Temporal Action Detection with Structured Segment Networks (ssn)【转】

Action Recognition: 行为识别,视频分类,数据集为剪辑过的动作视频
Temporal Action Detection: 从未剪辑的视频,定位动作发生的区间,起始帧和终止帧并预测类别
难点
1: 边界不明确(助跑跳远,上篮,高尔夫挥杆)
2: 如何利用时序信息
3: 时序跨度大(Activitynet:1s — 200s)

上图为模型框架,用temporal actionness grouping算法提取proposal后进行上下文信息的金字塔池化,后接两个级联分类器分别是完整性判断和类别分类
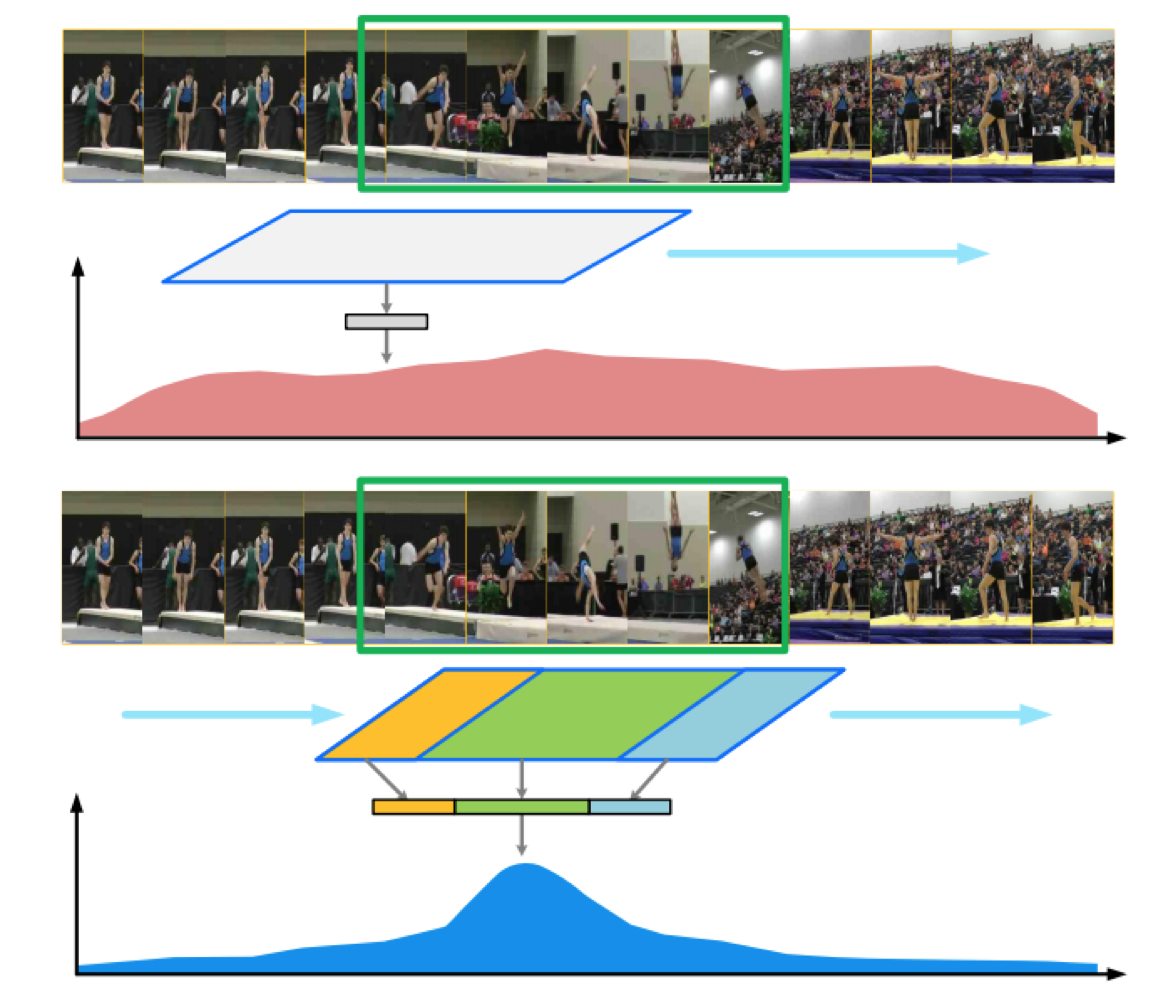
图中上半部分所示的是现有的基于视频短片段(discriminative snippets)的行为识别方法的检测结果,可以看到只要图中蓝色的框遇到具有明显判别信息的snippets时(绿色框),分类器就会具有很强的响应,这样就导致很难精确的去定位动作何时发生何时停止。为解决这个问题,文中指出需要对视频的时序结构进行分析,也就是说我们需要识别视频中动作的开始、持续以及结束三个阶段来确定视频中的动作是否完整。 为了简单的描述整个过程,这里将深度特征提取部分看作一个独立的小模块。这样整个的模型可以描述为以下几个过程:
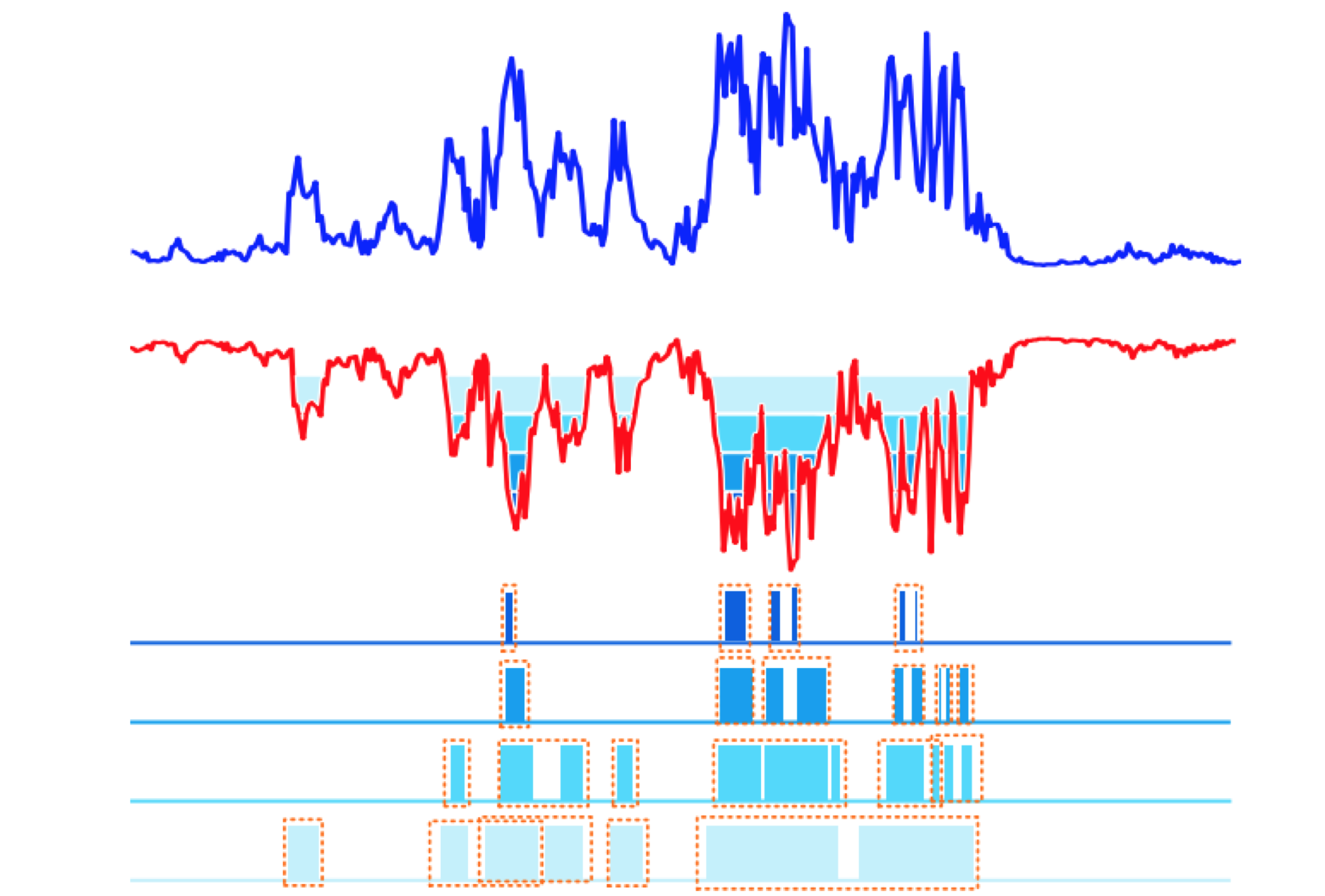
分水岭聚合方法
使用temporal actionness grouping (TAG) 方法获取多个高质量的 proposals (图中绿色方框)。文中通过使用一个分类器 actionness classifier 来计算每个独立的 snippets 的 binary actionness probability ,简单的说就是来预测某个 snippets 存在运动的可能性,这样就在时序上得到以下图中所示结果:从上图中可以看出,如果我们将它反过来我们就可以使用类似于分水岭算法的方法来生成proposals。

在得到原始的 proposal后,我们将其分别向两端扩展原始 proposals 长度一半的长度,得到新的2倍于原始长度的新 proposal 。两端被扩展的部分分别被定义为 starting 和 ending 两个 stage ,而原始的 proposals 则被定义为中间 course 部分。这样就得到上图中黄色方框所对应的情况。 在训练过程中为了有效的减小计算量,文中采用了类似于上文中的 segment 策略,将扩展后的 proposal 分为 9 个 segments (starting, course, ending 各对应3个), 然后在每个 segment 中随机选择一个小片段 snippet 参与运算。这样不仅可以有效的提取整个proposal 的信息,同时也使得特征的长度不随 proposal 的长度而改变,方便后续 end to end 的网络训练 。
在得到每个 stage 上的多个小片段 snippets 后,文中利用 two-stream 网络提取每个 snippts 的特征,然后采用的 structured temporal pyramid pooling 操作来对特征进行整合,实现从 snippt-level 的特征到 stage-level 的特征。 在实现过程中,对于starting 以及 ending 两个 stage 分别采用 one-level pyramids pooling, 既对两个stage的特征进行一次平均池化(图中黄色和蓝色部分)。对于course stage 文中采用 two-level pyramid pooling , 在第一层原始的 course stage 首先被分为两个 part , 分别计算两个 part 的平均池化;在第二层对上一层得到的结果再进行一次平均池化(图中绿色部分),这样分别得到了 starting, course, ending 所对应的 stage-level 特征。
在得到stage-level 特征后,文章中分别采用两种分类器 activity classifer 以及 completeness classifiers 分别实现对动作和动作的完整度进行分类。activity classifer 包含一个分类器,它仅输入 course 的特征,将 proposals 分为 K+1 个类别(包含背景类)。 completeness classifiers 则包含 K 个二分类器,每个分类器的输入是其对应的第 k 类 starting, course, ending stage 金字塔池化特征,输出该动作是否完整的概率。文中从概率的角度将两种分类器通过联合概率的形式进行整合,从而构造统一的损失函数,实现端对端的学习。 在得到 stage-level 的特征后我们不仅可以实现分类,还可以实现对原始的 proposal 进行重新定位,这个过程类似于 RCNN 对bounding box 的回归操作。文章中对训练样本中正类 proposal , 以其最接近的 groundtruth 为目标对该 proposal 的中心和长度进行回归。文中采用多任务学习策略将分类和回归两个部分整合为一个统一的损失函数。 定义统一分类损失(unified classification loss):
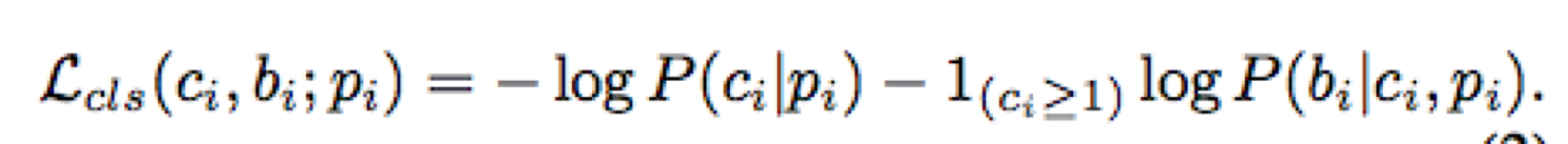
两种分类器部署在高级特征之上。对于一个proposal:pi
A分类器给出一个经过softmax后的向量,条件分布表示为 P(ci|pi),其中 ci 表示类别。
对于每个类别 k,对应的 Ck 完整性分类器给出一个概率值,分布为:P(bi|ci,pi),bi 指示动作是否完成。
训练时,关注三种proposal样本:
(1)positive proposals(ci>0,bi=1):与最接近的groundtruth的IOU至少为0.7
(2)background proposals(ci=0):不与任何groundtruth重叠
(3)incomplete proposals(ci>0,bi=0):其80%包含在groundtruth中,但IOU小于0.3,仅仅包含gt的一小部分。
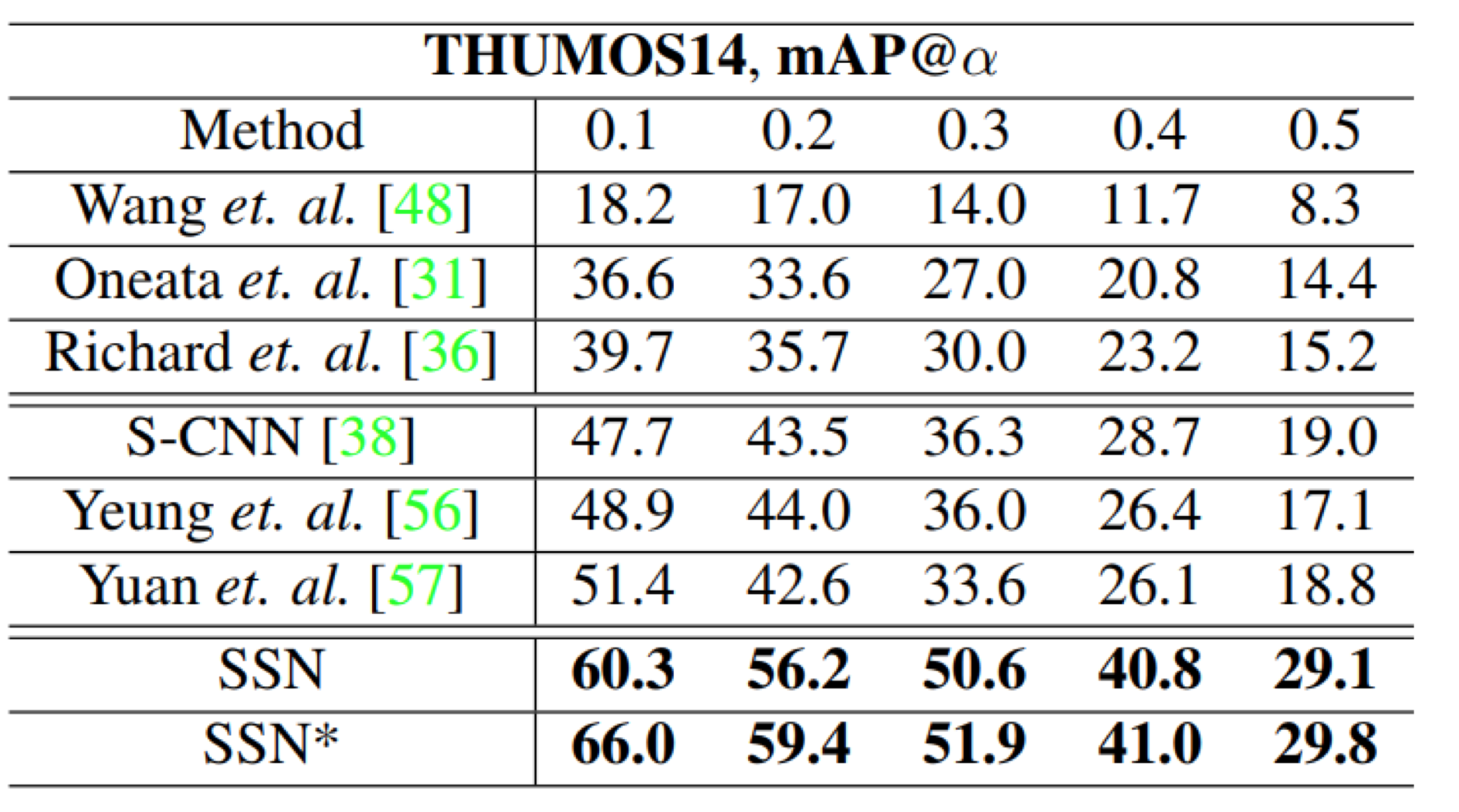
Thumos14和Activitynet1.3的结果:

code:github

 浙公网安备 33010602011771号
浙公网安备 33010602011771号