
Spark GraphX 的数据可视化
概述
详细
Spark 和 GraphX 对并不提供对数据可视化的支持, 它们所关注的是数据处理。但是, 一图胜千言, 尤其是在数据分析时。接下来, 我们构建一个可视化分析图的 Spark 应用。需要用到的第三方库有:
-
GraphStream: 用于画出网络图
-
BreezeViz: 用户绘制图的结构化信息, 比如度的分布。
这些第三方库尽管并不完美, 而且有些限制, 但是相对稳定和易于使用。
一、安装 GraphStream 和 BreezeViz
因为我们只需要绘制静态网络, 所以下载 core 和 UI 两个 JAR 就可以了。
-
gs-core-1.2.jar(请看下载的压缩包里的jars.zip)
-
gs-ui-1.2.jar(请看下载的压缩包里的jars.zip
breeze 也需要两个 JAR:
-
breeze_2.10-0.9.jar(请看下载的压缩包里的jars.zip
-
breeze-viz_2.10-0.9.jar(请看下载的压缩包里的jars.zip
由于 BreezeViz 是一个 Scala 库, 它依赖了另一个叫做 JfreeChart 的 Java 库, 所以也需要安装:
-
jcommon-1.0.16.jar(请看下载的压缩包里的jars.zip
-
jfreechart-1.0.13.jar(请看下载的压缩包里的jars.zip
可以到 maven 仓库去下载, 下载完成后放到项目根目录下 lib 文件夹下即可. 用 sbt 来管理依赖比较方便, 所以我使用 sbt 来安装这些依赖:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | // Graph Visualization// https://mvnrepository.com/artifact/org.graphstream/gs-corelibraryDependencies += "org.graphstream" % "gs-core" % "1.2"// https://mvnrepository.com/artifact/org.graphstream/gs-uilibraryDependencies += "org.graphstream" % "gs-ui" % "1.2"// https://mvnrepository.com/artifact/org.scalanlp/breeze_2.10libraryDependencies += "org.scalanlp" % "breeze_2.11" % "0.12"// https://mvnrepository.com/artifact/org.scalanlp/breeze-viz_2.11libraryDependencies += "org.scalanlp" % "breeze-viz_2.11" % "0.12"// https://mvnrepository.com/artifact/org.jfree/jcommonlibraryDependencies += "org.jfree" % "jcommon" % "1.0.24"// https://mvnrepository.com/artifact/org.jfree/jfreechartlibraryDependencies += "org.jfree" % "jfreechart" % "1.0.19" |
二、画图
一、导入
在导入环节需要注意的是, 如果是与 GraphX 的 Graph 一同使用, 在导入时将 graphstream 的 Graph 重命名为 GraphStream, 否则都叫 Graph 会有命名空间上的冲突。当然, 如果只使用一个就无所谓了。
1 | import org.graphstream.graph.{Graph => GraphStream} |
二、绘制
首先是使用 GraphX 加载一个图, 然后将这个图的信息导入 graphstream 的图中进行可视化. 具体是:
1、创建一个 SingleGraph 对象, 它来自 graphstream:
1 | val graph: SingleGraph = new SingleGraph("visualizationDemo") |
2、我们可以调用 SingleGraph 的 addNode 和 addEdge 方法来添加节点和边, 也可以调用 addAttribute 方法来给图, 或是单独的边和顶点来设置可视化属性. graphsteam API 非常好的一点是, 它将图的结构和可视化用一个类 CSS 的样式文件完全分离了开来, 我们可以通过这个样式文件来控制可视化的方式. 比如, 我们新建一个 stylesheet 文件并放到用户目录下的 style 文件下面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | node { fill-color: #a1d99b; size: 20px; text-size: 12; text-alignment: at-right; text-padding: 2; text-background-color: #fff7bc;}edge { shape: cubic-curve; fill-color: #dd1c77; z-index: 0; text-background-mode: rounded-box; text-background-color: #fff7bc; text-alignment: above; text-padding: 2; } |
上面的样式文件定义了节点与边的样式, 更多内容可见其官方文档.
准备好样式文件以后, 就可以使用它:
1 2 3 4 | // Set up the visual attributes for graph visualizationgraph.addAttribute("ui.stylesheet","url(file:/home/xlc/style/stylesheet)")graph.addAttribute("ui.quality")graph.addAttribute("ui.antialias") |
ui.quality 和 ui.antialias 属性是告诉渲染引擎在渲染时以质量为先而非速度。 如果不设置样式文件, 顶点与边默认渲染出来的效果是黑色。
3、加入节点和边。将 GraphX 所构建图的 VertexRDD 和 EdgeRDD 里面的内容加入到 GraphStream 的图对象中:
1 2 3 4 5 6 7 8 | // Given the egoNetwork, load the graphX vertices into GraphStreamfor ((id,_) <- egoNetwork.vertices.collect()) { val node = graph.addNode(id.toString).asInstanceOf[SingleNode]}// Load the graphX edges into GraphStream edgesfor (Edge(x,y,_) <- egoNetwork.edges.collect()) { val edge = graph.addEdge(x.toString ++ y.toString, x.toString, y.toString, true).asInstanceOf[AbstractEdge]} |
加入顶点时, 只需要将顶点的 vertex ID 转换成字符串传入即可。
对于边, 稍显麻烦。addEdge 的 API 文档在 这里, 我们需要传入 4 个参数。第一个参数是每条边的字符串标识符, 由于在 GraphX 原有的图中并不存在, 所以我们需要自己创建。最简单的方式是将这条边的两个端点的 vertex ID 连接起来。
注意, 在上面的代码中, 为了避免我们的 scala 代码与 Java 库 GraphStream 互用上的一些问题, 采用了小的技巧。在 GraphStream 的 org.graphstream.graph.implementations.AbstractGraph API o文档中, addNode 和 addEdge 分别返回顶点和边。但是由于 GraphStream 是一个第三方的 Java 库, 我们必须强制使用 asInstanceOf[T], 其中 [T] 为 SingleNode 和 AbstractEdge, 作为 addNode 和 addEdge 的返回类型。 如果我们漏掉了这些显式的类型转换, 可能会得到一个奇怪的异常:
1 2 3 | java.lang.ClassCastException:org.graphstream.graph.implementations.SingleNode cannotbe cast to scala.runtime.Nothing$ |
4、显示图像
1 | graph.display() |
5、部分示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | def main(args: Array[String]): Unit = { val sparkConf = new SparkConf() .setAppName("GraphStreamDemo") .set("spark.master", "local[*]") val sc = new SparkContext(sparkConf) val graph: SingleGraph = new SingleGraph("graphDemo") val vertices: RDD[(VertexId, String)] = sc.parallelize(List( (1L, "A"), (2L, "B"), (3L, "C"), (4L, "D"), (5L, "E"), (6L, "F"), (7L, "G"))) val edges: RDD[Edge[String]] = sc.parallelize(List( Edge(1L, 2L, "1-2"), Edge(1L, 3L, "1-3"), Edge(2L, 4L, "2-4"), Edge(3L, 5L, "3-5"), Edge(3L, 6L, "3-6"), Edge(5L, 7L, "5-7"), Edge(6L, 7L, "6-7"))) |
三、运行效果与文件截图
1、运行效果:
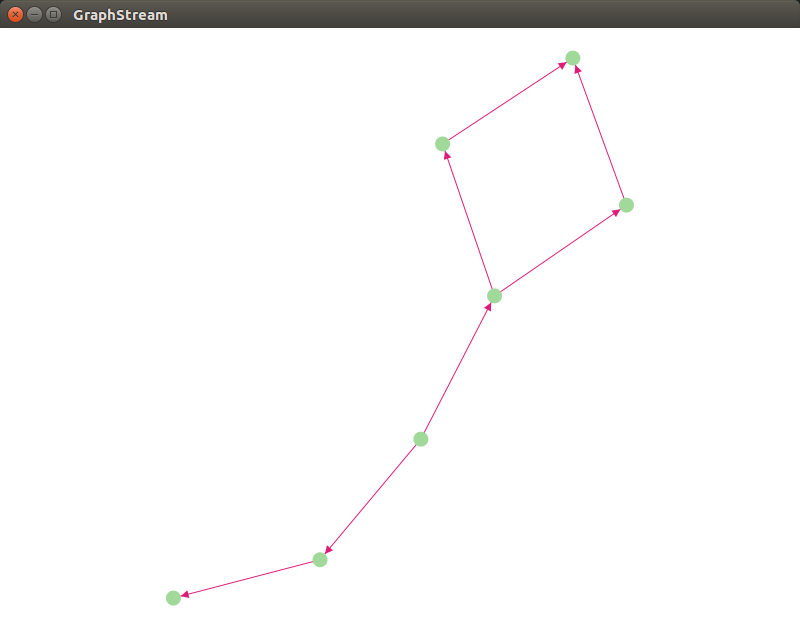
至此, 一个简单的示例完成. 更多实用的内容可自行研究。
2、文件截图:

四、其他补充
目前, 如果不消耗大量的计算资源, 对于大规模的网络图绘制仍然缺乏一个有力的工具. 类似的工具有:
另外, zeepelin 也可与 Spark 集成, 可自行了解。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· Windows编程----内核对象竟然如此简单?