
[PyJs系列介绍]三、编译与上线
如前,本地调试过程的require,都是同步ajax请求的。这种逻辑不可能部署到线上吧,所以针对上线,我们做了特殊的处理。
编译
在根目录下运行
python pyjs.py
程序会在build目录下生成所有module编译后的文件,如increment会编译成
var add = require('math').add;
exports.increment = function(val) {
return add(val, 1);
};
} );
这与我们本地调试时从调试服务器上获取到的文件是一致的,也保证了本地调试与线上运行时的统一。
但仅仅这样还是不行的,我们无法得到完整的依赖链,还是会重复RequireJS和SeaJs的老路。
于是就有了下面。
boot.js
boot.js是在编译时生成的文件,为pyjs.js和依赖关系的合集。
依赖关系的生成,是在编译时对文件进行全面扫描,提取出单个文件的require模块,按照一定的方式合并起来。
依赖关系编译后代码如下:
addDependence('main' , 'increment');
addDependence('increment' , 'math');
addDependence('math' , '');
如此,如果我们引入了core模块,将能知道其依赖于main& math。虽然继续寻找main和math的依赖关系,直至找出这个core的依赖链。
编译后的require,不能使用require('module').a的方式执行,必须使用
require('module' , function(module){module.xx})
这样的回调方式运行,原因自然明了:)。回调的一个参数是require的module的公开方法绑定的对象。
获取到依赖链后将请求文件,这里有两种方式。
Combo
combo就是类似yui configurator服务。我们用一个请求就可以将所有的依赖文件按序读回来。文件中执行require的时候其依赖的模块已经在此之前载入到浏览器中了,所以可以直接读取模块内容。
combo请求的url类似如下
使用combo服务需要在manifest.json中配置combo信息。
异步并行加载
对于没有combo服务的用户,我们使用异步并行加载的策略。
首先对所有的js文件进行预加载,参考这篇文章
这样所有文件的请求都是异步且并行的。
随后按序串行执行每一个Js文件, 因为本地已经有缓存,按序执行并不会有太大的性能影响。
请求的瀑布图如下:
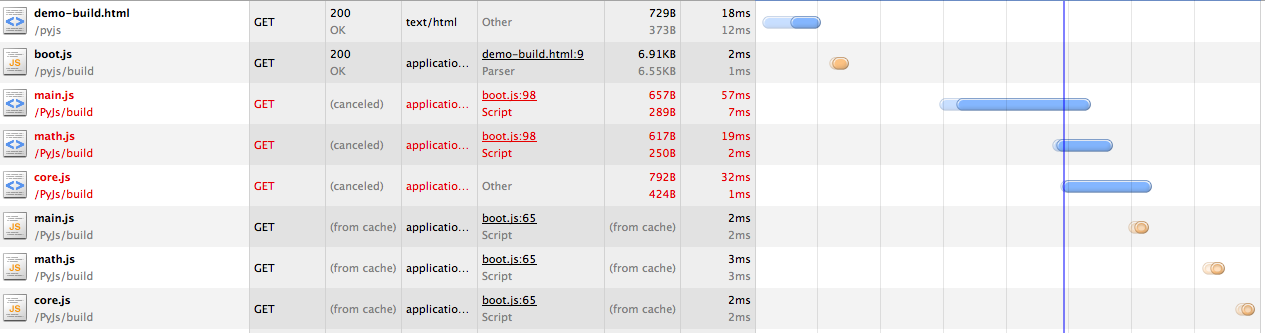
可以看到,前面的请求已经把文件缓存到本地了,所以后面重新请求的时候都是from cache。
该机制目前还不完善,同时我们也推荐使用combo服务。
以上两种模式,完全解决了commonjs模式对浏览器加载的串行问题。而且已经在百度连接JavaScript 2.0中使用(combo模式)。简单可依赖 :)
最后附上PyJs和SeaJs的对比
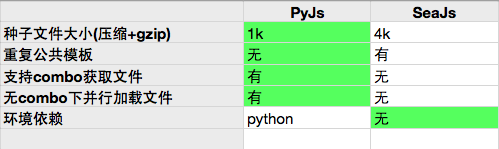
如上,PyJs只有在本地依赖上有缺憾(对部分开发者来说XD,我个人还好)。但是本地服务器也能带来很多好处的,这在我们接下来会继续介绍。

