

[PyJs系列介绍]二、缘起和核心概念
续上,这一篇来深入到PyJs内部,讲一讲它是怎么运作的。
首先说一下PyJs的诞生记。
关于coding,我一只有坚持两个原则:
1. 不写重复的,无意义的代码--DRY
2. 编码不能有过多的约束。
在开发百度连接JavaScript SDK的过程中,会面临一个问题:代码要保持一定的规范性以便更多的服务能方便的接入到整个SDK里面来。一开始的做法会加入很多命名空间来规划服务,同时要求代码必须遵循一定的风格。这样无疑违背了自己第二个原则,而且各服务的开放接口千奇百怪,控制起来也很头疼。
这时就想到了commonjs。使用commonjs的话,其他服务的内部代码其实可以风格迥异,只要对于需要开放的对象或方法,加上一个exports.xxx=xxx即可。这样约束不多,也很好的保证了API的简洁性,同时也有安全沙箱,多个服务之间的代码不会项目冲突。
于是搜遍天下commonjs的实现,比较著名的RequireJs和国内的SeaJs。这两种以各自的方式实现了浏览器端的commonJS,但是最致命的问题是没有解决依赖链导致文件串行加载的问题。同时百度开放平台有提供js combo服务,但是在这两者的架构下显然无法实现。另外一个问题,这两者又违反了我第一个原则。两者均需要给自己的模块手动写上一些公共的模板。如SeaJs会有如下的模板需要每个文件中都加入:
my code goes here...
});
对于我是很难接受的。
正好最近也在学python,参考yui3的源码和编译过程,于是突发奇想做了PyJs。
PyJs的使用依赖于下面几个概念:
Python 本地服务器
这也是选择python来做这个事情的一个重要原因。
开发的时候,需要本地启动一个服务器,如下:
python pyjs.py runserver
我们在做commonjs的require module的时候,会通过本地服务器去寻找需要的module。我们编写模块只需要遵循commonjs最简单的规范即可,如下:
var add = require('math').add;
return add(val, 1);
};
服务器找到这个文件之后,会把它与lib/modules.js里面的模板进行一个拼合,lib/modules/js文件如下:
##file##
} );
其中的##package##会替换成require的模块名,也是文件名,##file##会替换为模块内容,生成之后的内容如下:
var add = require('math').add;
exports.increment = function(val) {
return add(val, 1);
};
} );
这样不需要我们人工去定义模块和加公共模板,即实现了一个完整的模块定义。
本地服务器同时也是一个静态文件服务器,所以我们可以直接写测试用的html,css等,直接调用。
pyjs.js
在lib目录下有pyjs.js。这是全局方法声明的核心文件,定义了require,exports等方法和对象。本地调试的时候都请加入这个文件。
由于js本身不需要处理很复杂的预解析过程,这个文件很小,源码的代码行数就才200来行,体积与requirejs和seajs的种子文件相比优势是很大的。
PyJsDir
本地服务器中有说道module的寻找,但python服务器本身就可以作为一个静态资源服务器,服务器是怎么区分是一个静态资源还是一个module呢,这里就需要PyJsDir的定义了。
默认的PyJsDir是在根目录的src文件夹下, 可以在manifest.json中配置(稍后介绍)。服务器寻找一个请求的基本流程如下:
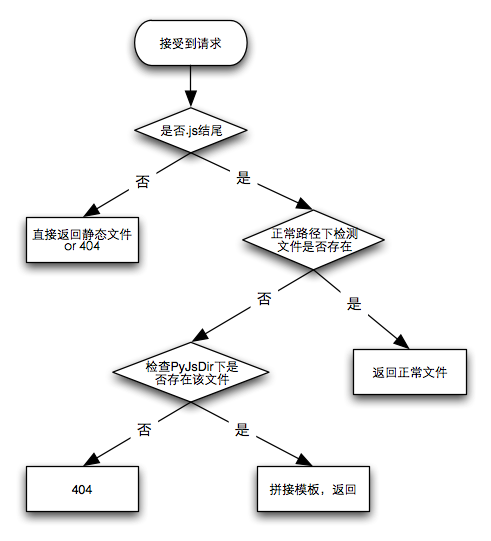
所有的模块都要部署在pyjsdir下。
manifest.json
这是整个pyjs的核心配置文件,与服务有关的配置都写在这个文件下。使用标准JSON格式。
Require与dependence
对所有的模块,使用require函数统一进入。
so ,我们在本地调试的时候,只需要启动一个服务器,写一个静态页面把lib/pyjs.js引入,在pyjsdir下面使用commonjs语法编写module,在页面中require相应的module即可。是不是毫无压力 XD
PS: PyJS有适用环境。比较适合没有模板,只有静态页面,特别是页面中js逻辑比较复杂的项目适用。模板类的就最好别使用了,也不是目标用户。。。专注,专注。。。

