一种数据增强方法-非核心词替换
对于要替换的词是随机选择的,因此一种直观感受是,如果一些重要词被替换了,那么增强后文本的质量会大打折扣。这一部分介绍的方法,则是为了尽量避免这一问题,所实现的词替换技术,姑且称之为「基于非核心词替换的数据增强技术」。
我们最早是在 google 提出 UDA 算法的那篇论文中发现的这一技术 [6],是否在更早的文献中出现过,我们没有再深究了,有了解的同学请留言告知。
整个技术的核心点也比较简单,用词典中不重要的词去替换文本中一定比例的不重要词,从而产生新的文本。
我们知道在信息检索中,一般会用 TF-IDF 值来衡量一个词对于一段文本的重要性,下面简单介绍一下 TF-IDF 的定义:
TF(词频)即一个词在文中出现的次数,统计出来就是词频 TF,显而易见,一个词在文章中出现很多次,那么这个词可能有着很大的作用,但如果这个词又经常出现在其他文档中,如「的」、「我」,那么其重要性就要大打折扣,后者就是用 IDF 来表征。
IDF(逆文档频率),一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。

TF-IDF = TF×IDF,通过此公式可以有效衡量一个词对于一段文本的重要性。当我们知道一个词对于一个文本的重要性之后,再采用与 TF-IDF 负相关的概率去采样文中的词,用来决定是否要替换,这样可以有效避免将文本中的一些关键词进行错误替换或删除。
UDA 论文中所提出的具体实现方式如下:
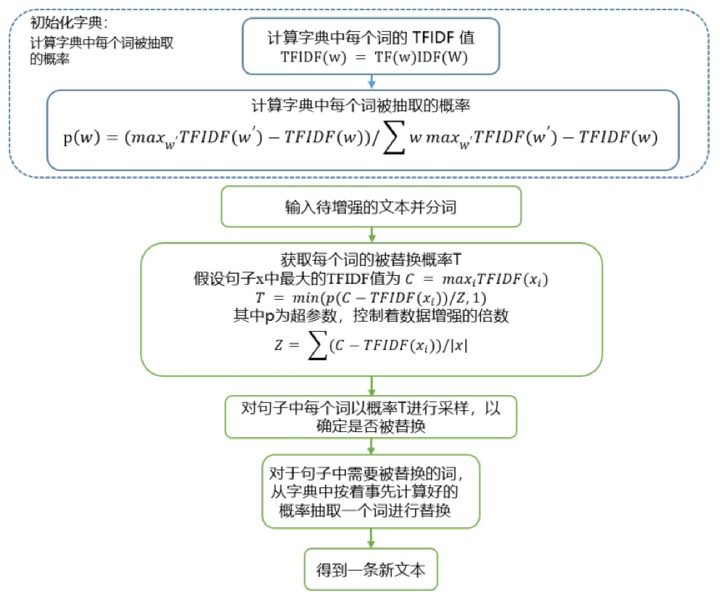
实现一:该方法没有使用字典词汇中被抽取的概率, 而是在待分析文本中选出待替换数据后,通过预训练词向量查找top1相似词汇(sgns.merge.word这个词向量还是质量蛮高的,感谢小萌同学),进行替换得到增强样本。代码如下:
""" Function: data enhance Author: dyx DateTime: 2020.7.16 """ import os import jieba import jieba.analyse from gensim import corpora from gensim import models import pickle import json from gensim.models import KeyedVectors STOPWORDS = open('../resources/stopwords.txt', 'r', encoding='utf8').readlines() STOPWORDS = {each.strip():1 for each in STOPWORDS} CURRENT_FOLDER = os.path.dirname(os.path.abspath(__file__)) WORD2VEC_FILE = r'F:\词向量\sgns.merge.word\sgns.merge.word' ENHANCE_FILE = os.path.join(CURRENT_FOLDER, 'data', 'enhance_train_v1.json') WORD2VEC = models.KeyedVectors.load_word2vec_format(WORD2VEC_FILE, binary=False) ANALYSIS_DATA = os.path.join(CURRENT_FOLDER, 'data', 'analysis_data.txt') PERD_DEV = os.path.join(CURRENT_FOLDER, 'data/error_data/predict_dev') TRUE_DEV = os.path.join(CURRENT_FOLDER, 'data/error_data/dev.json') # wv_from_text.init_sims(replace=True) class DataEnhance(): def __init__(self, data_path): self.data_path = data_path # with open(self.data_path, 'r', encoding='utf8') as fr: # self.content = fr.readlines() with open(PERD_DEV, 'r', encoding='utf8') as fr: self.pred_dev = fr.readlines() with open(TRUE_DEV, 'r', encoding='utf8') as fr: self.true_dev = fr.readlines() def read_data(self): label_count = {'Yes':0, 'No':0, 'Depends':0} word_list = [] analysis_data = [] for each in self.content: yesno_answer = eval(each).get('yesno_answer') answer = eval(each).get('answer') question = eval(each).get('question') tokens = list(jieba.cut(answer)) # 针对answer进行增强 word_list.append(tokens) # tokens = [each for each in tokens if each not in STOPWORDS] # keywords_tfidf = jieba.analyse.extract_tags(answer, topK=30, withWeight=True) # jieba.analyse.set_stop_words(STOPWORDS) # keywords_tfidf_sotpwords = jieba.analyse.extract_tags(answer, topK=30, withWeight=True) # keywords_textrank = jieba.analyse.textrank(answer, topK=30, withWeight=True) # print('question:{}; yesno_answer:{}\nanswer:{}\nsegment:{}\nkeywords_tfidf:{}\n'.format(question, yesno_answer, answer, tokens, keywords_tfidf)) if yesno_answer == "Yes": label_count[yesno_answer] += 1 elif yesno_answer == 'No': label_count[yesno_answer] += 1 elif yesno_answer == "Depends": label_count[yesno_answer] += 1 to_save = 'label:{}\tanswer:{}\n'.format(yesno_answer, answer) analysis_data.append(to_save) print(to_save) with open(ANALYSIS_DATA, 'w', encoding='utf8') as fw: fw.writelines(analysis_data) dictionary = corpora.Dictionary(word_list) new_corpus = [dictionary.doc2bow(w) for w in word_list] tfidf = models.TfidfModel(new_corpus) tfidf.save(os.path.join(CURRENT_FOLDER, 'model', 'tfidf.model')) str_id = dictionary.token2id with open(os.path.join(CURRENT_FOLDER, 'model', 'str_id.pkl'), 'wb') as fw: pickle.dump(str_id, fw) print(label_count) print('tfidf:{}'.format(tfidf)) def unimportant_word_enhance(self): with open(os.path.join(CURRENT_FOLDER, 'model', 'str_id.pkl'), 'rb') as fr: str_id = pickle.load(fr) tfidf_temp = models.TfidfModel.load(os.path.join(CURRENT_FOLDER, 'model', 'tfidf.model')) # 构造文本-tfidf值 tfidf = {} for id in tfidf_temp.dfs: word = list(str_id.keys())[list(str_id.values()).index(id)] tfidf[word] = tfidf_temp.dfs[id] * tfidf_temp.idfs[id] # 最大tfidf值 max_tfidf = max(tfidf.values()) for key, value in tfidf.items(): if (value == max_tfidf): print('{} 词汇最大tfidf值:{}'.format(key, value)) # word was extract prob extract_prob = {} z_sigma = 0 for key in tfidf: z_sigma += max_tfidf-tfidf[key] for key, value in tfidf.items(): extract_prob[key] = (max_tfidf-value)/z_sigma print("每个词被抽取的概率:{}".format(extract_prob)) finnal_data = [] p = 0.3 for sample in self.content: text = eval(sample).get('answer') # replace prob # text = r'是的。凡是能够被2整除的整数都是偶数,例如2、4、-6等。偶数当中也有正偶数、0、负偶数。' tokens = jieba.lcut(text.strip()) sent_tfidf = {} for each in tokens: sent_tfidf[each] = tfidf.get(each) C = max(sent_tfidf.values()) Z = 0.0 replace_prob = {} for each in tokens: Z += (C-sent_tfidf[each])/len(tokens) for each in tokens: temp = p*(C-sent_tfidf[each])/Z if temp < 1.0: replace_prob[each] = temp else: replace_prob[each] = 1.0 replace_prob_sorted = sorted(replace_prob.items(), key=lambda x:x[1], reverse=True) print("当前句子词被替换的概率:{}".format(replace_prob_sorted)) replace_word_01 = replace_prob_sorted[0][0] replace_word_02 = replace_prob_sorted[0][1] # similar_word for i in [replace_word_01, replace_word_02]: if i in WORD2VEC.vocab: target_word = WORD2VEC.similar_by_word(i, 1) target_word = target_word[0][0] print('原始词汇:{}\t被替换词汇:{}'.format(i, target_word)) text = text.replace(i, target_word) new_sample = json.loads(sample) new_sample['answer'] = text finnal_data.append(json.dumps(new_sample, ensure_ascii=False)+'\n') with open(ENHANCE_FILE, 'w', encoding='utf8') as fw: fw.writelines(finnal_data) print('ok') def analysis_data(self): label_count = {'Yes': 0, 'No': 0, 'Depends': 0} error_count = 0 length = len(self.true_dev) for a, p in zip(self.true_dev, self.pred_dev): x = json.loads(a) a_yna = eval(a).get('yesno_answer') p_yna = eval(p).get('yesno_answer') if a_yna != p_yna: error_count += 1 if a_yna == "Yes": label_count[a_yna] += 1 elif a_yna == 'No': label_count[a_yna] += 1 elif a_yna == "Depends": label_count[a_yna] += 1 q = eval(a).get('question') a = eval(a).get('answer') title = [each.get('title') for each in x.get('documents')] paragraphs = [each.get('paragraphs') for each in x.get('documents')] print(title) print(paragraphs) print('question:{}\nanswer:{}\ntrue label:{}\npredict label:{}\n\n'.format( q, a, a_yna, p_yna)) print('总预测样本数:{},误判样本数:{},Acc:{:.4f}'.format(length, error_count, (length-error_count)/length)) print('预测错误标签分布:{}'.format(label_count)) if __name__ == '__main__': data_path = os.path.join(CURRENT_FOLDER, 'data', 'train.json') de = DataEnhance(data_path) # de.read_data() # de.unimportant_word_enhance() de.analysis_data()
实现二:复现原文中的词汇抽取方法。优点是这些词汇依旧是原始语料中的词汇,能够避免一定的语义漂移现象。初步代码如下:
""" Function: data enhance Author: dyx DateTime: 2020.7.16 """ import os import jieba import jieba.analyse from gensim import corpora from gensim import models import pickle import json import numpy as np from gensim.models import KeyedVectors STOPWORDS = open('../resources/stopwords.txt', 'r', encoding='utf8').readlines() STOPWORDS = {each.strip():1 for each in STOPWORDS} CURRENT_FOLDER = os.path.dirname(os.path.abspath(__file__)) # WORD2VEC_FILE = r'F:\词向量\sgns.merge.word\sgns.merge.word' ENHANCE_FILE = os.path.join(CURRENT_FOLDER, 'data', 'enhance_train_v1.json') # WORD2VEC = models.KeyedVectors.load_word2vec_format(WORD2VEC_FILE, binary=False) ANALYSIS_DATA = os.path.join(CURRENT_FOLDER, 'data', 'analysis_data.txt') PERD_DEV = os.path.join(CURRENT_FOLDER, 'data/error_data/predict_dev') TRUE_DEV = os.path.join(CURRENT_FOLDER, 'data/error_data/dev.json') # wv_from_text.init_sims(replace=True) class DataEnhance(): def __init__(self, data_path): self.data_path = data_path with open(self.data_path, 'r', encoding='utf8') as fr: self.content = fr.readlines() with open(PERD_DEV, 'r', encoding='utf8') as fr: self.pred_dev = fr.readlines() with open(TRUE_DEV, 'r', encoding='utf8') as fr: self.true_dev = fr.readlines() def read_data(self): label_count = {'Yes':0, 'No':0, 'Depends':0} word_list = [] analysis_data = [] for each in self.content: yesno_answer = eval(each).get('yesno_answer') answer = eval(each).get('answer') question = eval(each).get('question') tokens = list(jieba.cut(answer)) # 针对answer进行增强 word_list.append(tokens) # tokens = [each for each in tokens if each not in STOPWORDS] # keywords_tfidf = jieba.analyse.extract_tags(answer, topK=30, withWeight=True) # jieba.analyse.set_stop_words(STOPWORDS) # keywords_tfidf_sotpwords = jieba.analyse.extract_tags(answer, topK=30, withWeight=True) # keywords_textrank = jieba.analyse.textrank(answer, topK=30, withWeight=True) # print('question:{}; yesno_answer:{}\nanswer:{}\nsegment:{}\nkeywords_tfidf:{}\n'.format(question, yesno_answer, answer, tokens, keywords_tfidf)) if yesno_answer == "Yes": label_count[yesno_answer] += 1 elif yesno_answer == 'No': label_count[yesno_answer] += 1 elif yesno_answer == "Depends": label_count[yesno_answer] += 1 to_save = 'label:{}\tanswer:{}\n'.format(yesno_answer, answer) analysis_data.append(to_save) print(to_save) with open(ANALYSIS_DATA, 'w', encoding='utf8') as fw: fw.writelines(analysis_data) dictionary = corpora.Dictionary(word_list) new_corpus = [dictionary.doc2bow(w) for w in word_list] tfidf = models.TfidfModel(new_corpus) tfidf.save(os.path.join(CURRENT_FOLDER, 'model', 'tfidf.model')) str_id = dictionary.token2id with open(os.path.join(CURRENT_FOLDER, 'model', 'str_id.pkl'), 'wb') as fw: pickle.dump(str_id, fw) print(label_count) print('tfidf:{}'.format(tfidf)) def unimportant_word_enhance(self): with open(os.path.join(CURRENT_FOLDER, 'model', 'str_id.pkl'), 'rb') as fr: str_id = pickle.load(fr) tfidf_temp = models.TfidfModel.load(os.path.join(CURRENT_FOLDER, 'model', 'tfidf.model')) # 构造文本-tfidf值 tfidf = {} for id in tfidf_temp.dfs: word = list(str_id.keys())[list(str_id.values()).index(id)] tfidf[word] = tfidf_temp.dfs[id] * tfidf_temp.idfs[id] # 最大tfidf值 max_tfidf = max(tfidf.values()) for key, value in tfidf.items(): if (value == max_tfidf): print('{} 词汇最大tfidf值:{}'.format(key, value)) # word was extract prob extract_prob = {} z_sigma = 0 for key in tfidf: z_sigma += max_tfidf-tfidf[key] original_word = [] word_prob = [] for key, value in tfidf.items(): prob = (max_tfidf-value)/z_sigma extract_prob[key] = prob original_word.append(key) word_prob.append(prob) print("每个词被抽取的概率:{}".format(extract_prob)) finnal_data = [] p = 0.3 for sample in self.content: text = eval(sample).get('answer') extract_word = original_word[np.random.choice(len(original_word), 1, p=word_prob)[0]] # replace prob # text = r'是的。凡是能够被2整除的整数都是偶数,例如2、4、-6等。偶数当中也有正偶数、0、负偶数。' tokens = jieba.lcut(text.strip()) sent_tfidf = {} for each in tokens: sent_tfidf[each] = tfidf.get(each) C = max(sent_tfidf.values()) Z = 0.0 replace_prob = {} for each in tokens: Z += (C-sent_tfidf[each])/len(tokens) for each in tokens: temp = p*(C-sent_tfidf[each])/Z if temp < 1.0: replace_prob[each] = temp else: replace_prob[each] = 1.0 replace_prob_sorted = sorted(replace_prob.items(), key=lambda x:x[1], reverse=True) print("当前句子词被替换的概率:{}".format(replace_prob_sorted)) replace_word_01 = replace_prob_sorted[0][0] text = text.replace(replace_word_01, extract_word) print('被替换词:{}; 目标词汇:{}'.format(replace_word_01, extract_word)) new_sample = json.loads(sample) new_sample['answer'] = text finnal_data.append(json.dumps(new_sample, ensure_ascii=False)+'\n') with open(ENHANCE_FILE, 'w', encoding='utf8') as fw: fw.writelines(finnal_data) print('ok') def analysis_data(self): label_count = {'Yes': 0, 'No': 0, 'Depends': 0} error_count = 0 length = len(self.true_dev) for a, p in zip(self.true_dev, self.pred_dev): x = json.loads(a) a_yna = eval(a).get('yesno_answer') p_yna = eval(p).get('yesno_answer') if a_yna != p_yna: error_count += 1 if a_yna == "Yes": label_count[a_yna] += 1 elif a_yna == 'No': label_count[a_yna] += 1 elif a_yna == "Depends": label_count[a_yna] += 1 q = eval(a).get('question') a = eval(a).get('answer') title = [each.get('title') for each in x.get('documents')] paragraphs = [each.get('paragraphs') for each in x.get('documents')] print(title) print(paragraphs) print('question:{}\nanswer:{}\ntrue label:{}\npredict label:{}\n\n'.format( q, a, a_yna, p_yna)) print('总预测样本数:{},误判样本数:{},Acc:{:.4f}'.format(length, error_count, (length-error_count)/length)) print('预测错误标签分布:{}'.format(label_count)) if __name__ == '__main__': data_path = os.path.join(CURRENT_FOLDER, 'data', 'train.json') de = DataEnhance(data_path) de.read_data() de.unimportant_word_enhance() # de.analysis_data()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号