerServices.getChapterList, sourceList[i]._id);
if (chapters.length) {
const { chapter, ok } = yield call(readerServices.getChapter, chapters[i].link);
if (ok && chapter) {
console.log(`成功获取一个书源 index: ${sourceIndex} 章节总数 ${chapters.length}`);
console.log('要下载的书源', sourceList[sourceIndex]);
// 成功获取一个书源,并将相关信息先存下来
yield put({ type: 'reader/save', payload: { source: sourceList, id, detail, chapters, chapter, downloadPercent: 0, currentSource: sourceIndex, currentChapter: 0 } });
chapterList = chapters;
break;
}
}
}
sourceIndex += 1;
}
// 开始循环章节获得章节内容,并保存在本地
const chaptersContent = []; // 章节列表及其内容
for (let i = 0, len = chapterList.length; i < len; i += 1) {
const { chapter } = yield call(readerServices.getChapter, chapterList[i].link);
chaptersContent[i] = chapter;
// 添加下载进度
yield put({ type: 'reader/save', payload: { downloadPercent: (i / len) * 100 } });
}
// 取消下载进度
yield put({ type: 'reader/save', payload: { downloadPercent: 0 } });
console.log('保存的章节内容', chaptersContent);
yield put({ type: 'reader/save', payload: { chaptersContent } });
// 没有下载
if (!judgeRet.downloadStatus) {
const { reader, store: { [id]: book }, search: { detail: searchDetail } } = yield select();
reader.downloadStatus = true; // 设定已下载
console.log('将书籍存入书架');
yield put({ type: 'store/put', payload: { ...reader }, key: id });
yield put({ type: 'reader/clear' });
if (book && book.detail && book.source) { // 如果原书架中有对应的书则取出,否则用当前的书
console.log(`从书架取回《${book.detail.title}》`);
yield put({ type: 'reader/save', payload: { ...book } });
} else {
console.log('原书架没书,用当前书');
yield put({ type: 'reader/save', payload: { ...reader } });
}
searchDetail.downloadStatus = true;
yield put({ type: 'search/save', payload: { searchDetail } });
}
}
} catch (error) {
console.log(error);
}
yield put({ type: 'common/save', payload: { loading: false } });
}
本地存储redux-persist
这里咱们使用了 redux-persist 来做本地存储,非常方便,redux先关数据自动存储和获取
- src/store/effects/reader.js
import { REHYDRATE } from 'redux-persist/constants';
/**
* 本地存储调用
* @param payload
*/
function* reStore({ payload }) {
try {
const { reader, store, setting } = payload;
yield put({ type: 'reader/save', payload: { ...reader } });
yield put({ type: 'store/save', payload: { ...store } });
yield put({ type: 'setting/save', payload: { ...setting } });
} catch (error) {
console.log(error);
}
}
export default [
takeLatest(REHYDRATE, reStore),
];
以上基本上已经完整实现了阅读器的核心部分,至于搜索和详情页,限于篇幅不再赘述。
UI部分
本想使用material-ui,但它实在是太重了,而我希望这个项目是轻量且高效的,最后还是决定自行设计ui。
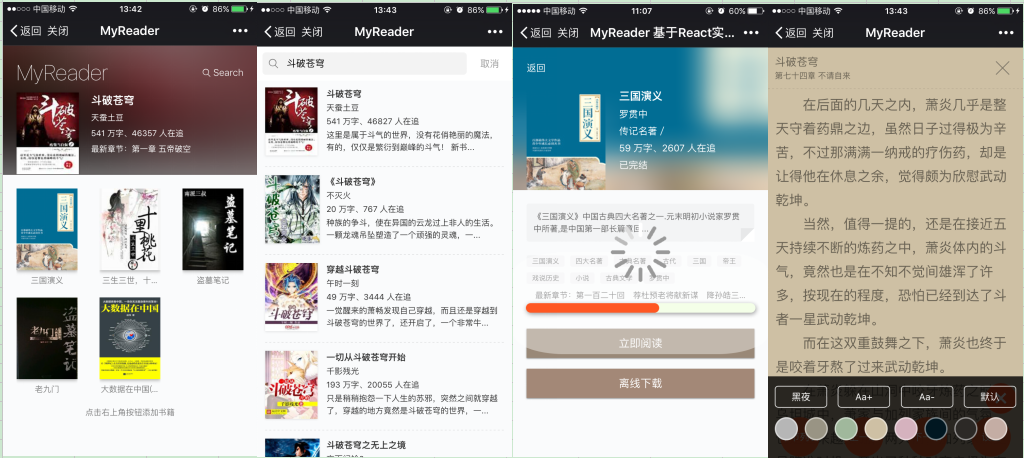
首页
首页比较纠结,曾经放了很多自以为炫酷的高斯模糊和动画,但过多的效果会降低体验,最终还是选择了走了简洁的路子。
上半部分是当前阅读书籍,仅显示一些关键信息。下半部分是书架,存放以往的阅读进度。
从redux获取数据
- src/routes/IndexPage/index.js
function mapStateToProps(state) {
const { detail } = state.reader;
const list = state.store;
const store = Object.keys(list).map((id) => {
// 找出书架上所有书籍的详细信息
return list[id] ? list[id].detail : {};
}).filter((i) => {
// 过滤掉异常数据和当前阅读
return i._id && i._id !== detail._id;
});
return {
store,
// 如果是一本书都没有,推荐src/utils/recommond.js的第一个《斗破苍穹》
current: detail._id ? detail : recommend,
};
}
阅读器
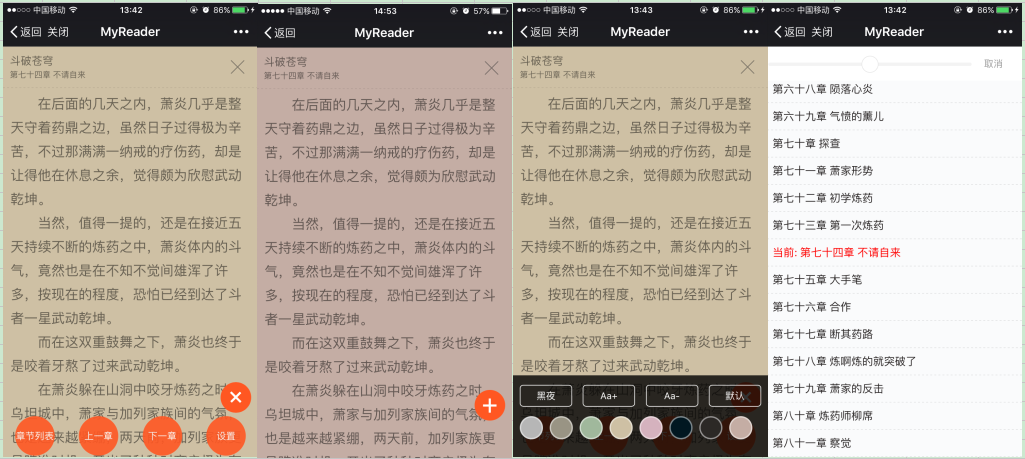
ok,扯了许久,终于见到本尊了,这是阅读器最核心的页面,谈不上有什么设计,就是追求简洁易用。
主体部分就是原生的body,这样滚动起来会非常流畅。需要注意下api提供的数据如何显示在react中。代码很短,大意就是将换行符作为依据转换成数组显示,这样方便设置css样式。
- src/routes/Reader/Content.js
export default ({ content, style }) => (<div className={styles.content} style={style}>
{ content && content.split('\n').map(i => <p>{i}</p>) }
</div>);
稍微体验下可以发现,头部可收缩,显示当前书籍和当前章节,以及一个关闭按钮。基于react-headroom组件实现。
为了追求简洁,我们把菜单做成一个可展开以及关闭的形式,点击右侧的按钮会在页面最下方显示出菜单,这样更方便随时可以查看下一章、上一章、章节列表、设置。
菜单只有4个,设置、章节列表、上一章和下一章。点击设置会弹出框,支持换肤和调节字体大小,这些只是基本的,有时间再做亮度调节自动翻页和语音朗读吧。实现方法很简单,贴出这段代码你一定秒懂。
- src/routes/Reader/Setting.js
this.stopEvent = (e) => {
// 阻止合成事件间的冒泡
e.stopPropagation();
// 阻止合成事件与最外层document上的事件间的冒泡
e.nativeEvent.stopImmediatePropagation();
e.preventDefault();
return false;
};
章节列表更(mei)加(you)简(yong)易(xin),稍微注意下如何将当前章节显示在列表中吧。我是利用锚点链接实现的,再配合一个sider组件,某修仙传几千章节跳转起来也很轻松。
- src/routes/Chapters/index.js
// 滑动顶部进度条 sider
this.skip = () => {
setTimeout(() => {
document.getElementById(this.range.value).scrollIntoView(false);
}, 100);
}
换肤
说起来很好实现,无非是先预设一套主题参数,需要哪个点那个。
- src/utils/constants.js
export const COLORS = [
{
background: '#b6b6b6',
}, {
background: '#999484',
}, {
background: '#a0b89c',
}, {
background: '#cec0a4',
}, {
background: '#d5b2be',
}, {
color: 'rgba(255,255,255,0.8)',
background: '#011721',
}, {
color: 'rgba(255,255,255,0.7)',
background: '#2c2926',
}, {
background: '#c4ada4',
},
];
在redux中维护一个setting字段,专门放用户设置。在阅读器中获取并设置为主题即可。
- src/routes/Reader/index.js
function mapStateToProps(state) {
const { chapter, chapters, currentChapter = 0, detail, menuState } = state.reader;
const { logs } = state.common;
return {
logs,
chapter,
chapters,
detail,
currentChapter,
menuState,
...state.setting,
};
}
切换皮肤的时候将新的数据保存到redux就实现了换肤功能。
- src/routes/Reader/Setting.js
// 设置主题颜色
this.setThemeColor = (key, val) => {
this.props.dispatch({
type: 'setting/save',
payload: {
[key]: val,
},
});
};
// 调整字体大小
this.setFontSize = (num) => {
const fontSize = this.props.style.fontSize + num;
this.props.dispatch({
type: 'setting/save',
payload: {
style: {
...this.props.style,
fontSize,
},
},
});
};
删除实现
为了不再增加新的ui,决定使用长按删除。但是这个列表不仅需要支持长按和短按,还需要支持滚动,我又不想使用hammer.js这种重型库,只得手写了一个同时支持长按和短按的组件。
- src/components/Touch/index.js
export default ({ children, onPress, onTap }) => {
let timeout;
let pressed = false;
let cancel = false;
function touchStart() {
timeout = setTimeout(() => {
pressed = true;
if (onPress) onPress();
}, 500);
return false;
}
function touchEnd() {
clearTimeout(timeout);
if (pressed) {
pressed = false;
return;
}
if (cancel) {
cancel = false;
return;
}
if (onTap) onTap();
return false;
}
function touchCancel() {
cancel = true;
}
return (<div
onTouchMove={touchCancel}
onTouchCancel={touchCancel}
onTouchStart={touchStart}
onTouchEnd={touchEnd}
>
{ children }
</div>);
};
至于长按弹窗的ui我懒得设计了,短时间也做不出什么好的效果,还是继续使用sweet-alert2吧,这个插件着实不错。
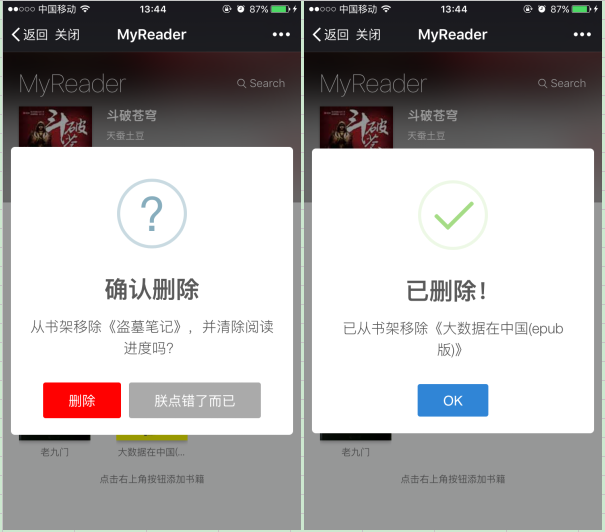
至此我们已经实现了全部功能和ui。
优化
移动端优化
<meta content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=0;" name="viewport" />
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<meta name="apple-mobile-web-app-capable" content="yes">
// 这个比较重要,可以在ios系统自带safari中添加到主屏幕,这条设置会启用全屏模式,体验不错
<meta name="apple-mobile-web-app-status-bar-style" content="black">
<link rel="apple-touch-icon-precomposed" href="icon.png"/>
<link rel="apple-touch-startup-image" sizes="2048x1496" href="">
<link rel="apple-touch-icon" href="icon.png"/>
CSS
* {
user-select: none;
// 禁止用户选中文本
-webkit-appearance: none;
// 改变按钮默认风格
-webkit-touch-callout: none;
// 禁用系统默认菜单
}
input {
user-select: auto;
-webkit-touch-callout: auto;
// 解除对input组件的限制,否则无法正常输入
}
fetch-polyfill
解决fetch浏览器不兼容问题
- src/utils/request.js
import 'fetch-polyfill';
fastclick
如果 viewport meta 标签 中设置了 width=device-width, Android 上的 Chrome 32+ 会禁用 300ms 延时。
- myreader/src/router.js
import FastClick from 'fastclick';
FastClick.attach(document.body);
你懂得,移除移动端300毫秒延迟,不过这会带来其他问题,比如长按事件异常,滚动事件异常什么的。因为滑动touchmove触发了touchend事件,需要先取消掉touchstart上挂载的动作。
体积减小
项目初期打包后竟然有700k+,首次加载速度不忍直视。前面已经提到,放弃各种框架和动画之后,体积已经大幅减少。不过有react,react-router,redux,redux-saga这些依赖在,体积再小也小不到那里去。但好消息是我们可以使用preact替换react,从而节省约120kb左右。
只需要安装preact并设置别名即可。此处有几个小坑,一是别名的第三句,找了好久才在有个issue下发现,没有就无法运行。二是preact和react-hot-loader不太兼容,一起用会导致热更新失效。三是preact仍然有不兼容react的地方,需要仔细验证。
npm i -S preact preact-compat
resolve: {
alias: {
react: 'preact-compat',
'react-dom': 'preact-compat',
'preact-compat': 'preact-compat/dist/preact-compat',
//比较坑的是最后一句官网并未给出,导致一直报错,找了很久
},
},
以及一系列优化以及gzip之后,项目index.js减小到了240kb,相比初期只有十分之一大小。
最后
后记
项目中所有数据来自追书神器,非常感谢!!
喜欢的同学可以star哦,欢迎提出建议。
本项目仅作用于在实战中学习前端技术,请勿他用。
线上环境
- 这里使用node环境做本地server,启动: node server.js &
在线地址:MyReader
cnpm i -D babel-core babel-eslint babel-loader babel-preset-es2015 babel-preset-stage-0 babel-preset-react webpack webpack-dev-server html-webpack-plugin eslint@^3.19.0 eslint-plugin-import eslint-loader eslint-config-airbnb eslint-plugin-jsx-a11y eslint-plugin-react babel-plugin-import file-loader babel-plugin-transform-runtime babel-plugin-transform-remove-console redux-devtools style-loader less-loader css-loader postcss-loader autoprefixer rimraf extract-text-webpack-plugin copy-webpack-plugin react-hot-loader@next less
cnpm i -S react react-dom react-router react-router-dom redux react-redux redux-saga material-ui@next material-ui-icons fetch-polyfill
cnpm i -S preact preact-compat react-router react-router-dom redux react-redux redux-saga
proxy: {
'/api': {
target: 'http://api.zhuishushenqi.com/',
changeOrigin: true,
pathRewrite: { '^/api': '' },
},
'/chapter': {
target: 'http://chapter2.zhuishushenqi.com/',
changeOrigin: true,
pathRewrite: { '^/api': '' },
},
'/agent': {
target: 'http://statics.zhuishushenqi.com/',
changeOrigin: true,
pathRewrite: { '^/api': '' },
},
},
License
(The MIT License)
Copyright (c) 2017 linxins liufulin90@163.com
基于React实现的【绿色版电子书阅读器】,支持离线下载
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· Windows编程----内核对象竟然如此简单?