

分钟级在线深度学习在手淘信息流排序模型中的探索与实践
作者:淘宝技术
链接:分钟级在线深度学习在手淘信息流排序模型中的探索与实践
这篇文章实践性很好,值得学习~
前些年流行的FTRL等在线学习算法在深度学习中已不太适用,为此信息流推荐算法团队从2019年开始探索在线学习的下一式——在线深度学习(Online Deep Learning, ODL),在首页商品信息流全量小时级在线深度学习,使得在线排序模型可以学习到1小时前平台上的用户和商家最新流行的数据模式。2020年团队又继续探索分钟级在线深度学习,把排序模型发现平台用户和商家最新流行的数据模式的延迟降低到分钟级。
 图1 在线学习应用场景:首页商品信息流(左图),视频信息流(右图)
图1 在线学习应用场景:首页商品信息流(左图),视频信息流(右图)
在线学习的重要性
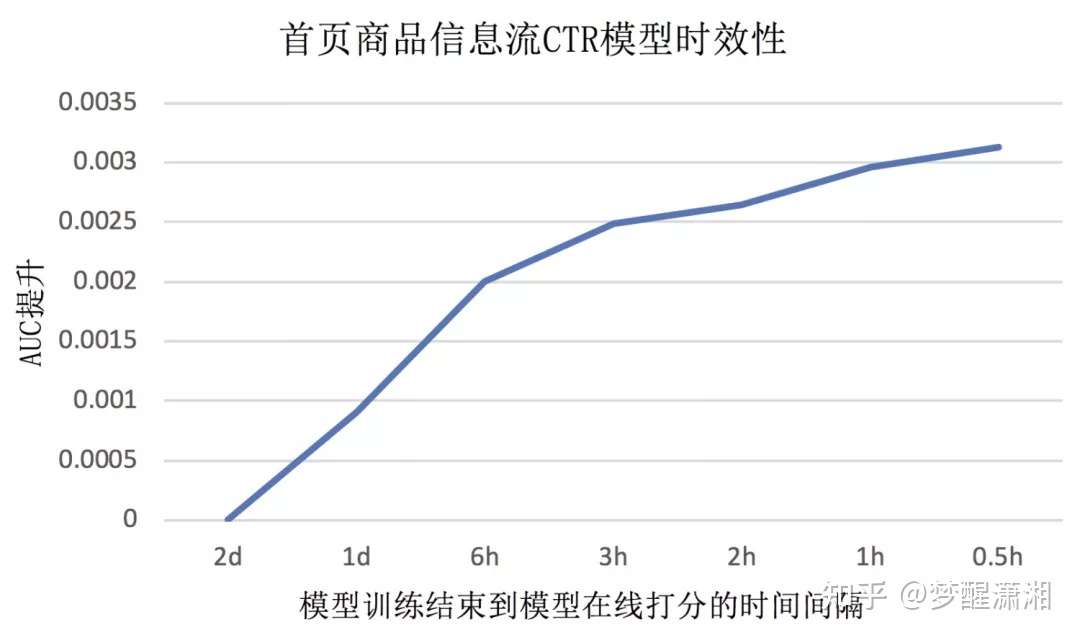 图2 首页商品信息流CTR模型时效性效果分析(日常)
图2 首页商品信息流CTR模型时效性效果分析(日常)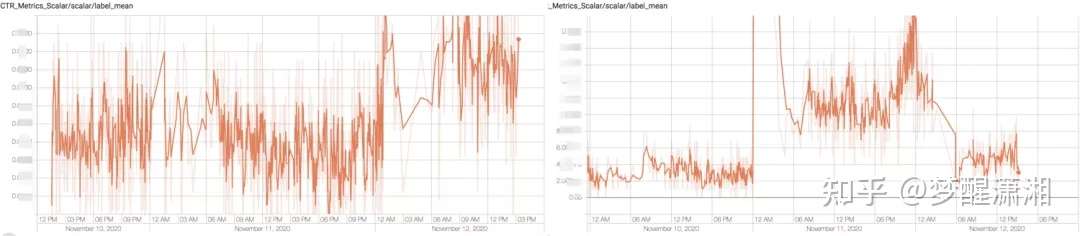 图3 双十一期间首页商品信息流CTR(左图)和CVR(右图)的label mean随时间变化
图3 双十一期间首页商品信息流CTR(左图)和CVR(右图)的label mean随时间变化
图2展示了首页商品信息流CTR模型效果随着时效性的变化趋势图,其中横轴代表模型训练结束到模型在线打分的时间间隔,纵轴是AUC提升的绝对值(相对于模型训练结束到模型在线打分的时间间隔为2天的批模型)。从图中可以看着,模型的效果与模型的时效性成正相关,模型更新得越频繁,实时性越好,AUC越高,效果越好。图3展示了双十一前后用户和商品行为发生了剧烈的变化,尤其是CVR在双十一当天是预热期的5倍,同一天内不同时间段CTR和CVR也不同,传统离线批训练天级更新的模型不能技术捕获到用户和商品行为的实时变化。
从用户体验角度来讲,用户在手淘流量商品时,用户的期望是更快地找到与自己兴趣符合的商品,只要推荐系统能感知用户反馈、实时的满足用户的期望,就能提升推荐的效果。
从算法技术角度来讲,推荐系统更实时意味着推荐系统能更快更准确的表达用户最新的习惯和兴趣,以及从全局角度更快发现人群的偏好和最新的流行趋势,这两个方面分别对应了推荐系统样本特征的实时性和模型的实时性。
样本特征的实时性
样本特征的实时性包括在线系统实时计算和更新模型的输入特征,使得模型总能使用最新的特征进行预测和推荐,以及日志采集和样本构建系统实时采集用户行为并生成实时流式训练样本。其中我们把在线系统实时特征(实时行为序列、实时交叉统计特征等等)的计算和更新归类为模型结构优化的工作,不在本文介绍的工作范畴;本文着重介绍我们在实时流式样本构建和利用实时流式样本就是流式训练上的探索。
▐ 实时流式样本生成
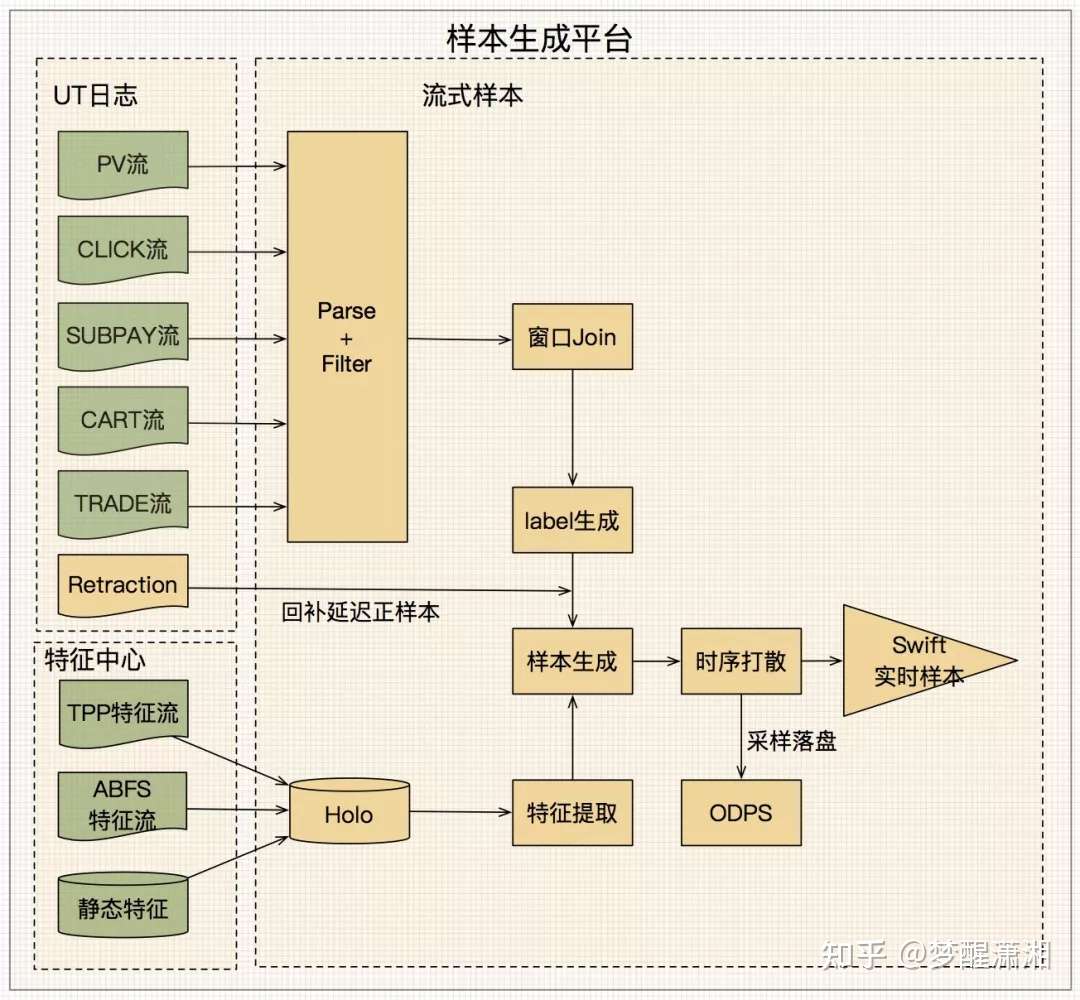 图4 实时流式样本生成
图4 实时流式样本生成
图4展示了实时流式训练样本的生成过程,样本生成平台通过统一的Event解析对应的用户行为数据流,包括曝光曝光(PV)、点击(Click)、预售付定金(subPay)、加购(Cart)、成交(Trade)等行为;通过blink与埋点特征流以及存储在Holo上的非埋点特征等Entity进行实时join,从而生成实时样本,最后实时样本通过Swift消息队列进行存储。
▐ 延迟反馈建模
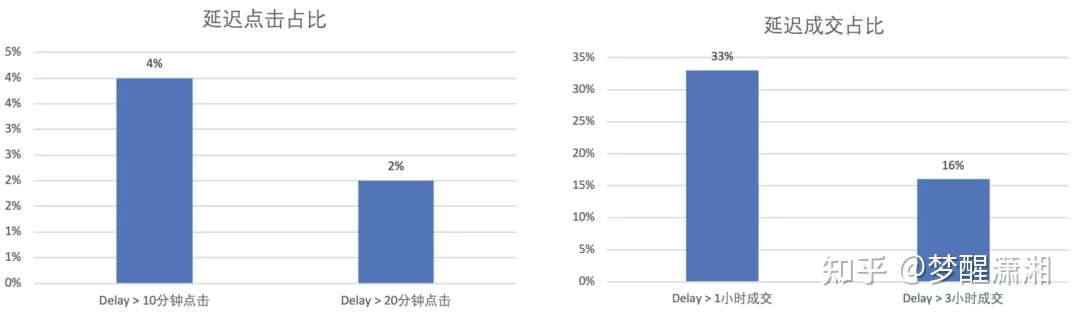 图5 CTR和CVR延迟反馈
图5 CTR和CVR延迟反馈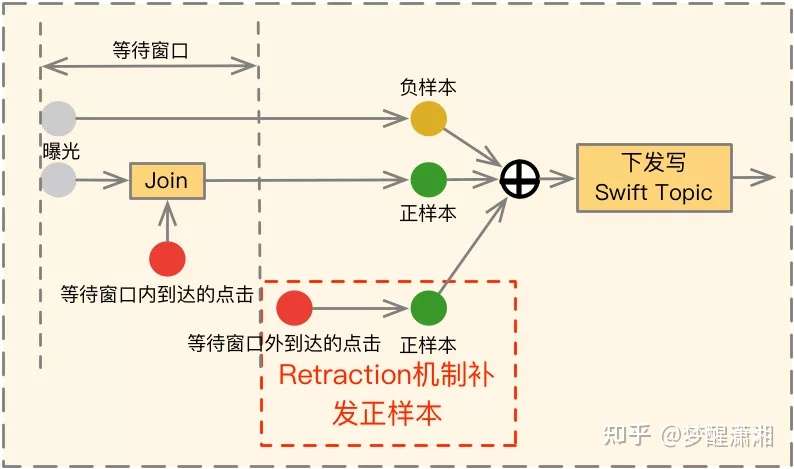 图6 窗口Join和Retraction机制
图6 窗口Join和Retraction机制
在实时流式样本中,通常正例会延迟于负例到达,如图5所示,在首页商品信息流推荐中,CTR模型有4%的点击会在曝光10min后到达,甚至还有2%的点击会在曝光20min后到达;CVR模型中正样本延迟的问题更加严重,该问题我们称之为延迟反馈问题。
对该问题有不少研究工作,一些工作倾向于保证label的准确性而让负例长时间等待正例来解决,另一些工作倾向于保障数据的新鲜性而在负例到达时先让模型消费,然后在之后正例到来时在进行修正。
我们采用的是一种在等待更准确label与使用新鲜数据之间的折中方案,如图6所示,我们在平台上设置了一个等到窗口T,让每一个到达的负例都等待T时间,如果T时间窗口内有正例到达,则下发一条正样本,否则下发一条负样本;此外我们进一步引入Retraction机制来对T窗口之外到达的正例补发正样本,同时打上Retraction的标。
对于打上Retraction的标的补发正样本,我们采用PU Loss对其训练进行修正,核心思想就是对于这部分Retraction的样本,除了使用正样本进行梯度下降,还会对相应的负样本进行一个反向的梯度下降,抵消之前观察到为负样本对loss的影响。其中等待时间窗口T的设定对模型效果有一定的影响,通过实验来选择合适的窗口。
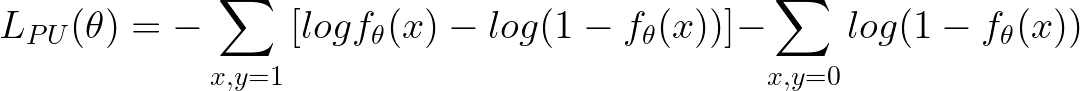
▐ 特征独立同分布
机器学习算法有一个独立同分布的基本假设,即模型训练的数据分布要与预测时的数据分布独立同分布。一些时间特征比如week和hour,在离线批样本中由于被充分shuffle过,使用这些特征训练出来的模型依然能保障训练和预测独立同分布,但是在实时流式训练中,样本实时顺序到达的,这类特征无法被充分shuffle,使得模型训练一直在训练同一个时刻的特征值,而预测时可能切换到下一个时刻的特征值,导致模型泛化能力差。
图6是我们实验的对同一批样本修改hour的特征值对CTR批模型和流模型预估值的影响,可以看到在流模型中使用不同的hour特征值,模型预估值波动非常大,模型对hour特征过拟合,对下一个时刻没有泛化能力。在我们的实践中,我们在流模型中统一将这类特征的值和梯度置0(批模型不改),以保障模型的稳定性。
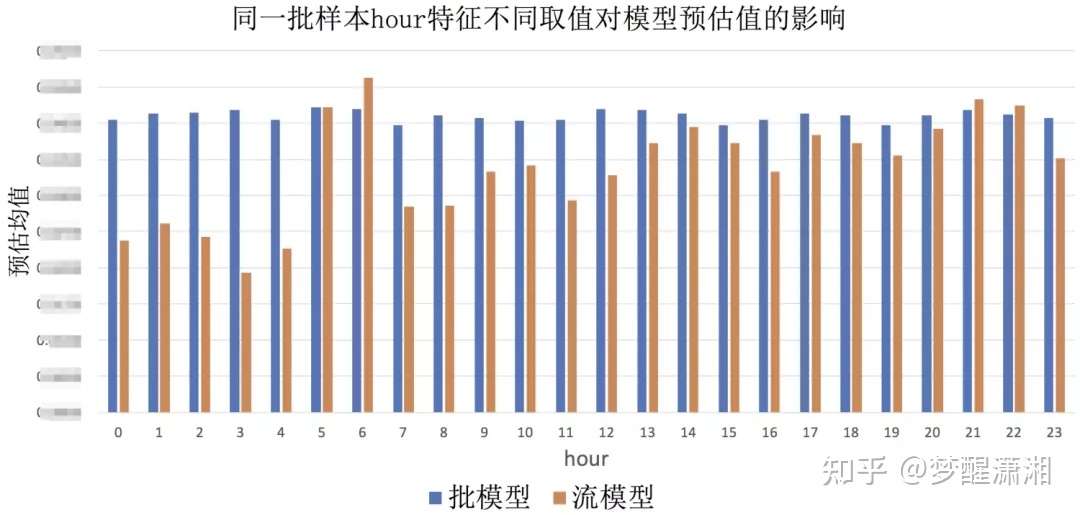 图7 同一批样本hour特征不同取值对模型预估值的影响
图7 同一批样本hour特征不同取值对模型预估值的影响
模型训练更新的实时性
模型训练时流模型首先通过restore离线批训练最新的模型版本作为实时流式训练的初始化模型,读取消费Swift消息队列的训练样本流式训练模型。训练平台上的模型会定时生成模型版本(checkpoint)到HDFS上,然后发布至在线打分平台,在线打分平台上接收到模型版本之后会先通过BuildService转换成在线打分的模型表,并load到在线机器的内存中进行在线打分服务。
▐ 批流结合训练
实时流式训练的在线学习模型具有时效性强,能捕捉数据分布的实时变化,更快发现人群的偏好和最新的流行趋势;然而由于上一章节介绍的延迟反馈问题以及特征独立同分布问题,流模型的训练样本label存在一定比例的错误,并且丢失了类似week和clock等时间特征,模型相比于离线批训练模型处于欠拟合状态。
而离线批训练模型由于样本是天级组织,label准度高,而且数据被重复shuffle过,可以弥补流模型存在的问题。因此我们结合批模型和流模型的有点,设计了批流结合的在线学习方案:定期从最新的批模型恢复重新流式训练流模型。
图8展示了每周从批模型重启一次的批流结合模型和持续流式训练的流模型在一个月的效果对比,可以看到批流结合的训练方式效果要优于持续流式训练的方式,持续流式训练的方式由于延迟反馈问题以及特征独立同分布问题会损失一定的效果,但是损失的该部分效果会趋向于稳定。
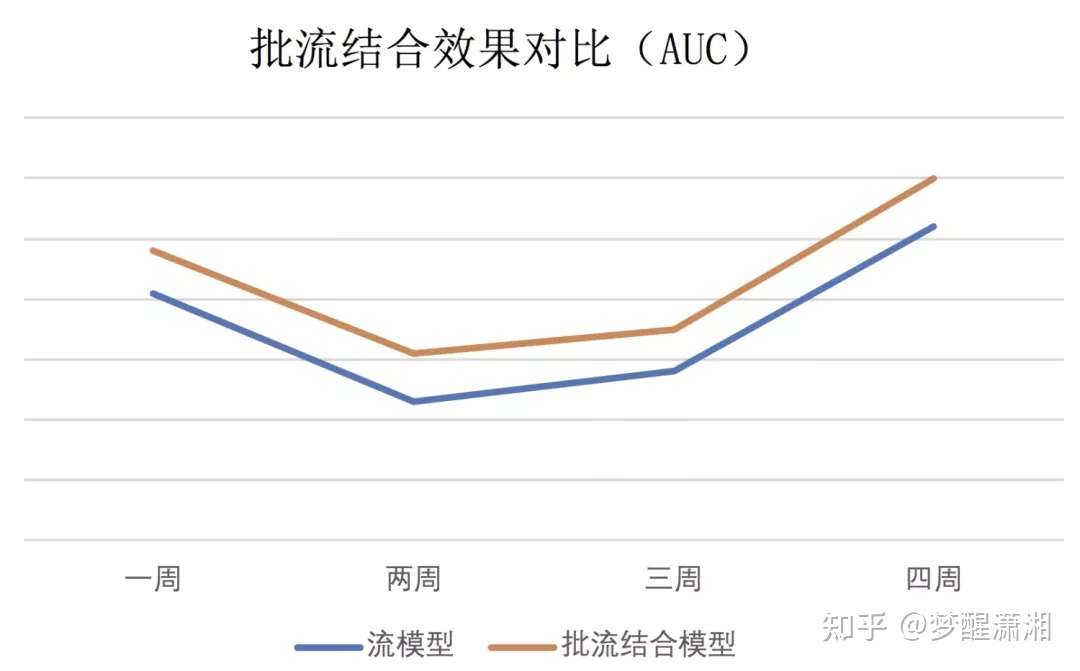 图8 批流结合效果对比
图8 批流结合效果对比
▐ 小时级模型更新
由于大规模深度排序模型的规模非常大(checkpoint大小 > 500G),按照传统模型更新的方式:生成checkpoint->推送到在线打分平台->BuildService生成模型表->在线打分平台加载模型表到内存,这整个过程需要1个多小时,因此最多只能做到小时级别的模型更新。2019年我们在深度排序模型做在线学习时,采用的就是这种更新方式,训练平台小时级定时的生成checkpoint和自动推送到在线打分平台来完成流式训练模型的在线更新。
▐ PS直发分钟级模型更新
2020年信息流算法团队通过与算法工程团队同学合作,构建了PS直发的分钟级在线学习方案。深度排序的规模大主要是模型中包含一些大规模的Sparse参数,比如UserId、ItemID、PID等的embedding。与Dense参数不同,Sparse参数虽然总体规模庞大,但是不是每一次的训练迭代都会更新所有的Sparse参数,比如ItemID的embedding参数,每个训练的batch中涉及的到ItemID就只有几万个,占整个参数空间的一小部分。
在首猜的CTR大模型中,checkpoint大小>500G,但是每15min被更新的参数只有30多G的Sparse参数被更新(不包括梯度等在线推理不需要的参数),在线模型只需要在每15min更新这个窗口内更新的特征,就可以大大减少每次更新的参数规模,提升在线模型更新的效率,从而提高模型的时效性。
模型参数的增量更新有通过Diff Checkpoint的参数Diff收集更新的参数、在PS中维护HashMap记录更新的参数并通过PS直发等多套技术方案,最终我们采样更新效率最高的PS直发技术。
PS直发的具体实现是:对于SparseTensor会在每个PS上分别维护一个HashMap记录更新的ID和频次,每隔一定的时间间隔,由每个PS各种收集在这个时间间隔内更新的ID对应的参数,并行的写入到Swift Topic中;而对应非SparseTensor的参数,比如MLP权重和非Sparse的特征,由于其基本都是全部更新,由Chief Worker统一从各个PS上拉取这些参数并拼装成完整的参数再写入到Swift Topic中。
虽然SpareTensor是在PS上直发,但是Chief Worker在整个发送过程中起了协调和触发的作用,Chief 每次发送之前都会向Swift发送一个开始写的信号,在PS和Chief都完成参数发送后再发送一个写结束的信号。Swift会将这个写信号开始(startTime)和结束(endTime)之间的参数当作一个整体来看待,从而保证了参数的一致性。首猜商品CTR模型的分钟级更新采用了15min的时间间隔,每15min进行一次PS参数直发,发送参数规模在30G左右,在半分钟左右就能完成全部参数的发送。
在线打分平台上的Processor会读取Swift Topic上的参数,并将参数直接发送到Searcher,在Searcher上开辟一段实时内存来让参数实时生效;与此同时还会进一步将参数发送到BuildServer,构建出一个增量的索引,再次发送到Searcher上,Searcher收到这个索引之后会清掉实时内存中的这部分参数,以降低实时内存的消耗。
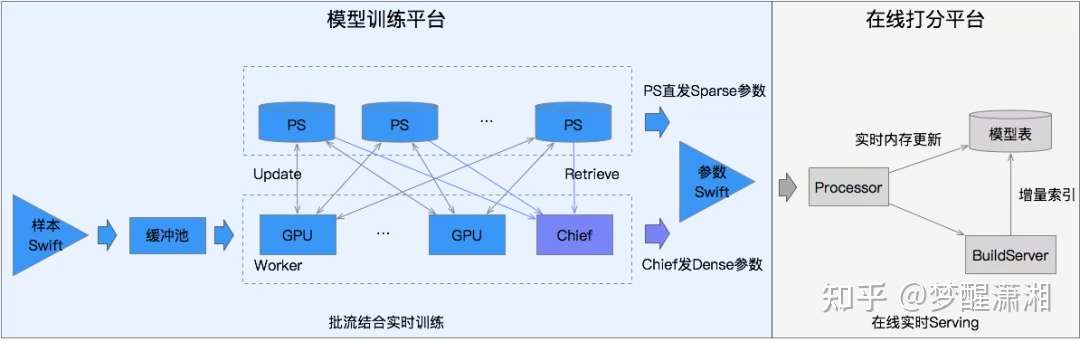 图8 PS直发分钟级模型更新
图8 PS直发分钟级模型更新
在线学习质量保障
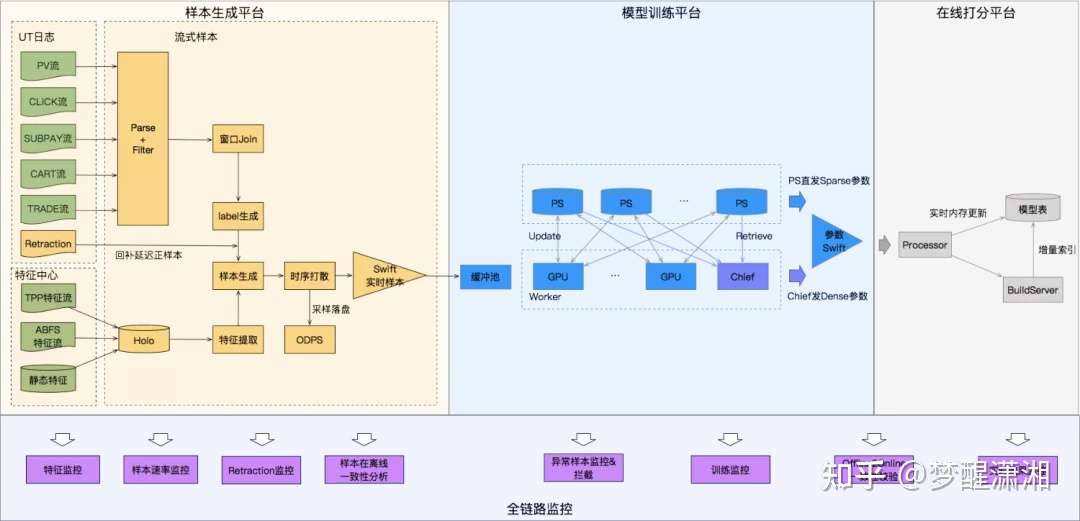 图9 首页信息流在线学习全貌
图9 首页信息流在线学习全貌
▐ 样本质量
样本数据作为机器学习的基石,其质量的好坏直接决定了模型效果的上限,特征对于在线学习系统模型不断在利用最新的流式样本数据,做好样本数据质量保障,对于在线学习效果提升和系统稳定性保障至关重要。在样本质量保障方面,我们主要从特征监控体系、样本产出监控和样本特征在离线一致性校验来保障在线学习的样本质量。
- 特征监控体系
特征监控包括从样本特征源头获取特征的监控和产出样本后特征质量的监控。特征源头获取特征的监控主要包括从TT日志流、Holo等查询和解析特征的RT、成功率等,样本后特征质量的监控主要包含序列特征的平均长度、连续特征的均值和方差、字符特征的空值率等。
- 样本产出质量
样本产出质量保障包括样本产出监控和样本产出速率动态调整。样本产出监控主要监控样本产出的速率、样本均值、Retraction比例等指标。首页商品商品信息流CTR样本规模较大,日常QPS 十万/s+,峰值数十万/s,日均产出样本百亿规模,为了保障样本的稳定性和时效性,在大促一些资源较为紧张而样本QPS又较大的关键时间点,样本产出能根据资源保障的情况和样本的延迟情况,进行适当的采样。
- 样本特征在离线一致性校验
样本特征的在离线一致性指在线学习的实时样本和离线ODPS产出的批样本在样本和特征上的一致性。星云平台上产出的在线学习实时样本除了写到Swift Topic之外,还会采样比较小的比例落盘到离线ODPS,以跟离线ODPS产出的样本进行双向比对,以及时发现实时样本和离线ODPS样本的不一致问题。
▐ 训练质量
训练质量主要目标是保证模型训练的稳定性和正确性,主要包括异常样本拦截和模型离线效果监控。
- 异常样本拦截
在Swift Topic和Worker读数据的接口之间,我们设计了一个样本缓冲池,又样本缓冲池来读取Swift Topic的数据,累积一定的数据之后进行正负样本比监控,如果正负样本比符合我们制定的标准,则将缓冲池内的样本shuffle后交给Worker读取训练,否则对该样本进行拦截丢弃,主要来对系统故障或大促红包雨等活动所带来的异常比例样本。
- 模型监控
模型监控指标包括AUC、predict_mean和label_mean等,模型在往RTP推送参数之前会校验AUC、predict_mean是否符合我们制定的标准,如果符合再往RTP推送参数,否则则进行拦截。
▐ 预估质量
预估质量监控是在线学习监控链路的最后一个环节,该环节主要包括冒烟发布和异常回滚。
- 冒烟发布
小流量灰度集群效果验证是保证模型预估质量最为稳妥的方式,先将模型推送到小流量集群进行效果观察,效果正常后进行全机房推全。这种方式能有效预防各种模型稳定引发的故障,但是这种方式更新周期长,切换效率低,有损在线学习模型的时效性。为了保证预估模型的质量和时效性,我们采用小样本在离线打分一致性评估的方式进行模型质量保证,其中离线评估通过AUC和predict mean确保离线模型的正确性,小样本在离线模型打分一致性对比为了确保在离线模型的一致性。小样本在离线打分一致性评估基本能达到小流量灰度集群验证的效果,而且校验数据快,不破坏在线学习模型的时效性。
- 异常回滚
异常回滚主要是在发现模型异常时,可以及时快速地回滚到上一个正常的版本。在线打分系统上的模型通常不仅仅存储当前在服务的版本,还会存储上一个模型版本,当当前版本异常时可以款式切换到上一个版本的模型参数。
总结
本文介绍了我们在在线深度学习(ODL)实时流式样本构建、模型实时训练和在线实时更新,以及在线深度学习质量保障工作上的探索与实践。大规模深度学习模型小时级在线学习最早在首页商品信息流CTR模型上全量,日常CTR +2.2%,成交金额 +1.7%;2020年双十一期间(11.01~11.11)CTR +5.2%,成交金额 +2.9%。2020年我们升级到分钟级在线深度学习,在小时级在线深度学习的基础上,CTR +1.1%,成交金额 +0.4%。
在视频信息流推荐场景,在线深度学习带来日常 CTR +3%,PV +0.7%;7天内新视频 PV +22%,CTR +10%。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)
2021-09-09 查分单词-Python
2021-09-09 关于NLP算法工程师的几点思考
2021-09-09 找出只出现一次的数字-Python
2018-09-09 pandas的DataFrame用法
2018-09-09 pandas的Categorical方法
2018-09-09 LightBGM之train
2018-09-09 LightBGM之Dataset