
【面试复习】数据库 - redis(下)
1、缓存设计可能遇见的问题与解决方案
1.1、缓存穿透: 当一个请求数据,在缓存中查不到数据,请求就会跑去db查找;如果同时有大量的无效请求过来,在缓存中都查不到数据,就会穿透缓存来到db,最终造成db负载过重,拖垮db,这就是缓存穿透。 解决缓存穿透的方案本质上是找出这类无效请求:(1)对于数据key值比较固定的数据,可以考虑使用布隆过滤器;(2)添加验证码去掉部分机器请求;(3)通过引入安全旁路,或者风控,对于多次重复的请求,将这些请求的特征值在redis中缓存下来;(4)降级
1.2、缓存失效: 多个数据从db缓存到redis时,设计了相同的过期时间,这可能会导致,在某一个时刻,很多key同时失效,然后一瞬间众多情况会同时来到db,又会给db造成压力。
1.3、缓存雪崩: 当缓存层宕机了以后,所有的请求就会直接打到db层,直接会压垮db层,像雪崩一样引发连锁反应。解决方案:redis变为高可用的,使用redis cluster;组件限流并降级;提前压测
1.4、热点缓存key重建问题:当某个key突然成为热点key,即大量请求来访问db,并且去redis重建热点key的缓存,可能会造成后端程序负载过大,可能会让应用崩溃。解决方案:利用分布式互斥锁,只允许一个线程执行,取db数据,重建redis缓存。伪代码如下:
String get(String key){ String value = redis.get(key); if(value == null){ String lockName = "mutex:key:" + key; if(redis.setNx(lockName, "1", "ex 180")){ value = db.get(key); redis.setex(key, value, timeout); redis.delete(lockName); }else{ sleep(50); get(key); } } return value; }
1.5 布隆过滤器
布隆过滤器将db中所有的key值,通过多个hash函数,映射到一个bitmap数组中。最终达成通过布隆过滤器的key,db中不一定有,但是没通过布隆过滤器的db里面一定没有。
2、redis分布式锁
考虑利用redis设计一个分布式锁:利用 setnx 或者 hsetnx 命令,setnx、hsetnx 往缓存中存值,如果缓存中已经有值,则返回失败。可以很简单设计出如下代码:
String doSomething(String key){ String mutexName = "mutex:key:" + key; String mutexValue = ToString(time(null)) + RandNum(10); int timeout = 30000; while(!redis.setNx(mutexName, mutexValue, timeout)){ sleep(50); } try{ //... do something ... }catch{ ... }finally{ // 每一次拿锁时都设置一个随机value,释放锁时确认下value值,防止释放了别的程序的锁 if(redis.get(mutexName) == mutexValue){ redis.delete(mutexName); } } ... }
有意思的是,此时的timeout 如何设计?考虑到实际的业务代码可能执行时间可能长于锁的过期时间,可以考虑将锁设置较长的过期时间,可是这样会面临另一个问题,如果程序加锁成功后宕机了,此时其他的线程则不得不等待锁自动过期,这样看来锁超时时间也不能设计的过于长。
可以看下redisson是如何设计解决这个问题的:
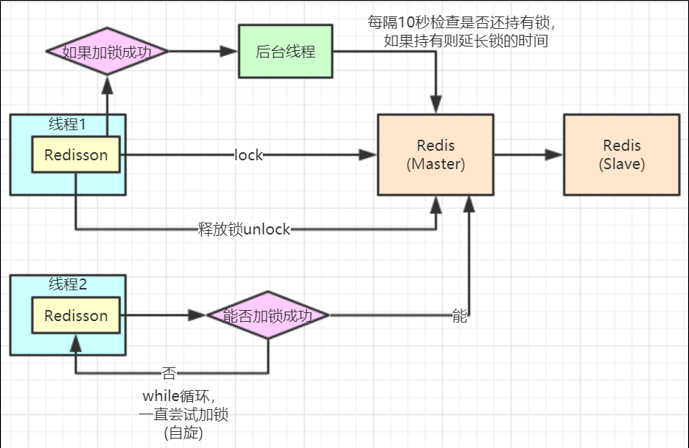
在主线程加锁的同时,后台新开一个线程一直再给锁续命,如果过期时间为30s,则每隔10秒给锁续命一次。
3、redis开发规则与性能优化
3.1、key名的设计
可读性和可管理性: 业务名:表名:id;简洁性:key长度不宜过长,内存很贵的;不要包含特殊字符;
3.2、value的设计
拒绝bigkey;关于bigkey的定义:字符串类型:单个value值超过10k就是bigkey;非字符串类型:元数个数超过5000就是bigkey;
对于非字符串的bigkey(比较常见),不要执行整个key的del操作,也不要设置这个key的超时时间(超时时间到了有可能会触发del操作),取值时尽量不要key下面的全体,例如不要用hgetall,去使用hmget;还有一种就是将bigkey进行拆分。
3.3、选择合适的数据类型
3.4、控制key的生命周期
3.5、O(N) 命令关注N的数量,hgetall、Irange、smembers、zrange、sinter这些命令尽量使用 hscan、sscan、zscan 代替
3.6、禁用命令:keys、flushall、flushdb等,通过redis的rename机制禁掉命令,或者使用scan方式渐进式处理。
3.7、使用批量命令提高效率 原生:mget、mset;非原生:pipeline
3.8、redis事务较弱建议使用lua代替
3.9、客户端使用连接池
连接池参数的设置:
maxTotal:一个客户端与redis服务器之间的最大连接数
maxIdle、minIdle: maxIdle是业务需要的最大连接数,maxTotal是为了给出余量,一般推荐maxIdle设置为业务期望QPS所需连接数,maxTotal可以放大一倍。minIdle:最小空闲连接数。
如果系统马上会有很多请求过来,可以考虑给redis连接池做预热
3.10、高并发下可以考虑给客户端添加熔断功能
3.11、redis 过期键的三种清除策略:
被动删除:当一个过期key被读写时,会触发惰性删除策略,直接删除这个过期key
主动删除:redis会定期删除一批已经过期的key
主动清理:当内存超过maxmemory时,触发主动清理

