Inflated 3D ConvNet 【I3D】
Two-Stream Inflated 3D ConvNet (I3D)
HMDB-51: 80.9% and UCF-101: 98.0% 在Inception-v1 Kinetics上预训练

ConvNet+LSTM:每一帧都提feature后整视频pooling,或者每一帧提feature+LSTM。缺点,忽略了时间信息,open和close door会分错。
改进C3D:比二维卷积网络有更多的参数,缺点参数量大,不能imagenet pretrain,从头训难训。input 16帧 输入112*112,本文实现了C3D的一个变种,在最顶层有8个卷积层,5个pooling层和2个全联接层。模型的输入是16帧每帧112x112的片段。不同于论文中的实现是,作者在所有的卷积层和全联接层后面加入了BN层,同时将第一个pooling层的temporal stride由1变为2,来减小内存使用,增加batch的大小,这对batch normalization很重要。
双流网络:LSTM只抓住高层的卷积后的信息,底层的信息在某些例子上也非常重要,LSTM train 消耗很大。RGB帧和10个堆叠的光流帧,光流输入是2倍的光流帧(x,y水平垂直的channel),可以有效train
新双流:后面的融合部分改为3D卷积,3D pooling
双流 inflated 3D卷积:扩展2D卷积basemodel为3D basemodel卷积,卷积核和pooling增加时间维,尽管3D卷积可以直接学习时间特征,但是将光流加进来后会提高性能。
如果2D的滤波器为N*N的,那么3D的则为N*N*N的。具体做法是沿着时间维度重复2D滤波器权重N次,并且通过除以N进行归一化。可以类比TSN光流网络的第一个卷积层的初始化方式。
对于3D来说,时间维度不能缩减地过快或过慢。如果时间维度的感受野尺寸比空间维度的大,将会合并不同物体的边缘信息。反之,将捕捉不到动态场景。因此改进了BN-Inception的网络结构。在前两个池化层上将时间维度的步长设为了1,空间还是2*2。最后的池化层是2*7*7。训练的时候将每一条视频采样64帧作为一个样本,测试时将全部的视频帧放进去最后average_score。除最后一个卷积层之外,在每一个卷积后面都加上BN和relu。一块K40 GPU上,一个batch内跑15个视频片段
I3D双流网络:rgb和光流是分开训练的,测试时将它们预测的结果进行平均


在训练期间,spatial上是先将原始帧resize成256*256的,然后随机剪裁成224*224的。在temporal上,尽量选择前面的帧以保证足够光流帧的数目足够多。短的视频循环输入以保证符合网络的input_size。在训练中还用到了随机的左右翻转。
测试的时候选用中心剪裁224*224,将整条视频的所有帧输入进去,之后average_score
实验测试256x256的视频并没有提高,测试时左右翻转video,训练时增加额外的augmentation,如phonemetric,可能有更好的效果。
Kinectics:人类动作
1. Person Actions(singular): (画画,喝东西,笑,击打)
2. Person-Person Actions: (拥抱,亲吻,握手)
3. Persion-Object Actions: (打开礼物,修剪草坪,洗碟子)
4. 细粒度需要时间推理来区分: 游泳的不同泳姿。有的需要着重于物体来区分,玩不同的乐器。
400类共计24万个视频,视频时长约为10s,trimmed 视频,测试集每类100个clip
Kinetics 数据集介绍
分类结果:
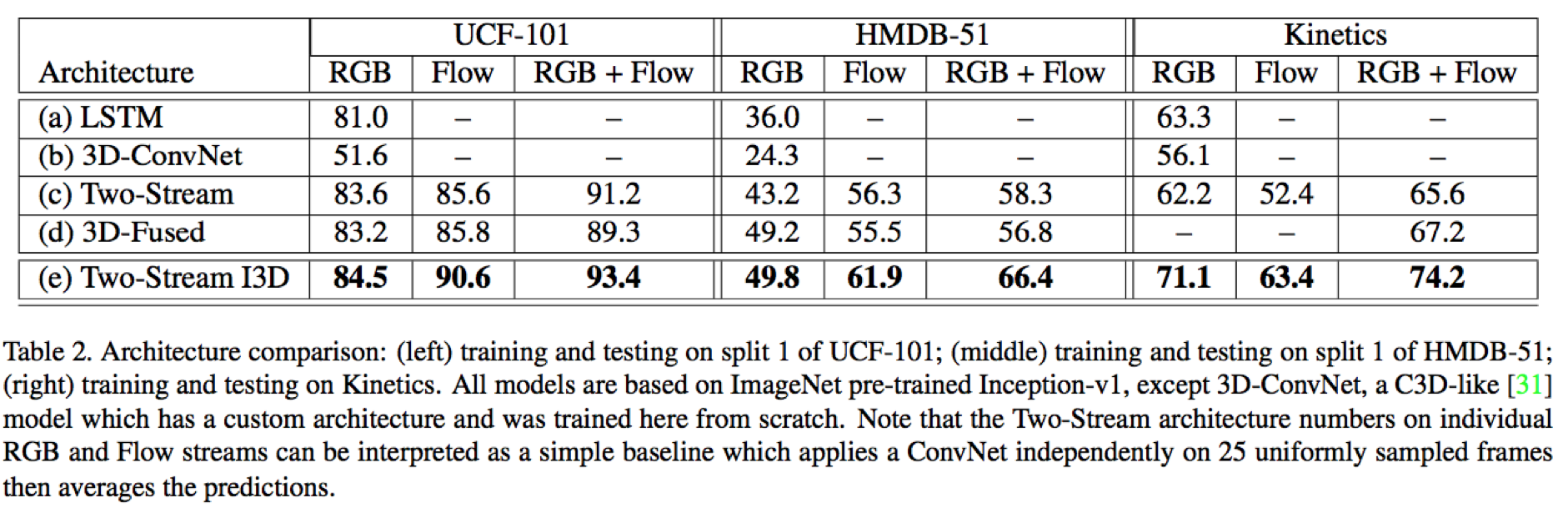

参考自:知乎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号