

python-看代码YOLOv3学习
-
file.readline():作为列表返回文件中的所有行,其中每一行都是列表对象中的一项.
-
str.replace(old, new[, max])
-
rstrip():删除string字符串末尾的指定字符,默认为空白符,包括空格、换行符、回车符、制表符。
-
使用pytorch必须满足tensor格式。 transforms.ToTensor()
-
unsqueeze()函数起升维的作用,参数表示在哪个地方加一个维度。squeeze()函数起降维的作用,参数表示减去哪一个维度。
-
.expand( ):其将单个维度扩大成更大维度,返回一个新的tensor.
a = torch.Tensor([[1,2]]) b = a.expand(4, 2)
-
img.shape[1:]:表示1:的维度
-
torch.from_numpy(np.loadtxt(label_path)
np.loadtxt(label_path):是txt格式。使用torch.from_numpy():将numpy支持的ndarry格式 转换为 pytorch可以处理的tensor格式
-
# tensor索引 a=torch.rand(2,3) tensor([[0.2678, 0.7252, 0.4454], [0.9949, 0.9347, 0.4161]]) b=a[:,1:] tensor([[0.7252, 0.4454], [0.9347, 0.4161]]) torch.Size([2, 2])对比:
c=torch.zeros(2,3) c[:,1:]=torch.tensor([[2, 1], [1, 2]]) print(c) tensor([[0., 2., 1.], [0., 1., 2.]]) c.size() torch.Size([2, 3])
d=torch.tensor[1,2]
print(d[-1])2
- list.pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
- shortcut层(残差):输入层一般是两个(目前还没出现多余两个的情况),实现两个张量相加。
route层(路由):相当于引入和concat两个操作,当route的输入只有一个时,就只有引入的作用,当输入大于一个的时候,会将所有的引入再执行一步concat,增加route层的输出维度。YOLOv3中route层的输入可以是1、2、4个。链接 - list tuple dict set numpy tensor对比:
- List:
- 定义:列表,使用一对方括号[ ]。列表的数据可以改变。
- 常用函数:
- append(x) ,在列表尾部追加单个元素,添加多个元素会报错,可改用list.extend()
- list.extend(), 在列表尾部追加列表元素
- insert(i, elem),在指定位置x插入元素
- list.pop(index), 根据索引index删除元素
- list.remove(element) ,根据元素value删除元素
- 备注:del是python语句,而不是列表方法,无法通过list来调用。使用del可以删除一个元素,当元素删除之后,位于它后面的元素会自动移动填补空出来的位置。
- list.reverse() 对list元素对调,等同于systems[start:stop:step] systems[::-1]
- list.sort(key=..., reverse=...) reverse=True或者False代表正序或者反序
- 等同于 sorted(list, key=..., reverse=...)
- len()求长度
- list.copy()
- count(x) 返回对象x在列表中出现的次数
- tuple:
- 定义:元组,使用(),tuple的标志在于中间的‘,’(逗号),而不是小括号,元组数据不可改变
- 注意事项:
- tuple1 = (1),这样创建的元组是错误的,tuple1是int类型,应该写成(1,)
- 元组的索引用tuple[y]的形式,而不是tuple(y)
- 常见函数和list类似
- len()求元组长度
- dict:
- 定义:字典,使用{},用过key查找value,key的类型可以是字符串或者是数值
- 常见函数:
- dict.keys() 返回dictionary的key
- dict.values() 返回dictionary的value
- dict.items() 返回可遍历的(键, 值) 元组数组 forkey,valuesindict.items():
- set:
- 定义:集合,无序不重复(自动去重),set([list ])
- 常见函数:
- set.add(elem) 增加单个元素
- set.update(set) 增加多个元素
- set.delete(value)/set.discard(value) 删除某个元素,当元素不在set中,discard不会报错
- tensor:
- 定义:张量,gpu界的numpy
- numpy:
- 定义:数学函数组,核心ndarray
- numpy和tensor
-
Pycharm从一个断点运行到下一个断点:在设置的第一个断点和第二个断点之间,不用一步一步的debug下去,我们可以点击 ‘Resume Program’ 按钮直接运行到下一个断点处。如图:

- [w indexingutils.h:30] warning: indexing with dtype torch.uint8 is now deprecated, please use a dtype torch.bool instead. (function expandtensors)
将:uint8转为bool值 或者 屏蔽userwarning 链接 - hasattr():用于判断对象是否包含对应的属性。 hasattr(object, name) 如果对象有该属性返回 True,否则返回 False。
-
# 高级循环语句
>>> L = [1, 2, 3, 4, 5, 6] >>> L = [x for x in L if x % 2 != 0] >>> L [1, 3, 5] -
OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "F:\APP\install\Anaconda\envs\pytorch\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.
解决方法:
1、重启pycharm
长时间运行pycharm可能会在后台占用大量内存。重启清除内存也许会解决问题。
但对我来说并无作用。
2、修改batch_size
batch_size是每次训练量的值, 将它设置小一点。
3、把num_workers设置为0
num_workers即工作进程数,在dataloader加载数据时,num_workers可以看作搬砖的工人,将batch加载进RAM,工人越多加载速度越快。一般这个数量设置值是自己电脑/服务器的CPU核心数。
如果num_worker设为0,意味着每一轮迭代时,dataloader不再有自主加载数据到RAM这一步骤(因为没有worker了),而是在RAM中找batch,找不到时再加载相应的batch。
4、调大页面文件的大小具体操作如下, 直接搜索 高级系统设置:

根据自己D盘可用空间的大小来设置一下虚拟内存的大小, 最后点击确认, 再重新运行程序,

win10虚拟内存设置多少合适:
2G-6G:建议将 初始大小和最大值 = 物理内存的1-2倍,比如2G设置为4096MB(2倍),3G设置为4608MB(1.5倍),4G内存先设置为4096MB(1倍,若不够,则在加)
6-8G或更大:a:选则自动管理
b:初始大小 =物理内存的1/2倍,最大值 <=物理内存的一倍,因为物理内存越大,虚拟内存就没必要设置太大了。 -

这里的module[0]

-
f-string用大括号
{}表示被替换字段,其中直接填入替换内容:>>> name = 'Eric' >>> f'Hello, my name is {name}' 'Hello, my name is Eric' >>> number = 7 >>> f'My lucky number is {number}' 'My lucky number is 7' >>> price = 19.99 >>> f'The price of this book is {price}' 'The price of this book is 19.99'f-string的大括号
{}可以填入表达式或调用函数,Python会求出其结果并填入返回的字符串内>>> f'A total number of {24 * 8 + 4}' 'A total number of 196' >>> f'Complex number {(2 + 2j) / (2 - 3j)}' 'Complex number (-0.15384615384615388+0.7692307692307692j)' >>> name = 'ERIC' >>> f'My name is {name.lower()}' 'My name is eric' >>> import math >>> f'The answer is {math.log(math.pi)}' 'The answer is 1.1447298858494002'f-string大括号内所用的引号不能和大括号外的引号定界符冲突,可根据情况灵活切换
'和":>>> f'I am {"Eric"}' 'I am Eric' >>> f'I am {'Eric'}' File "<stdin>", line 1 f'I am {'Eric'}' ^ SyntaxError: invalid syntax若
'和"不足以满足要求,还可以使用'''和""":>>> f"He said {"I'm Eric"}" File "<stdin>", line 1 f"He said {"I'm Eric"}" ^ SyntaxError: invalid syntax >>> f'He said {"I'm Eric"}' File "<stdin>", line 1 f'He said {"I'm Eric"}' ^ SyntaxError: invalid syntax >>> f"""He said {"I'm Eric"}""" "He said I'm Eric" >>> f'''He said {"I'm Eric"}''' "He said I'm Eric"大括号外的引号还可以使用
\转义,但大括号内不能使用\转义:>>> f'''He\'ll say {"I'm Eric"}''' "He'll say I'm Eric" >>> f'''He'll say {"I\'m Eric"}''' File "<stdin>", line 1 SyntaxError: f-string expression part cannot include a backslashf-string大括号外如果需要显示大括号,则应输入连续两个大括号
{{和}}:>>> f'5 {"{stars}"}' '5 {stars}' >>> f'{{5}} {"stars"}' '{5} stars'上面提到,f-string大括号内不能使用
\转义,事实上不仅如此,f-string大括号内根本就不允许出现\。如果确实需要\,则应首先将包含\的内容用一个变量表示,再在f-string大括号内填入变量名:>>> f"newline: {ord('\n')}" File "<stdin>", line 1 SyntaxError: f-string expression part cannot include a backslash >>> newline = ord('\n') >>> f'newline: {newline}' 'newline: 10'f-string还可用于多行字符串:
>>> name = 'Eric' >>> age = 27 >>> f"Hello!" \ ... f"I'm {name}." \ ... f"I'm {age}." "Hello!I'm Eric.I'm 27." >>> f"""Hello! ... I'm {name}. ... I'm {age}.""" "Hello!\n I'm Eric.\n I'm 27." - torch的tensor用法:关于a[...,0]:最后一维的第0个元素;a[...,1]:最后一维第1个元素;a[...,-1]:最后一维最后1个元素。【维度减一】
import torch a=torch.rand(1,2,3,3,4) print(a) a.size() x = a[...,0] y = a[...,1] z = a[...,-1] print(x)
print(y) print(z)
z.size()# a: tensor([[[[[0.1578, 0.2661, 0.2124, 0.9821], [0.3136, 0.9771, 0.0990, 0.1553], [0.1953, 0.4705, 0.3684, 0.1927]], [[0.4483, 0.1841, 0.4749, 0.4508], [0.1209, 0.8046, 0.8651, 0.2798], [0.9502, 0.2675, 0.8904, 0.2796]], [[0.7374, 0.4421, 0.8951, 0.4992], [0.2601, 0.9769, 0.6653, 0.2765], [0.3018, 0.0661, 0.5478, 0.4279]]], [[[0.7572, 0.8530, 0.1233, 0.6978], [0.8521, 0.1720, 0.0356, 0.5281], [0.9379, 0.1205, 0.3705, 0.9528]], [[0.5322, 0.1843, 0.8063, 0.1097], [0.1482, 0.4562, 0.9976, 0.6989], [0.9920, 0.6791, 0.6647, 0.1268]], [[0.4997, 0.0896, 0.9526, 0.0866], [0.3759, 0.4417, 0.9196, 0.1085], [0.0071, 0.4846, 0.4544, 0.9375]]]]]) #a.size() torch.Size([1, 2, 3, 3, 4]) # x: tensor([[[[0.1578, 0.3136, 0.1953], [0.4483, 0.1209, 0.9502], [0.7374, 0.2601, 0.3018]], [[0.7572, 0.8521, 0.9379], [0.5322, 0.1482, 0.9920], [0.4997, 0.3759, 0.0071]]]]) # y: tensor([[[[0.2661, 0.9771, 0.4705], [0.1841, 0.8046, 0.2675], [0.4421, 0.9769, 0.0661]], [[0.8530, 0.1720, 0.1205], [0.1843, 0.4562, 0.6791], [0.0896, 0.4417, 0.4846]]]]) # z: tensor([[[[0.9821, 0.1553, 0.1927], [0.4508, 0.2798, 0.2796], [0.4992, 0.2765, 0.4279]], [[0.6978, 0.5281, 0.9528], [0.1097, 0.6989, 0.1268], [0.0866, 0.1085, 0.9375]]]]) # z.size() torch.Size([1, 2, 3, 3]) -
numpy数组切片操作:
列表用 [ ] 标识,支持字符,数字,字符串甚至可以包含列表(即嵌套)。是 python 最通用的复合数据类型。
-
关于索引:
从左到右索引默认 0 开始,从右到左索引默认 -1 开始。
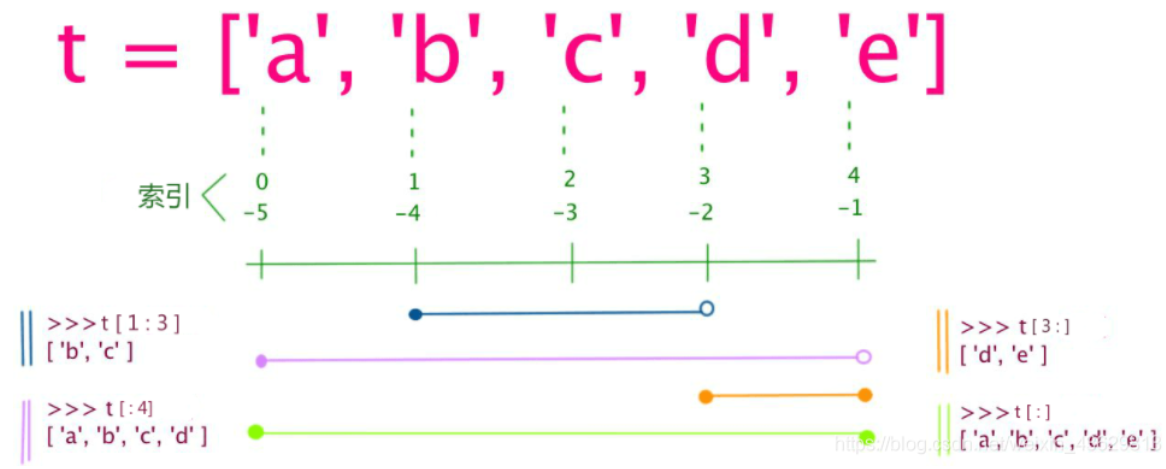
通过冒号分隔切片参数 start:stop:step 来进行切片操作:
import numpy as np a=[1,2,3.4,5] print(a) [ 1 2 3 4 5 ]
- 一维数组
-
一个参数:a[i]
如 [2],将返回与该索引相对应的单个元素。 -
两个参数:b=a[i:j]
b = a[i:j] 表示复制a[i]到a[j-1],以生成新的list对象
i缺省时默认为0,即 a[:n] 代表列表中的第一项到第n项,相当于 a[0:n]
j缺省时默认为len(alist),即a[m:] 代表列表中的第m+1项到最后一项,相当于a[m:5]
当i,j都缺省时,a[:]就相当于完整复制aprint(a[-1]) 取最后一个元素 结果:[5] print(a[:-1]) 除了最后一个取全部 结果:[ 1 2 3 4 ] print(a[1:]) 取第二个到最后一个元素 结果:[2 3 4 5]
-
三个参数:格式b = a[i:j:s]
这里的s表示步进,缺省为1.(-1时即翻转读取)
所以a[i:j:1]相当于a[i:j]s='abcdefg' print(s[0:4] #输出abcd print(s[0:4:2]) #步长为 2(间隔一个位置)来截取,输出ac
当s<0时,i缺省时,默认为-1. j缺省时,默认为-len(a)-1
所以a[::-1]相当于 a[-1:-len(a)-1:-1],也就是从最后一个元素到第一个元素复制一遍。所以你看到一个倒序的东东。print(a[::-1]) 取从后向前(相反)的元素 结果:[ 5 4 3 2 1 ] print(a[2::-1]) 取从下标为2的元素**翻转读取** 结果:[ 3 2 1 ]
-
-
多维数组numpy( ,)
X[n0,n1]是通过 numpy 库引用二维数组或矩阵中的某一段数据集的一种写法。
类似的,X[n0,n1,n2]表示取三维数组,取N维数组则有N个参数,N-1个逗号分隔。-
取元素 X[n0,n1]
这是最基本的情况,表示取 第0维 的第 n0 个元素,继续取 第1维 的第 n1个元素。如 X[2,2] 表示第0维第2个元素[20,21,22,23],然后取其第1维的第2个元素即 22; -
切片 X[s0:e0,s1:e1]
这是最通用的切片操作,表示取 第0维 的第 s0 到 e0 个元素,继续取 第1维 的第 s1 到 e1 个元素(左闭右开)。如 X[1:3,1:3] 表示第0维第(1:3)个元素[[10,11,12,13],[20,21,22,23]],然后取其第1维的第(1:3)个元素即 [[11,12],[21,22]]; -
切片特殊情况 X[:e0,s1:]
特殊情况,即左边从0开始可以省略X[:e0,s1:e1],右边到结尾可以省略X[s0:,s1:e1],取某一维全部元素X[:,s1:e1],事实上和Python 的 序列切片规则是一样的。
常见的 X[:,0] 则表示 第0维取全部,第1维取0号元素; - 代码实例
import numpy as np X = np.array([[0,1,2,3],[10,11,12,13],[20,21,22,23],[30,31,32,33]]) #X 是一个二维数组,维度为 0 ,1;第 0 层 [] 表示第 0 维;第 1 层 [] 表示第 1 维; # X[n0,n1] 表示第 0 维 取第n0 个元素 ,第 1 维取第 n1 个元素 print(X[1,0]) # X[1:3,1:3] 表示第 0 维 取 (1:3)元素 ,第 1 维取第(1:3) 个元素 print(X[1:3,1:3]) # X[:n0,:n1] 表示第 0 维 取 第0 到 第n0 个元素 ,第 1 维取 第0 到 第n1 个元素 print(X[:2,:2]) # X[:,:n1] 表示第 0 维 取 全部元素 ,第 1 维取 第0 到第n1 个元素 print(X[:,:2]) # X[:,0]) 表示第 0 维 取全部 元素 ,第 1 维取第 0 个元素 print(X[:,0])
输出结果:
10 [[11 12] [21 22]] [[ 0 1] [10 11]] [[ 0 1] [10 11] [20 21] [30 31]] [ 0 10 20 30]
-
-
'Tensor' object does not support item assignment:报错使用torch.FloatTensor()
-
permute(dims):将tensor的维度换位。
参数:一系列的整数,代表原来张量的维度。(比如三维就有0,1,2)
import torch import numpy as np a=np.array([[[1,2,3],[4,5,6]]]) unpermuted=torch.tensor(a) print(unpermuted.size()) # ——> torch.Size([1, 2, 3]) permuted=unpermuted.permute(2,0,1) print(permuted.size()) # ——> torch.Size([3, 1, 2])
详细可参考
- 在pytorch中,有几个操作【不改变tensor的内容本身,只是重新定义下标与元素的对应关系】即:不进行数据拷贝和数据的改变,变的是【元数据】。
改变元数据的操作:
- narrow()
- view()
- expand()
- transpose()
- 关于contiguous():
代码1:
x = torch.randn(3, 2) y = torch.transpose(x, 0, 1) print("修改前:") print("x-", x) print("y-", y) print("\n修改后:") y[0, 0] = 11 print("x-", x) print("y-", y)运行结果:
修改前: x- tensor([[-0.5670, -1.0277], [ 0.1981, -1.2250], [ 0.8494, -1.4234]]) y- tensor([[-0.5670, 0.1981, 0.8494], [-1.0277, -1.2250, -1.4234]]) 修改后: x- tensor([[11.0000, -1.0277], [ 0.1981, -1.2250], [ 0.8494, -1.4234]]) y- tensor([[11.0000, 0.1981, 0.8494], [-1.0277, -1.2250, -1.4234]])改变了y的元素的值的同时,x的元素的值也发生了变化。
代码2:x = torch.randn(3, 2) y = torch.transpose(x, 0, 1).contiguous() print("修改前:") print("x-", x) print("y-", y) print("\n修改后:") y[0, 0] = 11 print("x-", x) print("y-", y)运行结果:
修改前: x- tensor([[ 0.9730, 0.8559], [ 1.6064, 1.4375], [-1.0905, 1.0690]]) y- tensor([[ 0.9730, 1.6064, -1.0905], [ 0.8559, 1.4375, 1.0690]]) 修改后: x- tensor([[ 0.9730, 0.8559], [ 1.6064, 1.4375], [-1.0905, 1.0690]]) y- tensor([[11.0000, 1.6064, -1.0905], [ 0.8559, 1.4375, 1.0690]])当调用contiguous()时,会强制拷贝一份tensor,让它的布局和从头创建的一模一样,但是两个tensor完全没有联系。
对比:代码1中y只是浅拷贝,修改y会改变x的元素。使用contiguous后,y为深拷贝。
- 关于tensor赋值,tensor.cat(),tensor.view()
构造一个tensor:a,c,d
import torch a=torch.linspace(1, 120, steps=120).view(2,3,4,5) c=torch.linspace(1, 24, steps=24).view(2,3,4) d=torch.linspace(1, 48, steps=48).view(2,3,4,2) print(a) a.size()
运行结果:
构造b:
b = torch.FloatTensor(a[..., :4].shape)
print(b)
b.size()运行结果:
b的tensor.size()为2,3,4,4。值为任意赋值。a[... , :4]:最后一维的第0,1,2,4个元素。
赋值:
运行结果:b[..., 0] = 0 b[..., 1] = 1 b[..., 2] = 2 b[..., 3] = 3 print(b) b.size()
tensor([[[[0., 1., 2., 3.], [0., 1., 2., 3.], [0., 1., 2., 3.], [0., 1., 2., 3.]], [[0., 1., 2., 3.], [0., 1., 2., 3.], [0., 1., 2., 3.], [0., 1., 2., 3.]], [[0., 1., 2., 3.], [0., 1., 2., 3.], [0., 1., 2., 3.], [0., 1., 2., 3.]]], [[[0., 1., 2., 3.], [0., 1., 2., 3.], [0., 1., 2., 3.], [0., 1., 2., 3.]], [[0., 1., 2., 3.], [0., 1., 2., 3.], [0., 1., 2., 3.], [0., 1., 2., 3.]], [[0., 1., 2., 3.], [0., 1., 2., 3.], [0., 1., 2., 3.], [0., 1., 2., 3.]]]])torch.Size([2, 3, 4, 4])
b[... , 0]:为最后一维的第0个元素赋值。
torch.cat:output = torch.cat( ( b.view(2, -1, 4) * 4, #还原到原始图中 c.view(2, -1, 1), d.view(2, -1, 2), ), -1, ) print(output)运行结果:
tensor([[[ 0., 4., 8., 12., 1., 1., 2.], [ 0., 4., 8., 12., 2., 3., 4.], [ 0., 4., 8., 12., 3., 5., 6.], [ 0., 4., 8., 12., 4., 7., 8.], [ 0., 4., 8., 12., 5., 9., 10.], [ 0., 4., 8., 12., 6., 11., 12.], [ 0., 4., 8., 12., 7., 13., 14.], [ 0., 4., 8., 12., 8., 15., 16.], [ 0., 4., 8., 12., 9., 17., 18.], [ 0., 4., 8., 12., 10., 19., 20.], [ 0., 4., 8., 12., 11., 21., 22.], [ 0., 4., 8., 12., 12., 23., 24.]], [[ 0., 4., 8., 12., 13., 25., 26.], [ 0., 4., 8., 12., 14., 27., 28.], [ 0., 4., 8., 12., 15., 29., 30.], [ 0., 4., 8., 12., 16., 31., 32.], [ 0., 4., 8., 12., 17., 33., 34.], [ 0., 4., 8., 12., 18., 35., 36.], [ 0., 4., 8., 12., 19., 37., 38.], [ 0., 4., 8., 12., 20., 39., 40.], [ 0., 4., 8., 12., 21., 41., 42.], [ 0., 4., 8., 12., 22., 43., 44.], [ 0., 4., 8., 12., 23., 45., 46.], [ 0., 4., 8., 12., 24., 47., 48.]]])torch.Size([2, 12, 7])
A:b原本为(2,3,4,4),经过b.view(2, -1, 4) ,b变为(2,12,4)。说明:-1是自动填写,总长度是2*3*4*4,在不想计算的位置放上-1,电脑会自己计算(2*3*4*4)/(2*3),得到对应的数字。&amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;br&amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;&amp;amp;amp;amp;amp;amp;amp;amp;amp;lt;br&amp;amp;amp;amp;amp;amp;amp;amp;amp;gt;B:torch.cat(inputs, dim=?) 在给定维度上对输入的tensor序列seq进行连接操作。【如有疑问可参考】
【参数】:inputs : 待连接的tensor序列 dim : 选择的扩维,沿此维连接tensor序列。
【返回】:outputs =Tensor -
在pytorch中,常见的拼接函数主要是两个,分别是:stack() 和 cat()
torch.stack():沿着一个新diim对输入tensor序列seq进行连接。 序列中所有的tensor都应该为相同shape。
eg:eg:两个4*3矩阵——>dim = 0:2*4*3 ——>dim = 1:4*2*3 ——>dim = 2:4*3*2
torch.cat():在给定dim上对输入的tensor序列seq进行拼接操作。
eg:两个2*3矩阵——>dim = 0:4*3 ——>dim = 1:2*6
