SENet双塔模型:在推荐领域召回粗排的应用及其它
目前,双塔结构在推荐领域里已经是个常规方法了,在召回和粗排环节的模型选型中,被广泛采用。其实,不仅仅是在推荐领域,在其它领域,双塔结构也已经被越来越多得用起来了。比如,在当代搜索引擎的召回环节,除了常见的经典倒排索引来对Query和Document进行文本字面匹配外,经常也会增加一路基于Bert模型的双塔结构,将用户查询Query和搜索文档,各自通过一个塔形结构来打Embedding,以此增加Query和Document的深层语义匹配能力;再比如,在自然语言处理的QA领域,一般也会在第一步召回环节,上一个基于Bert模型的双塔结构,分别将问题Question和可能包含正确答案的Passage,通过双塔结构映射到同一个语义空间,并分别把Question和Passage打出各自的Embedding。
我的感觉,未来,双塔结构会在更多应用领域获得应用,这是个非常有生命力的模型。为啥呢?答案其实很简单:在面临海量候选数据进行粗筛的场景下,它的速度太快了,效果说不上极端好,但是毕竟是个有监督学习过程,一般而言也不差,实战价值很高,这个是根本。若一个应用场景有如下需求:应用面临大量的候选集合,首先需要从这个集合里面筛选出一部分满足条件的子集合,缩小筛查范围。那么,这种应用场景就比较适合用双塔模型。
上面说的是双塔模型的优点,所谓“天下没有免费的晚餐”,它为了速度快,是需要付出代价的,那么,代价是什么呢?就是要在一定程度上牺牲掉模型的部分精准性,而且这个代价是结构内生的,也就是说它这种结构必然会面临这样的问题。至于产生问题的具体原因,在后面介绍双塔模型的时候会讲。
也就是说,目前的现状是:对于绝大多数应用来说,双塔模型的速度是足够快了,模型精度还有待提升。然而,不改变双塔基本结构前提下(为了保速度),如何才能提升模型效果,从上面讲的结构内生性问题来说,看上去貌似又是无解的。那么,真的是这样吗?我其实去年一直也在思考这个问题。好在,去年,我们尝试了一个改进的双塔模型,我称之为“SENet双塔模型”,在业务里证明了它的有效性。本文会介绍下SENet双塔模型的具体做法,尝试分析为何这种改造是有效的。除此外,还会谈及另外两个对模型召回或者粗排来说比较重要的问题:推荐模型召回、粗排及精排几个环节的优化目标一致性问题,以及,召回或粗排模型的负例选择问题。
双塔模型
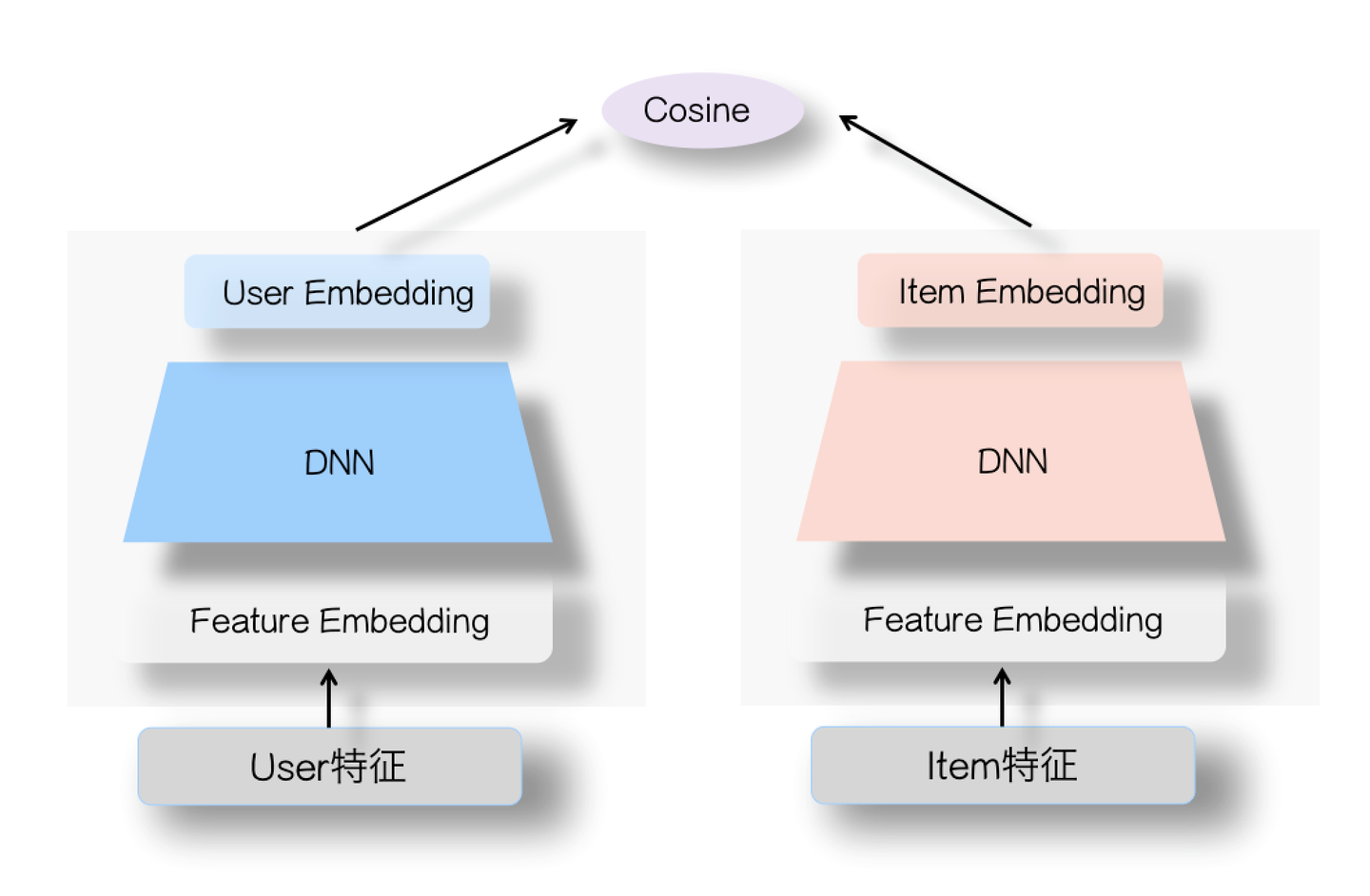
网上介绍双塔模型的文章很多,所以不展开讲了,这里简单说一些要点。
双塔模型结构非常简单,如上图所示,左侧是用户塔,右侧是Item塔,可将特征拆分为两大类:用户相关特征(用户基本信息、群体统计属性以及行为过的Item序列等)与Item相关特征(Item基本信息、属性信息等),原则上,Context上下文特征可以放入用户侧塔。对于这两个塔本身,则是经典的DNN模型,从特征OneHot到特征Embedding,再经过几层MLP隐层,两个塔分别输出用户Embedding和Item Embedding编码。在训练过程中,User Embedding和Item Embedding做内积或者Cosine相似度计算(注:Cosine相当于对User Embedding和Item Embedding内积基础上,进行了两个向量模长归一化,只保留方向一致性不考虑长度),使得用户和正例Item在Embedding空间更接近,和负例Item在Embedding空间距离拉远。损失函数则可用标准交叉熵损失,将问题当作一个分类问题,或者类似DSSM采取BPR或者Hinge Loss,将问题当作一个表示学习问题。
虽说上图两个塔的DNN模块介绍说的是MLP结构,但是理论上这里可以替换成任意你想用的模型结构,比如Transformer或者其它模型,最简单的应该是FM模型,如果这里用FM模型做召回或者粗排,等于把上图的DNN模块替换成了对特征Embedding进行“Sum”求和操作,貌似应该是极简的双塔模型了。所以说,双塔结构不是一种具体的模型结构,而是一种抽象的模型框架。
一般在推荐的模型召回环节应用双塔结构的时候,分为离线训练和在线应用两个环节。上面基本已描述了离线训练过程,至于在线应用,一般是这么用的:
首先,通过训练数据,训练好User侧和Item侧两个塔模型,我们要的是训练好后的这两个塔模型,让它们各自接受用户或者Item的特征输入,能够独立打出准确的User Embedding或者Item Embedding。
之后,对于海量的候选Item集合,可以通过Item侧塔,离线将所有Item转化成Embedding,并存储进ANN检索系统,比如FAISS,以供查询。为什么双塔结构用起来速度快?主要是类似FAISS这种ANN检索系统对海量数据的查询效率高。
再往后,某个用户的User Embedding,一般要求实时更新,以体现用户最新的兴趣。为了达成实时更新的目的,你有几种难度不同的做法,比如你可以通过在线模型来实时更新双塔的参数来达成这一点,这是在线模型的路子;但是很多情况下,并非一定要采取在线模型,毕竟实施成本高,而可以固定用户侧的塔模型参数,采用在输入端,将用户最新行为过的Item做为用户侧塔的输入,然后通过User侧塔打出User Embedding,这种模式。这样也可以实时地体现用户即时兴趣的变化,这是特征实时的角度,做起来相对简单。
最后,有了最新的User Embedding,就可以从FAISS库里拉取相似性得分Top K的Item,做为个性化召回结果。
以上内容介绍了双塔模型的结构以及训练及应用过程。在本文开始,提到过双塔结构有一个内生性的问题,就是它的结构必然会导致精度的损失,为什么这么说呢?我们再审视下双塔的结构,它最大的特点是:首先对用户特征和Item特征分离,两组分离的特征,各自通过DNN网络进行信息集成,集成结果就是两个塔各自顶端的User Embedding和Item Embedding。相比我们平常在精排阶段见到的DNN模型,这种特征分离的设计,会带来两个问题:
第一个问题:我们一般在做推荐模型的时候,会有些特征工程方面的工作,比如设计一些User侧特征和Item侧特征的组合特征,一般而言,这种来自User和Item两侧的组合特征是非常有效的判断信号。但是,如果我们采用双塔结构,这种人工筛选的,来自两侧的特征组合就不能用了,因为它既不能放在User侧,也不能放在Item侧,这是特征工程方面带来的效果损失。当然,我个人认为,这个问题不是最突出的,应该有办法绕过去,或者模型能力强,把组合特征拆成两个分离的特征,各自放在对应的两侧,可以让模型去捕获这种组合特征。
第二个问题:如果是精排阶段的DNN模型,来自User侧和Item侧的特征,在很早的阶段,比如第一层MLP隐层,两者之间就可以做细粒度的特征交互。但是,对于双塔模型,两侧特征什么时候才能发生交互?只有在User Embedding和Item Embedding发生内积的时候,两者才发生交互,而此时的User Embedding和Item Embedding,已经是两侧特征经过多次非线性变换,糅合出的一个表征用户或者Item的整体Embedding了,细粒度的特征此时估计已经面目模糊了,就是说,两侧特征交互的时机太晚了。我们知道,User侧和Item侧特征之间的交互,是非常有效的判断信号。而很多领域的实验已经证明,双塔这种过晚的两侧特征交互,相对在网络结构浅层就进行特征交互,会带来效果的损失。这个问题比较严重。
这就是为何我们说,双塔结构的内生性问题。归纳起来,就是说:为了速度快,必须对用户和Item进行特征分离,而特征分离,又必然导致上述两个原因产生的效果损失。
那么,我们能怎么改造这种结构,让效果损失的少一些呢?
SENet双塔模型
- 将SENet引入推荐系统
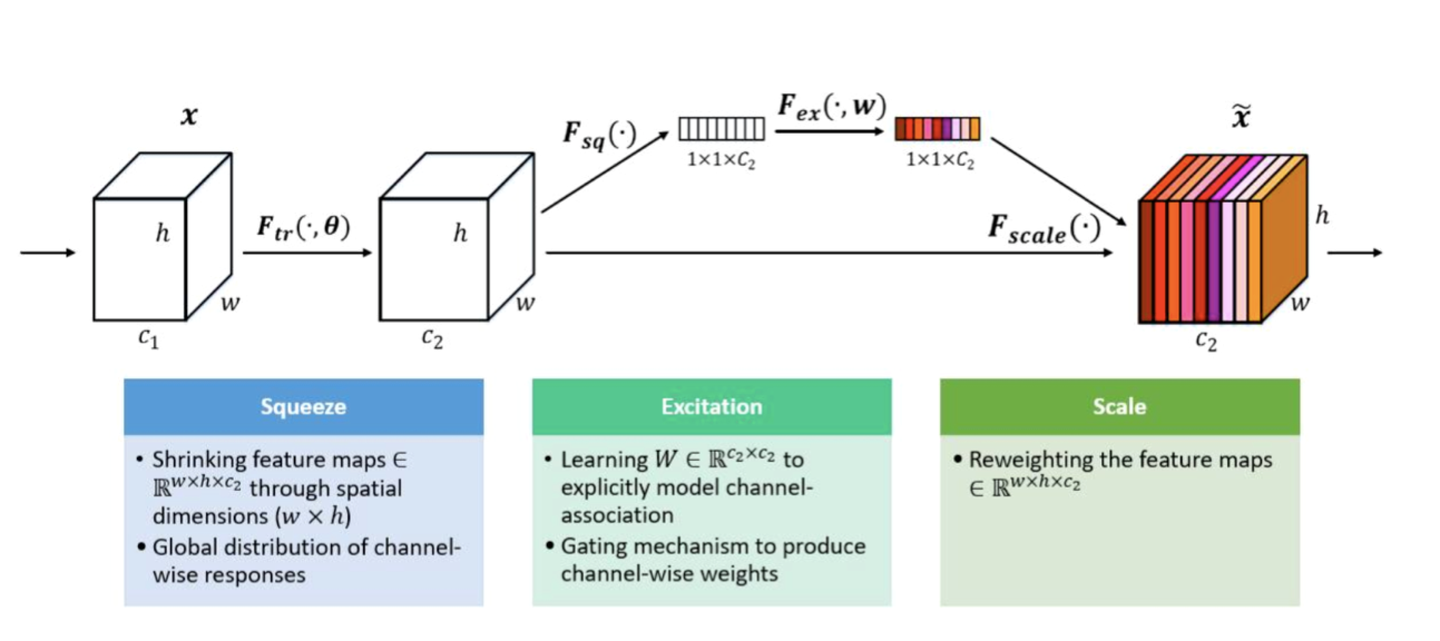
SENet由自动驾驶公司Momenta在2017年提出,在当时,是一种应用于图像处理的新型网络结构。它基于CNN结构,通过对特征通道间的相关性进行建模,对重要特征进行强化来提升模型准确率,本质上就是针对CNN中间层卷积核特征的Attention操作。SENet是2017 ILSVR竞赛的冠军,错误率比2016年的第一名要低25%,效果非常显著。即使到了四年后的今天,SENet仍然是效果最好的图像处理网络结构之一。
我是直到18年才仔细看过SENet的论文,看完就很喜欢这个想法,因为这种模型比较符合我个人的“算法审美”。我一直在内心里比较排斥那些看着特别复杂,堆砌了各种说不清道不明作用构件的模型,比较喜欢简洁有效的算法,可能是在公司里待久了造成的后遗症。就我的经验,如果一个算法构成复杂,效果又没有比基线模型有特别大的提升,除非它能通过消融实验证明每个构件都是必须存在的,否则,这种算法大概率可以直接忽略掉,因为这通常是为了所谓的“创新性”,被强制塞进了看着很高大上但是其实没啥用的东西。“如无必要,勿增实体”,这个原则同样适用于算法领域,而满足这种条件的模型,其实,是很少的。我觉得吧,公司里讨生活的算法工程师,应该尽量且尽早,养成对这种复杂但作用不大的复杂模型发自心底的排斥感,这绝对能极大提升你获取新知识的效率。
说回来,看完SENet的做法,我就觉得应该能够用在推荐系统里,当时我在考虑一个问题,是关于特征Embedding的。我们知道,推荐领域里面的特征有个特点,就是海量稀疏,意思是大量长尾特征是低频的,而这些低频特征,去学一个靠谱的Embedding是基本没希望的,但是你又不能把低频的特征全抛掉,因为有一些又是有效的。既然这样,如果我们把SENet用在特征Embedding上,类似于做了个对特征的Attention,弱化那些不靠谱低频特征Embedding的负面影响,强化靠谱低频特征以及重要中高频特征的作用,从道理上是讲得通的。于是,找同事一起做实验试了下,发现确实还是有效的,在这之前,我们在改造FFM的过程中改了一个双线性FFM,用在特征交互阶段,而这两者又可以互补,所以把双线性FFM和SENet结合到一起,形成了FiBiNet(可以参考论文:FiBiNET: combining feature importance and bilinear feature interaction for click-through rate prediction),从目前我收集到的信息看,FiBiNet应该是当前效果最好的CTR模型之一,当然也存在一些问题,关于这些,我过阵子再单独说一下后续改进版本。另外,在做FiBiNet的同时,我想SENet一样也是可以用在FFM上的,所以另外设计了FAT-DeepFFM(可参考论文:FAT-DeepFFM: Field Attentive Deep Field-aware Factorization Machine),相对DNN版本的FFM,也就是目前的ONN模型,效果也有一定的提升,FFM类模型大规模实用化是成问题的,不过打比赛的同学经常用,所以经常打比赛的同学可以试试看加进去SENet会不会有些提升。
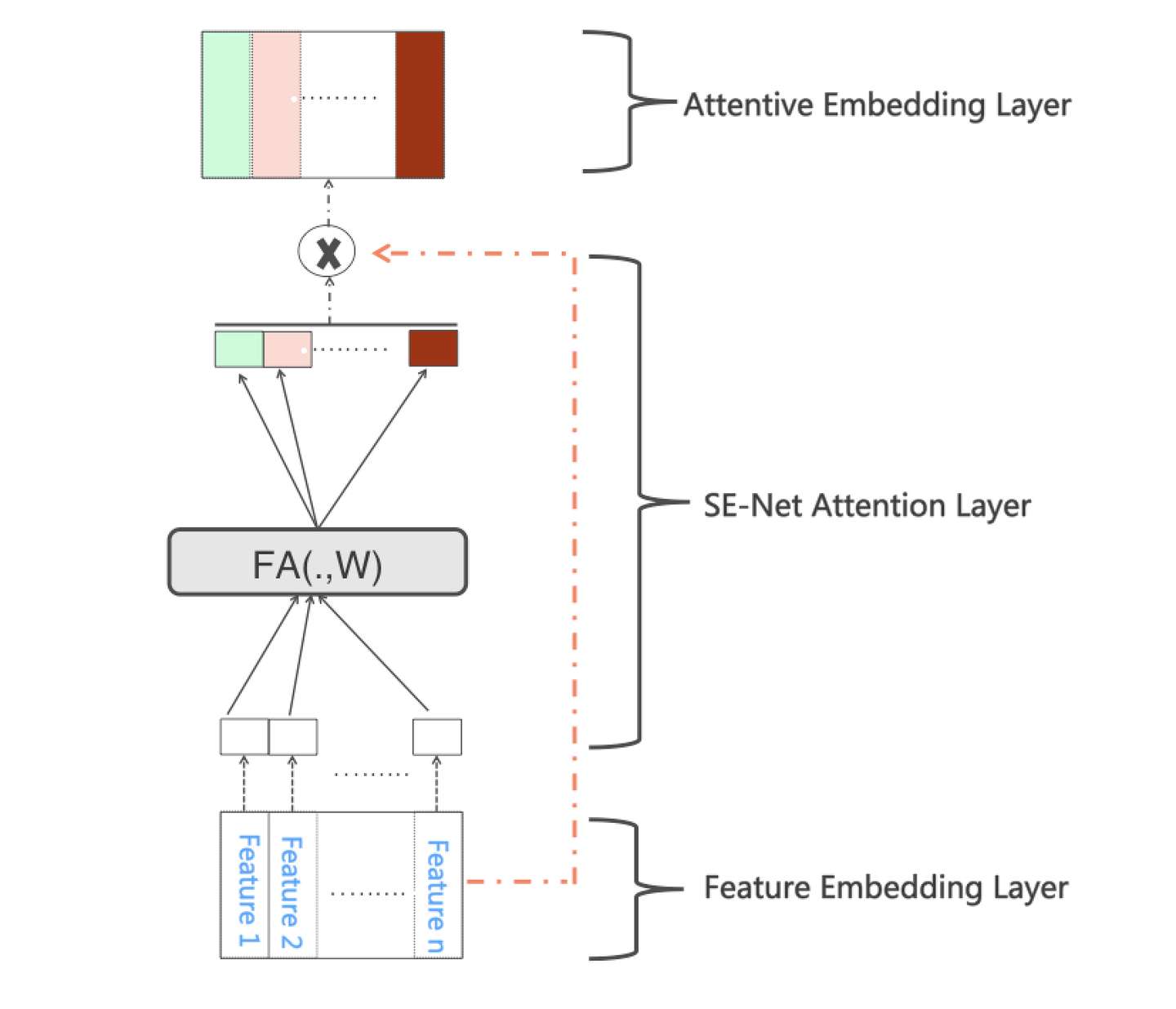
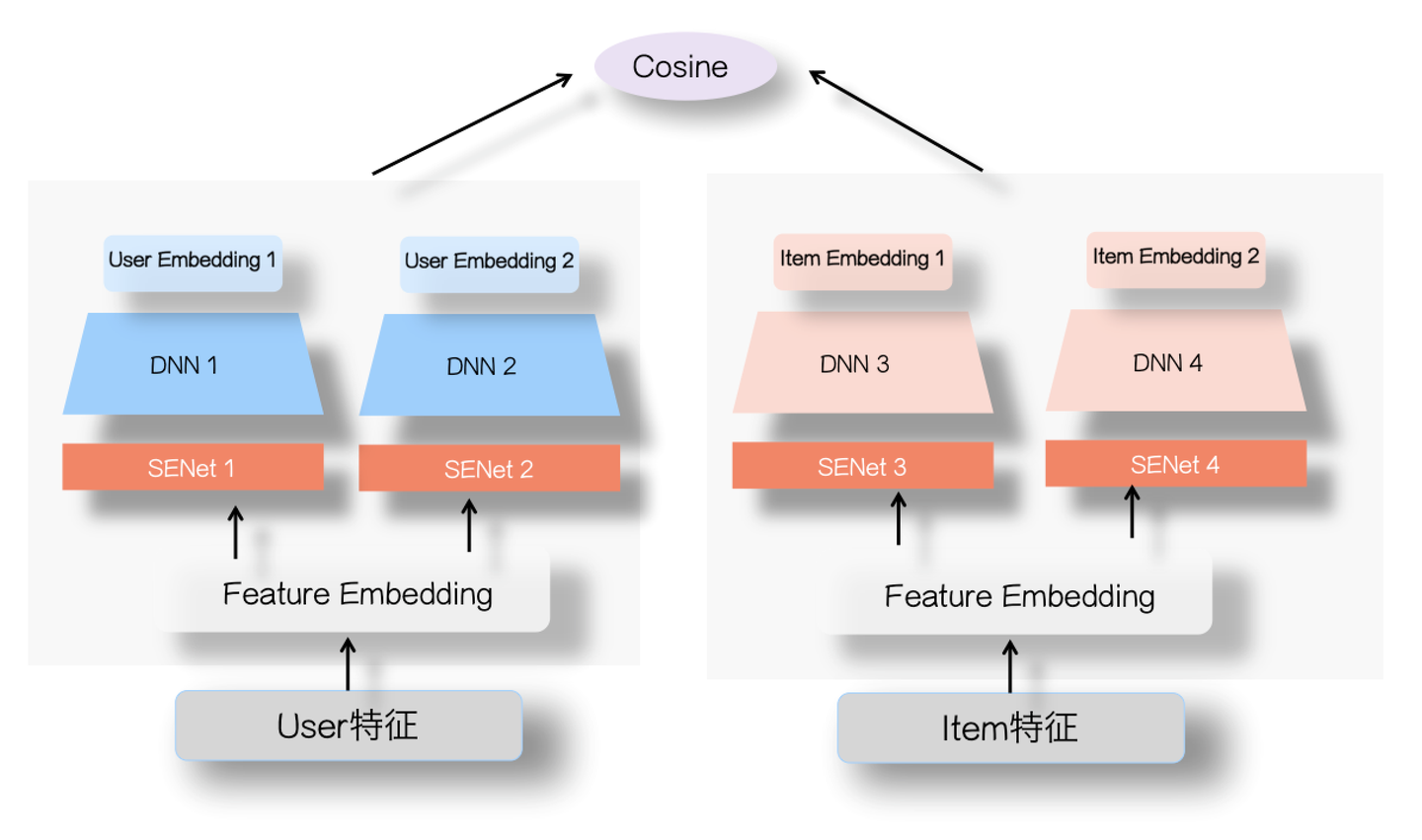
那么,怎么把SENet引入推荐系统呢?其实比较简单,只要稍微改造一下就可以。如上图所示, 标准的DNN模型一般有一个特征Embedding层,我们可以把SENet放在Embedding层之上,目的是通过SENet网络,动态地学习这些特征的重要性 :对于每个特征学会一个特征权重,然后再把学习到的权重乘到对应特征的Embedding里,这样就可以动态学习特征权重,通过小权重抑制噪音或者无效低频特征,通过大权重放大重要特征影响的目的。
具体而言,SENet分为两个步骤:Squeeze 阶段和Excitation阶段。在Squeeze阶段,我们对每个特征的Embedding向量进行数据压缩与信息汇总,如下:
其实很简单,就是说假设某个特征 是k维大小的Embedding,那么我们对Embedding里包含的k维数字求均值,得到能够代表这个特征汇总信息的数值
,也就是说,把第i个特征的Embedding里的信息压缩到一个数值。原始版本的SENet,在这一步是对CNN的二维卷积核进行Max操作的,我们这里等于对某个特征Embedding元素求均值。我们试过,在推荐领域均值效果比Max效果好,这也很好理解,因为图像领域对卷积核元素求Max,等于找到最强的那个特征,而推荐领域的特征Embedding,每一位的数字都是有意义的,所以求均值能更好地保留和融合信息。通过Squeeze阶段,对于每个特征
,都压缩成了单个数值
,假设特征Embedding层有f个特征,就形成了Squeeze向量Z,向量大小为f。
在Excitation阶段,我们引入了中间层比较窄的两层MLP网络,作用在Squeeze阶段的输出向量Z上,如下:
是非线性函数,一般取Relu。其实本质上这是在干啥呢?本质上,这是在做特征的交叉,也就是说,每个特征以一个Bit来表征,通过MLP来进行交互,通过交互,得出这么个结果:对于当前所有输入的特征,通过相互发生关联,来动态地判断哪些特征重要,哪些特征不重要。其中,第一个MLP的作用是做特征交叉,第二个MLP的作用是为了保持输出的大小维度。因为假设Embedding层有f个特征,那么我们需要保证输出f个权重值,而第二个MLP就是起到将大小映射到f个数值大小的作用。这样,经过两层MLP映射,就会产生f个权重数值,第i个数值对应第i个特征Embedding的权重
。我们把每个特征对应的权重
,再乘回到特征对应的Embedding里,就完成了对特征重要性的加权操作。
数值大,说明SENet判断这个特征在当前输入组合里比较重要,
数值小,说明SENet判断这个特征在当前输入组合里没啥用。如果非线性函数用Relu,你会发现大量特征的权重会被Relu搞成0,也就是说,其实很多特征是没啥用的。
这样,我们就可以将SENet引入推荐系统,用来对特征重要性进行动态判断。注意,所谓动态,指的是比如对于某个特征,在某个输入组合里可能是没用的,但是换一个输入组合,很可能是重要特征。它重要不重要,不是静态的,而是要根据当前输入,动态变化的。SENet的代码,已经做为一个构件集成在DeepCTR框架里,对于实做细节感兴趣的,可以看下DeepCTR里的相关代码。
- SENet双塔模型
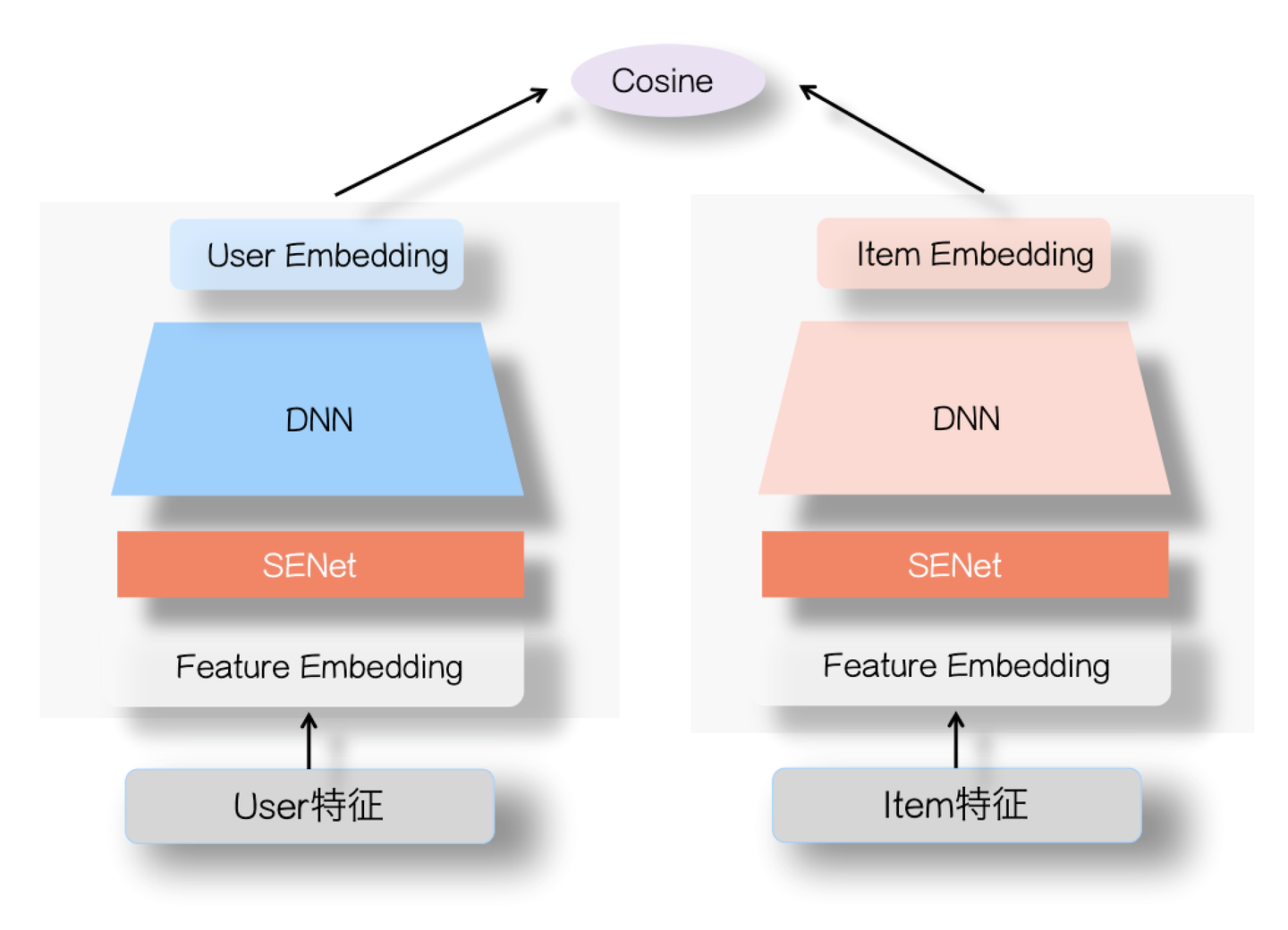
上面讲了那么多,其实都是做个知识铺垫作用,主要想讲的其实是怎么做SENet双塔模型。不过,讲到这里,SENet怎么做,也就呼之欲出了。参考上图,其实很简单,就是在用户侧塔和Item侧塔,在特征Embedding层上,各自加入一个SENet模块就行了,两个SENet各自对User侧和Item侧的特征,进行动态权重调整,强化那些重要特征,弱化甚至清除掉(如果权重为0的话)不重要甚至是噪音的特征。其余部分和标准双塔模型是一样的。20年年底,我们在业务数据测试,加入SENet的双塔模型,与标准双塔模型比,在多个业务指标都有提升,在个别指标有较大的效果提升。而且,如果引入ID类特征,这种优势会更明显。
那么,为什么SENet双塔模型是有效的呢?我是这么看的:在前面,我们谈过双塔模型有个内生性的问题,就是为了速度快,这种两侧分离结构,必然会导致效果损失。而如果归因的话,比较重要的一个原因,是User侧特征和Item侧特征交互太晚,在高层交互,会造成细节信息,也就是具体特征信息的损失,影响两侧特征交叉的效果。站在这个前提下,我们再审视下FM模型和DNN双塔模型各自的特点。
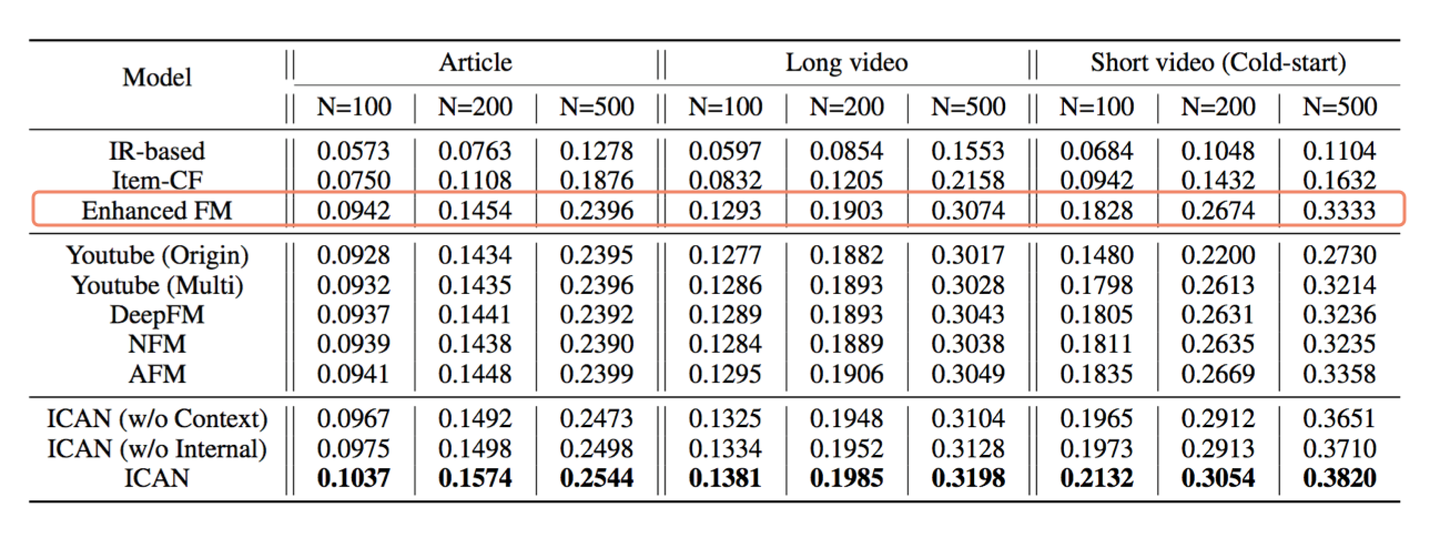
其实,FM召回模型本身是个很强的模型召回基准,但是因为深度学习时代,大家出来讲,或者实际工作的时候,喜欢拿深度模型也就是DNN双塔来说,要不然可能感觉不好意思见人,这个可以理解。说FM效果比较强,这里给个证据,可以参考上图,这是微信的召回方面的工作(可以参考论文:Internal and Contextual Attention Network for Cold-start Multi-channel Matching in Recommendation),其中Enhanced FM其实就是FM模型召回,从实验数据可以看出,除了论文提出的模型外,相对Youtube DNN等很多双塔DNN模型,在多个指标上,FM模型的效果基本是最强的。
我们还是更深入地审视下FM和DNN双塔各自的特性。相对FM模型,双塔DNN的优点是引入了非线性,但是因为这种非线性是在User侧特征之间,或者Item侧特征之间做的,所以可能发挥的作用就没有期待中那么大,因为User侧和Item侧之间的特征交互会更有效一些。而单侧特征的多层非线性操作,可能反而会带来上面说的两侧特征交互太晚,细节信息损失的问题。而FM模型,感觉特性和DNN双塔正好相反,它在User侧和Item侧交互方面比较有优势,因为没有深层,也没有非线性对单侧特征的深度融合,只在两侧特征Embedding层级发生交互作用,所以在特征Embedding层级能够更好地表达User侧和Item侧特征之间的交叉作用,当然,缺点是缺乏非线性。所以,如果仔细分析的话,会发现FM和DNN双塔,是各有擅长之处的。
在这个基础上,我们再来看为何把SENet引入双塔模型会是有效的,我推测可能的原因是:它很可能集成了FM和DNN双塔各自的优点,在User侧和Item侧特征之间的交互表达方面增强了DNN双塔的能力。SENet通过参数学习,动态抑制User或者Item内的部分低频无效特征,很多特征甚至被清零,这样的好处是,它可以凸显那些对高层User Embedding和Item Embedding的特征交叉起重要作用的特征,更有利于表达两侧的特征交互,避免单侧无效特征经过DNN双塔非线性融合时带来的噪声,同时,它又带有非线性的作用。这貌似能同时吸收了FM和DNN各自的优势,取得一个折衷效果。当然,这只是个人推测。
如果再深入对SENet双塔模型思考下的话,其实还可以进一步改进,目前在深度排序或者召回技术方面,一个趋势是把用户的单兴趣Embedding拓展到多兴趣Embedding,这样可以更细致地表达用户兴趣。类似的,我们其实可以基于SENet,把User侧和Item侧的Embedding,打成多兴趣的。就是说,比如在用户侧塔,可以配置不同的SENet模块及对应的DNN结构,来强化不同方面兴趣的Embedding表达。Item侧也可以如此办理,或者Item侧如果信息比较单一,可以仍然只打出一个Item Embedding,只需要维度上能和User侧多兴趣Embedding对齐即可,可称之为“多兴趣SENet双塔模型”。当然,这个只是设想中的方案,未经验证,感兴趣的同学可以试试。
推荐系统几个环节的目标一致性问题
我们知道,一般推荐系统会包含召回、粗排以及精排几个环节。这几个环节优化目标保持一致,其实是个很重要的问题,但是容易在平常工作中忽视。精排环节最靠后,一般没有这个问题,因为可以理解为精排的优化目标,一般就体现为业务指标。容易被忽略的是召回和粗排环节,这两个环节是精排环节的前置环节,为精排输送合适的候选Item集合,如果不能在优化目标上和精排保持一致,会导致物料库里比较适合精排的推荐项,无法通过前置环节,导致推荐效率的损失。
举个极端的例子,虽然不容易出现,但是比较容易说清楚道理。假设精排优化目标是时长目标,但是召回或者粗排的目标是互动或点击目标,这意味着很多高时长的候选推荐项,很可能精排环节根本看不到,因为前置两个环节并不倾向于把高时长的内容往前排。
我们这里说的召回环节,指的是模型召回,因为传统的多路召回,比如热点路等,很多是非个性化,或者个性化因素很弱的,基本不可能针对最终业务指标设立优化目标,也就根本无法讨论目标是否一致的问题。当然,召回除了和最终目标保持一致,还要有多样性等目标,这个可以通过增加其它召回路来实现。
那么,怎么能够尽量使得前置环节的优化目标,和精排目标保持一致呢?一般而言,有两种做法,一种是保持多个环节的多目标优化,各个子目标尽量一致;另外一个是采用知识蒸馏的思路。
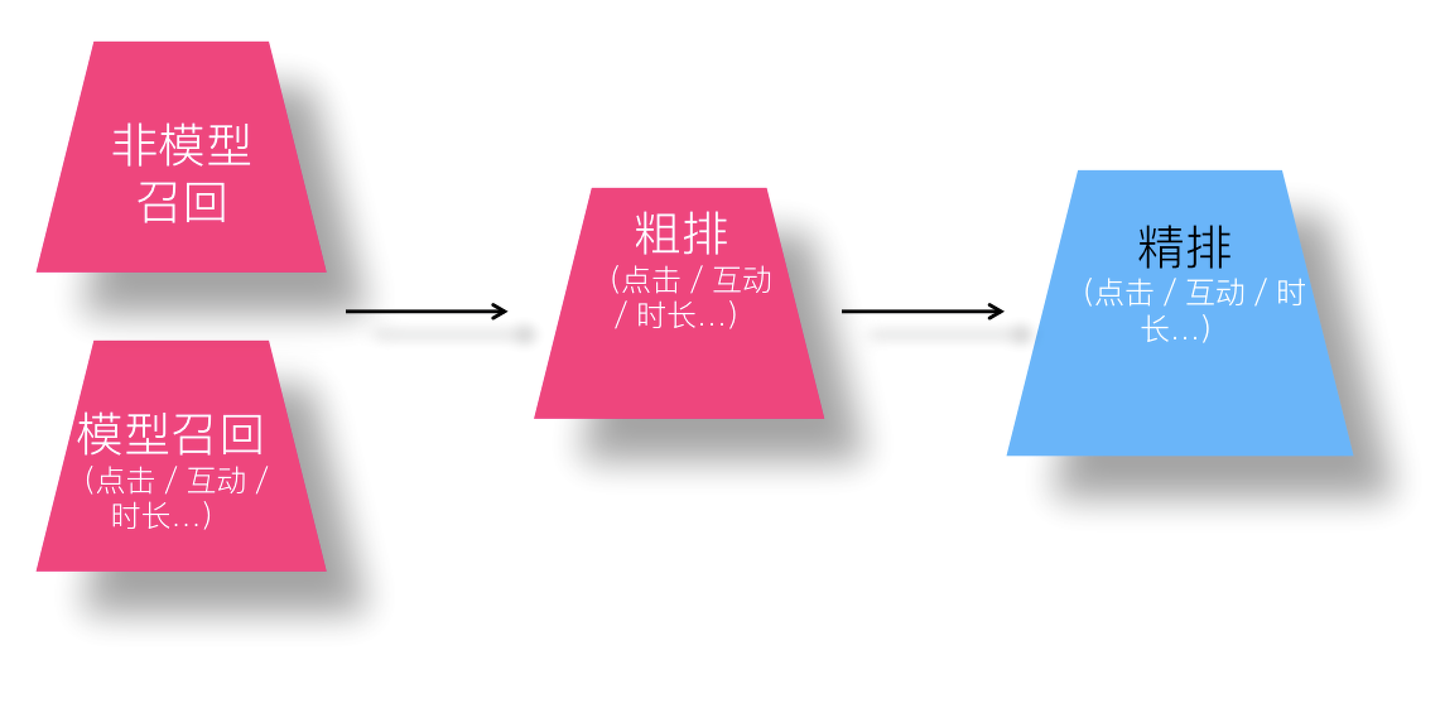
如上图所示,如果我们在三个环节,能保持多目标优化基本一致,原则上,是可以解决上述问题的。
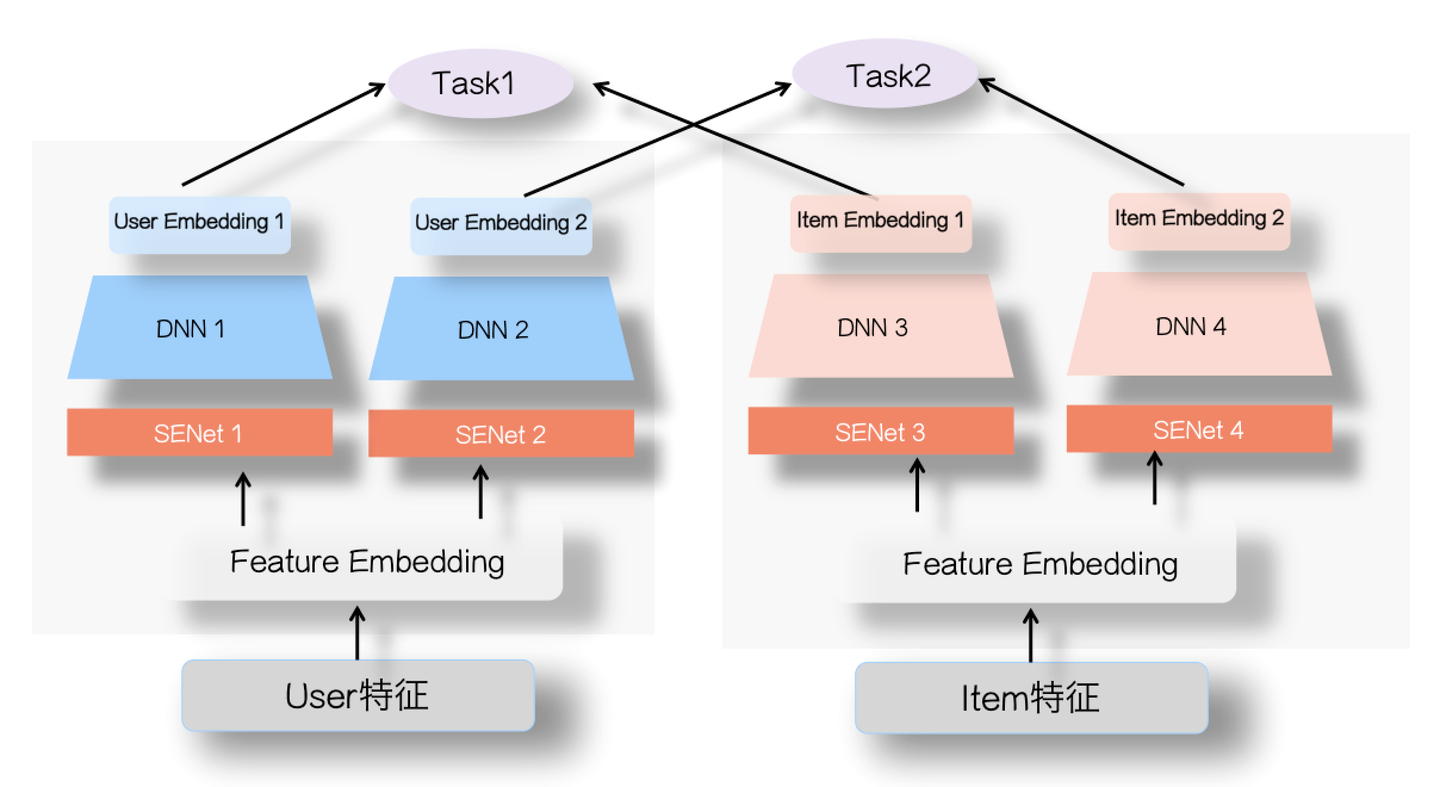
当然,感觉SENet也可以在召回或者粗排的多目标方面发挥作用,可如上图所示来做。就是User侧和Item侧,不同任务共享特征Embedding层输入,对于不同的优化目标,在两侧各自配置对应的SENet网络以及DNN网络,通过SENet筛选强化对某个任务有用的特征,然后不同任务集成自己对应的User Embedding以及Item Embedding。这个也只是设想,还未测试效果,不过既然单任务双塔引入SENet是有效的,推想做多目标也应该是有效的,可称这种结构为“多目标SENet双塔模型”。
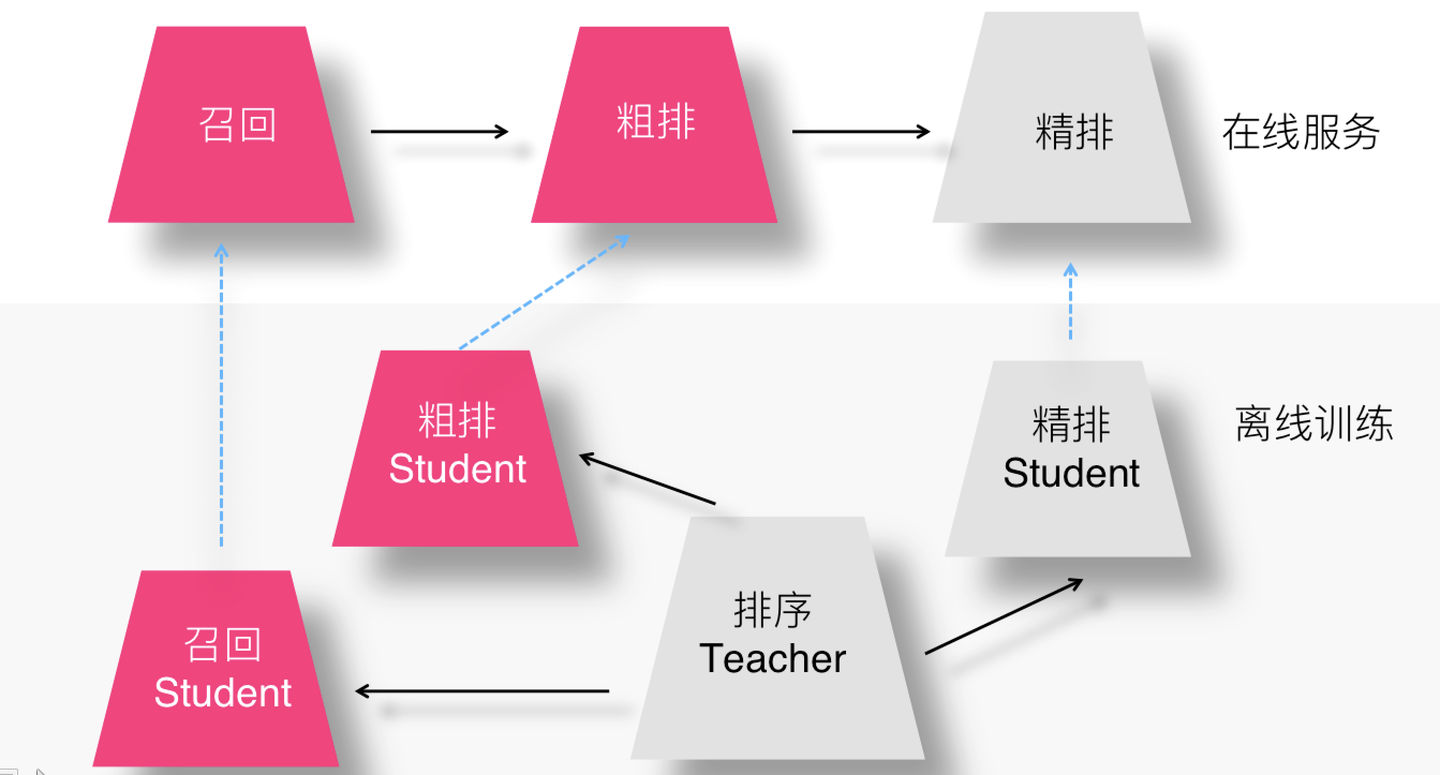
另外一种思路是知识蒸馏,也就是说,召回和粗排环节做为Student,学习精排Teacher的排序偏好,等于说前置环节,直接学习精排的优化目标,打通整个通路。当然,知识蒸馏除了能够引导推荐系统各个环节优化目标保持一致,还可以通过复杂Teacher传播复杂模型和特征给前置环节,提高前置环节模型效果。知识蒸馏具体做法有很多,可以参考:知识蒸馏在推荐系统的应用, 这里不再赘述。
召回及粗排模型的负例选择问题
我们训练精排模型的时候(假设是优化点击目标),一般会用“用户点击”实例做为正例,“曝光未点击”实例做为负例,来训练模型,基本大家都是这么干的。现在,模型召回以及粗排,也需要训练模型,意思是说,也需要定义正例和负例。一般正例,也都是用“用户点击”实例做为正例,但是怎么选择负例,这里面有不少学问。
- Sample Selection Bias问题
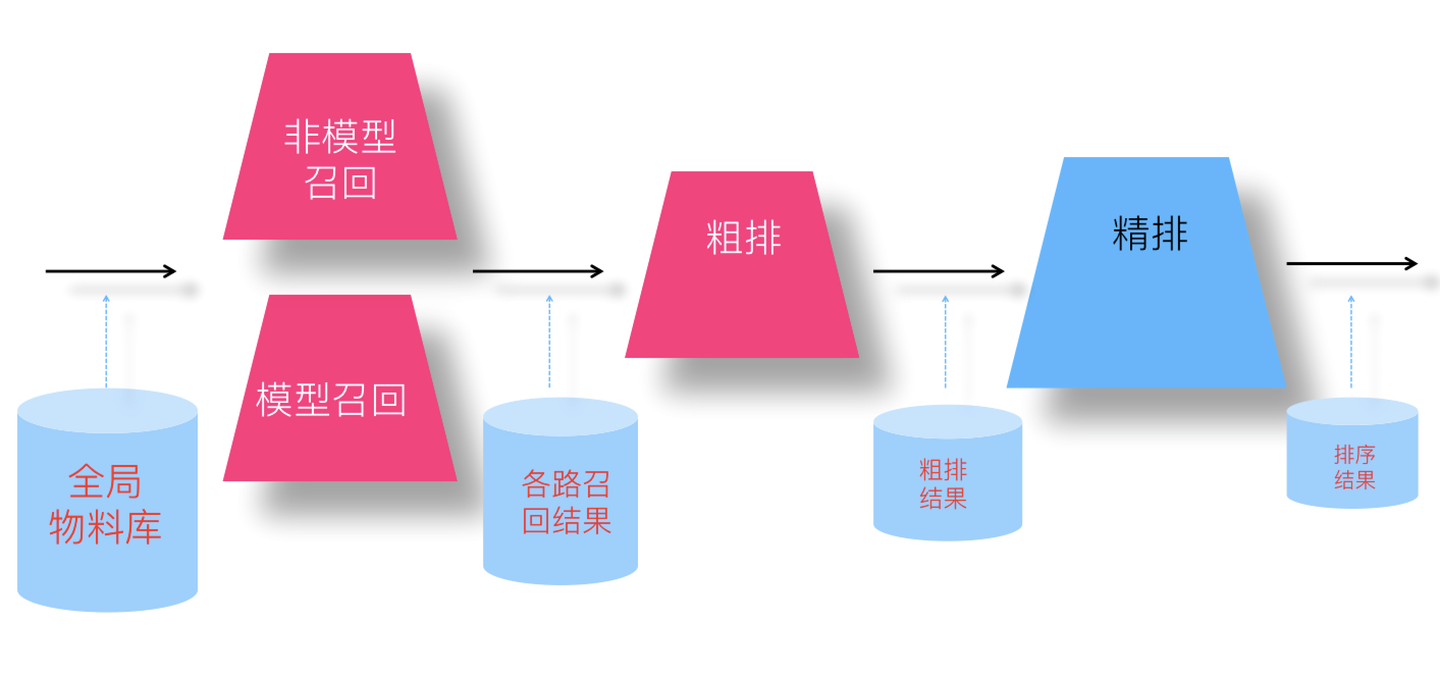
我们先来看下不同阶段模型面对的输入数据情况,对于召回模型来说,它面临的输入数据,是所有物料库里的物品;对于粗排模型来说,它面对的输入数据,是各路召回的结果;对于精排模型来说,它面临的输入是粗排模型的输出结果。如果我们仍然用“曝光未点击”实例做为召回和粗排的负例训练数据,你会发现这个训练集合,只是全局物料库的一小部分,它的分布和全局物料库以及各路召回结果数据,这两个召回和粗排模型面临的实际输入数据,分布差异比较大,所以根据这种负例训练召回和粗排模型,效果如何就带有疑问,我们一般把这个现象称为“Sample Selection Bias”问题。
- 可能的负例选择方法
为了解决“Sample Selection Bias”问题,我们在召回或者粗排模型训练的时候,应该调整下负例的选择策略,使得它尽量能够和模型输入的数据分布保持一致。这里我简单归纳下可能的做法。
选择1:曝光未点击数据
这就是上面说的导致Sample Selection Bias问题的原因。我们的经验是,这个数据还是需要的,只是要和其它类型的负例选择方法,按照一定比例进行混合,来缓解Sample Selection Bias问题。当然,有些结论貌似是不用这个数据,所以用还是不用,可能跟应用场景有关。
选择2:全局随机选择负例
就是说在原始的全局物料库里,随机抽取做为召回或者粗排的负例。这也是一种做法,Youtube DNN双塔模型就是这么做的。从道理上讲,这个肯定是完全符合输入数据的分布一致性的,但是,一般这么选择的负例,因为和正例差异太大,导致模型太好区分正例和负例,所以模型能学到多少知识是成问题的。
选择3:Batch内随机选择负例
就是说只包含正例,训练的时候,在Batch内,选择除了正例之外的其它Item,做为负例。这个本质上是:给定用户,在所有其它用户的正例里进行随机选择,构造负例。它在一定程度上,也可以解决Sample Selection Bias问题。比如Google的双塔召回模型,就是用的这种负例方法。
选择4:曝光数据随机选择负例
就是说,在给所有用户曝光的数据里,随机选择做为负例。这个我们测试过,在某些场景下是有效的。
选择5:基于Popularity随机选择负例
这种方法的做法是:全局随机选择,但是越是流行的Item,越大概率会被选择作为负例。目前不少研究证明了,负例采取Popularity-based方法,对于效果有明显的正面影响。它隐含的假设是:如果一个例子越流行,那么它没有被用户点过看过,说明更大概率,对当前的用户来说,它是一个真实的负例。同时,这种方法还会打压流行Item,增加模型个性化程度。
选择6:基于Hard选择负例
它是选择那些比较难的例子,做为负例。因为难区分的例子,很明显给模型带来的loss和信息含量比价多,所以从道理上讲是很合理的。但是怎样算是难的例子,可能有不同的做法,有些还跟应用有关。比如Airbnb,还有不少工作,都是在想办法筛选Hard负例上。
以上是几种常见的在召回和粗排阶段选择负例的做法。我们在模型召回阶段的经验是:比如在19年年中左右,我们尝试过选择1+选择3的混合方法,就是一定比例的“曝光未点击”和一定比例的类似Batch内随机的方法构造负例,当时在FM召回取得了明显的效果提升。但是在后面做双塔模型的时候,貌似这种方法又未能做出明显效果。全局随机,则无论是FM召回还是后来的双塔,都没做出效果,有时甚至负向明显。但是你又能看到一些报道采用的是全局随机做为负例。所以,我目前的感觉,负例这块是个宝藏,值得深入探索下,包括不同方法的混合,但是到底哪种方法是有效的,貌似很难有统一的定论,带有一定艺术性。
转载: https://zhuanlan.zhihu.com/p/358779957

 浙公网安备 33010602011771号
浙公网安备 33010602011771号