又是一个失眠的夜晚,凌晨5点!哎,起来工作吧;
先上2张图:
================= 先说Base64吧,可不是百度,都是自己感悟,逐字写的 ==================
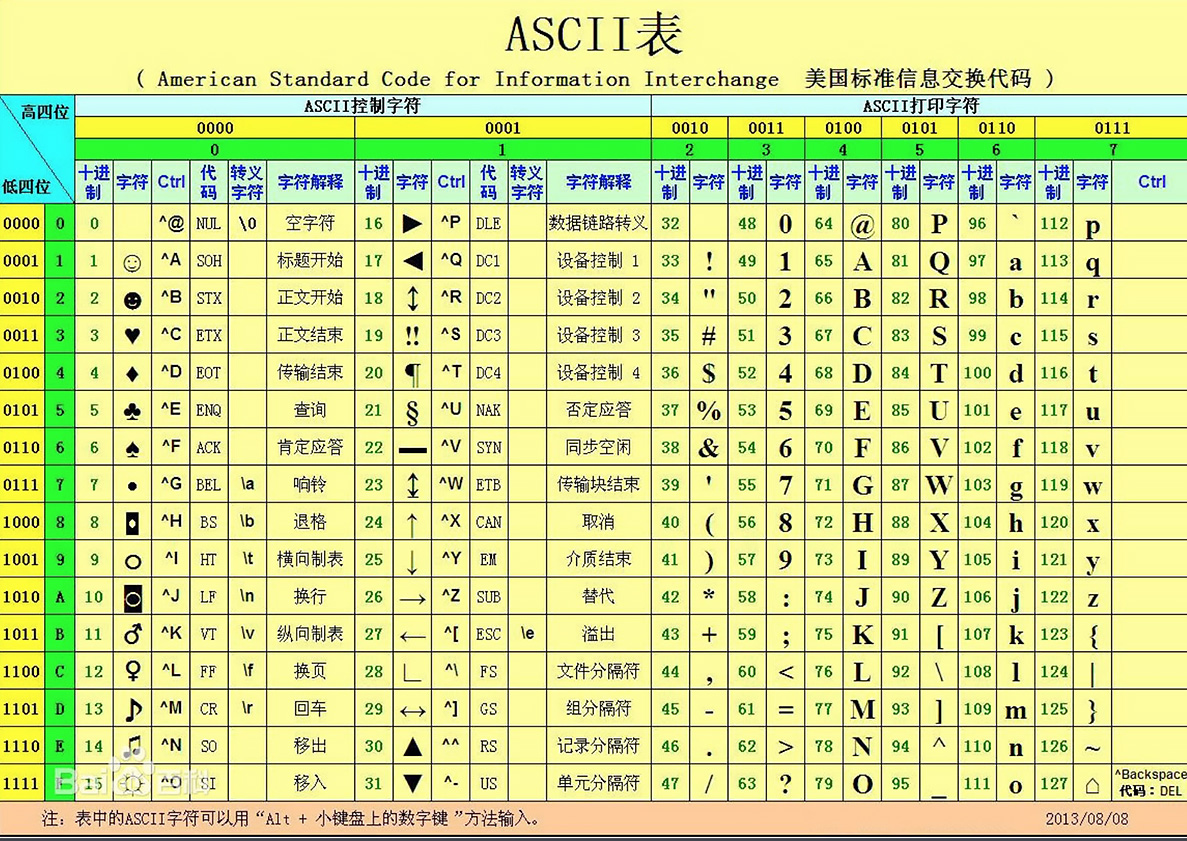
1.首先要理解【可视字符】的概念?
可视字符就是你能看到的字符,我还真不好表达,你要思考一个问题,就是如何把一个字节转换成可视字符,你首先想到的肯定是 ASCII表啊,
你要知道ASCII表里有很多不可视字符,不可视字符,就是控制字符,这些控制字符不可视!那怎么办呢,目前只有2种做法,若有第三种做法
的话可以留言告诉我,我估计没有第三种做法;
做法1:
就是把这个字节,从中间劈开,然后用2个16进制字符来表示,这里要明白什么是16进制,就是 0 - 15,用 0- 9 + A - F(10 - 15)来表示;
一个字节是8bit位,劈开后就是左边4bit + 右边4bit,4bit能表示 多少种情况呢,就是2的4次方,2的4次方是多少呢就是16,所以4bit可以用16进制来表示;
举例:
11111111 --劈开--> 1111 1111 --转换16进制字符表示--> FF;
00000000 --劈开--> 0000 0000 --转换16进制字符表示--> 00;
可见一个字节,可以用2个16进制的字符来表示,而这 0 - 9 + A - F 在ASCII码表里都是【可视字符】,这样就把一个字节变成可视字符了;
做法2:
定义一个转换规则,这个规则如何定义呢,若你是定义这个规则的人,你会如何定义,可以先思考一下?我来说下你接下来的思路做法,这个思路做法估计是大多数程序员的思路;
1. 既然是把一个字节转换成可视字符,那就先找出全球人都能理解的【基本可视】字符,为什么要加个基本呢?$也是可视字符,在美国估计8岁以上的小朋友都知道这个字符代表
什么意思,因为这个就是美元,但是在中国8岁 - 15岁的小朋友 估计有很大一批都不知道这个符号是啥意思,那么就说明$不能算作全球人都能理解的基本字符;
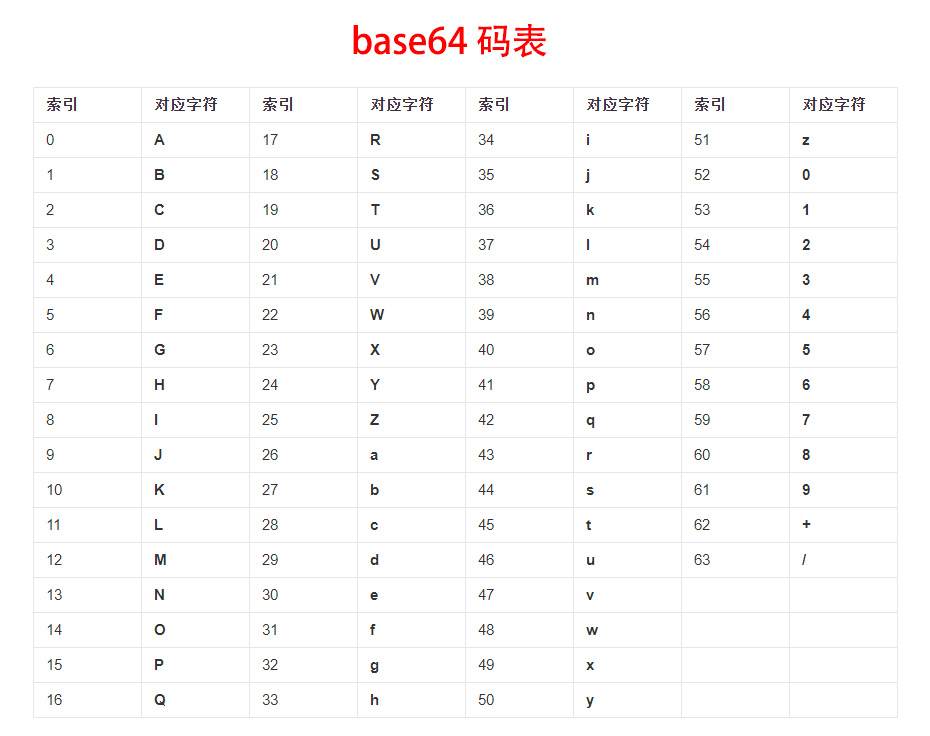
经过分析最终得出,全球人认识基本字符有:
a - z:26个小写字母,西方人肯定都认识,若不认识他们就没法说话,中国的小朋友若不认识就没法读拼音,没法发音,就没法学习语文!
A - Z:26个大写字母,同理;
0 - 9:10个阿拉伯数字,这个西方 和 东方 一致啊,真怀疑 人类本身就是外星人,人类就是来侵略地球的外星坏人,还天天寻找外星人;
好了,有了以上 就是 26 + 26 + 10 = 62个 【全球基本可视字符】,62可不是2的N次方,会导致规则无法定义,那怎么办呢;
2的6次方 = 64,再加2个字符凑够64个不就好办了,加哪2个字符呢,最终设计这个规则的人 决定用 + / 这2个字符,因为他觉得这2个
字符很好,认识 0 - 9 的人 都认识 + / ,因为没有 + / 就无法计算啊,真是操蛋 为什么不用 - * 号呢,开玩笑,可能 有更深层的原因
比如 这个 * 号,在西方 就是乘法符号,在中国 乘法符号 一个叉 x ,呵呵;
既然他们决定 使用 + / 这2个符号了,那么就凑够了64个基本字符了;就是说终于找出全球人 都认识的 基本字符,共计64个;
2. 完成了思路1后,你接下来会思考,一个字节 如何转换成 这64个基本字符的问题;
64 = 2的6次方,就是说 需要6bit为一组;这样就能表示,就是说bit的总数 需要是6的倍数;
而1个字节是8bit,那么导致bit的总数一定是8的倍数;
啊!!!,计算机存储或网络bit的总数一定是8的倍数,而我们需要6的倍数,8 * ? = 6 * ?;
1个字节 是 8 bit;若6bit为一组,那还剩2bit 怎么办;
2个字节是 16 bit,若6bit为一组,那还剩4bit 怎么办;
3个字节是 24bit,正好4组,24 / 6 = 4;
你会发现,只要【字节】的总数 是 3的倍数,就会【bit的总数】正好是 6的倍数;正好符合我们的要求;
即3种情况,%是取余的意思:
A:字节总数 % 3 = 0,正好
B:字节总数 % 3 = 1,余数为1个字节,需要考虑 剩余的 2 bit问题,需要填补4个bit;
C:字节总数 % 3 = 2,余数为2个字节,需要考虑 剩余的 4bit问题,需要填补2个bit;
针对B、C 分别需要填补4bit、2bit,来组合成6bit;既然你填补了 ,那么就要有个标记来区分;
即3种情况:
1. 没填补;尾部不追加;
2. 填补了4bit,尾部追加2个=来标记;
3. 填补了2bit,尾部追加1个 = 来标记;
一个 = 表示填补了2bit;2个 = 就表示填补了4bit;
为什么要用 = 这个符号呢,是因为这个 符号 也是 全球人 都认识 都统一的符号,+ / 总得有 = 号来得出最终的结果吧;
3.有了以上2步思路,那么你还需要设计一个 0 - 63的码表,来指示一组6bit 所表示的基本可视字符,就是上图的Base64码表;
然后就设计完成了,把一个字节 变成 基本可视字符的规则,以上这个思路的最终规则就是Base64现在的规则;
========================================================
1. 什么是Base64?
Base64是把二进制或字节转成【可视】字符(binary-to-text)的一种编码;
Base64 中的 Base是关键,就是全球人 都认可的 最基本的字符,Base就是根基的意思;
2.为什么要Base64?
Aes、Rsa 对称与非对称加密场景,加密后出来的都是字节数组,需要把字节数组转换为可视字符;
举例:加密后得出3个字节,你需要把3个字节转成能看到的字符,若直接根据AscII码表来转换,有的控制字符,不可视;
3. MD5为什么不Base64输出?
没有必要,MD5是单向算法,他就是算出来很大的整数值,值足够大能表示很多东西的唯一,
算出来最终是16个字节,固定16个字节,那么就是说这个值能表示的最大值为:2的128次方 够大吧,地球上的每一粒沙子能表示吗;
既然固定16个字节,你若非要用Base64来表示也行,但是通常都是直接 16进制 固定32个16进制字符来表示更直观;
=======================================
用例子来说明 Base64
public class TestMain { public static void main(String[] args) throws UnsupportedEncodingException { String a = Base64.getEncoder().encodeToString("a".getBytes("UTF-8")); String ab = Base64.getEncoder().encodeToString("ab".getBytes("UTF-8")); String abc = Base64.getEncoder().encodeToString("abc".getBytes("UTF-8")); System.out.println(a); System.out.println(ab); System.out.println(abc); } }
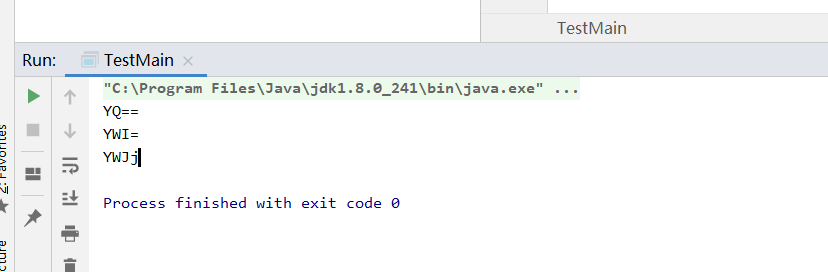
我们来分析 以上 这个例子:
首先看下ascii表,字母 --- 二进制(4位排列)---- 二进制(6位一组排列):
a ---> 0110 0001 ---> 011000 01(按6位一组排列,缺少4位)
ab ---> 0110 0001 0110 0010 ---> 011000 010110 0010(按6位一组排列,缺少2位)
abc ---> 0110 0001 0110 0010 0110 0011 ---> 011000 010110 001001 100011(按6位一组排列,正好,因为 4*6 = 3* 8 = 24)
有了以上二进制,下面再继续说,说明一点 a 若按6位一组排列是不够的,缺少低4位,严重注意一点 a 的 011000 01(这个01是要看成高位,为什么要看成高位,因为看成高位才能表达更多字符,这点切记,想象后面是补的0),这个时候 他们规定了一个规则,就是你需要把最后的二进制01看成6位一组的高位,
然后就可以计算出对应的值:
a ---- 011000 01 --- 24(Y) 16(Q,切记这个01是高位) ==
ab --- 011000 010110 0010 ---- 24(Y) 22(W) 8(I,切记0010是高位,后面你可以想象成还有2个0) =
abc --- 011000 010110 001001 100011 --- 24(Y) 22(W) 9(J) 35(j) 正好,不用补=
========================================= 接下来说下UrlEncode ==========================================
url特殊字符:
| 十六进制 | |||
|---|---|---|---|
| 1 | + | URL 中+号表示空格 | %2B |
| 2 | 空格 | URL中的空格可以用+号或者编码 | %20 |
| 3 | / | 分隔目录和子目录 | %2F |
| 4 | ? | 分隔实际的 URL 和参数 | %3F |
| 5 | % | 指定特殊字符 | %25 |
| 6 | # | 表示书签 | %23 |
| 7 | & | URL 中指定的参数间的分隔符 | %26 |
| 8 | = | URL 中指定参数的值 | %3D |
我们有时候需要在GET的参数中传递参数,例如是byte[]类型的内容,一般来说是转成Base64的编码格式,但是带来一个问题是:base64编码后,里面可能会出现一些字符是url里面冲突的,
例如=+/这些,虽然可以URLEncode进行编码,但这还是会给程序带来一些复杂度或者不确定性。
关于URL编码的详细规范,可以查看RFC 3986, 这里只对我们会涉及的信息做简要说明。
RFC 3986中有如下两个重要规定:
- Url中只允许包含英文字母(a-zA-Z)、数字(0-9)、
-_.~4个特殊字符以及所有保留字符。 - 保留字符包括:
!*'();:@&=+$,/?#[]
另外,还有很多字符,当它们直接放在Url中的时候,可能会引起解析程序的歧义。
这些字符被视为不安全字符,原因有很多。
- 空格:Url在传输的过程,或者用户在排版的过程,或者文本处理程序在处理url的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉;
- 引号以及<>:引号和尖括号通常用于在普通文本中起到分隔Url的作用;
- #:通常用于表示书签或者锚点;
- %:百分号本身用作对不安全字符进行编码时使用的特殊字符,因此本身需要编码;
{}|\^[]`~:某一些网关或者传输代理会篡改这些字符。
这里估计99%的人都会迷糊,呵呵,我将近10多年的经验,才知道答案!!!
首先要知道3个标准:
1. 针对浏览器地址栏URL的标准,在1994年订立的RFC1738中。(显然已过时,可忽略)
对字符串中除了-_.三个字符之外的所有非字母数字字符都替换成百分号(%)后跟两位十六进制数。
十六进制数中字母必须为大写。
http://tools.ietf.org/html/rfc17382. 依然是针对浏览器地址栏URL的标准,在2005年定义的RFC3986中,将针对- _.~(可见又扩充了一个波浪线字符)四个字符之外的所有非字母数字字符进行百分号编码。
http://tools.ietf.org/html/rfc39863.这个不是针对浏览器地址栏的,而是针对Post请求的form传递数据的,在W3C找到HTML标准的说明
http://www.w3.org/TR/REC-html40/interact/forms.html#h-17.13.4
在这里清楚的看到编码方式是根据ContextType的不同而区别对待的,在form的ContextType是[x-www-form-urlencoded]的时候会对form中的键/值对进行编码,空格被转义成+,
其他字符按照[RFC1738]标准处理成%HH的形式,基本问题就出在这里;
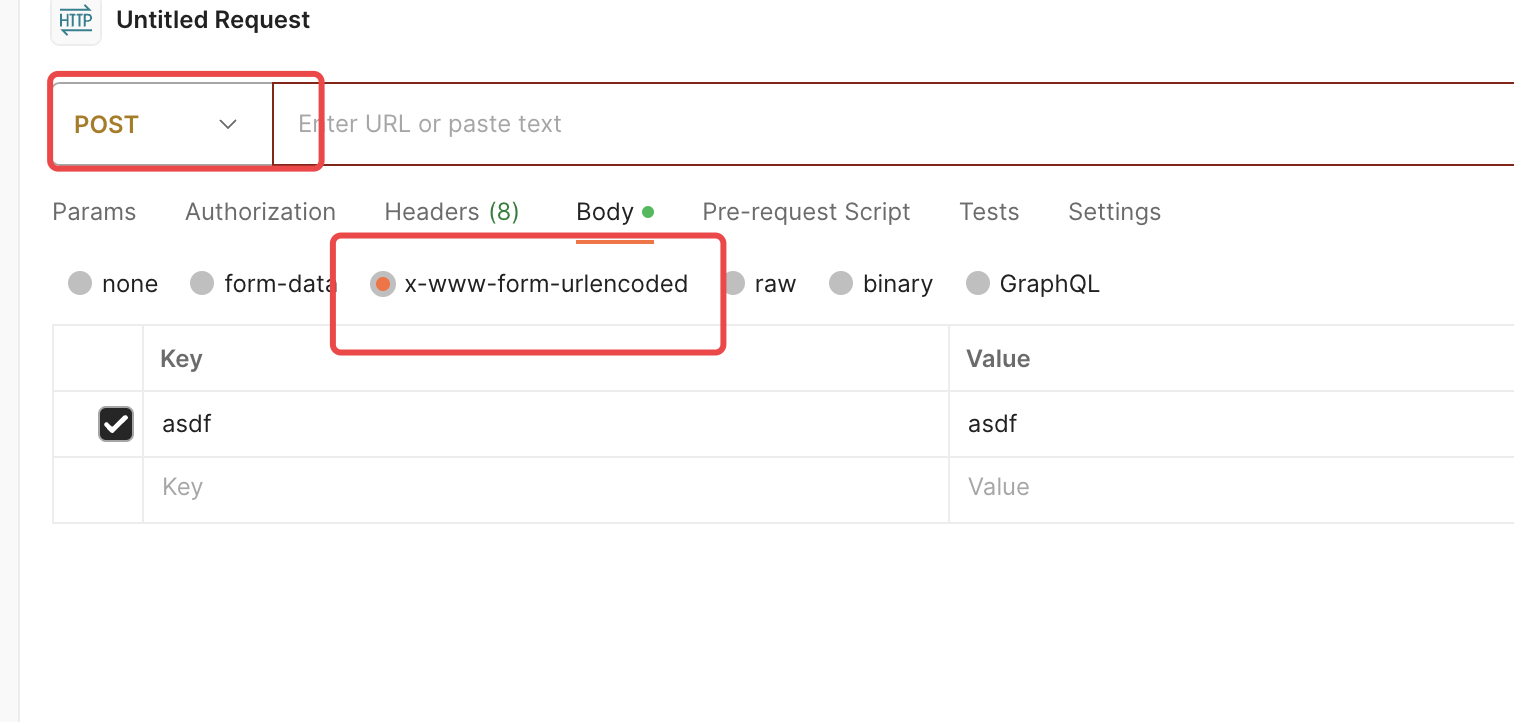
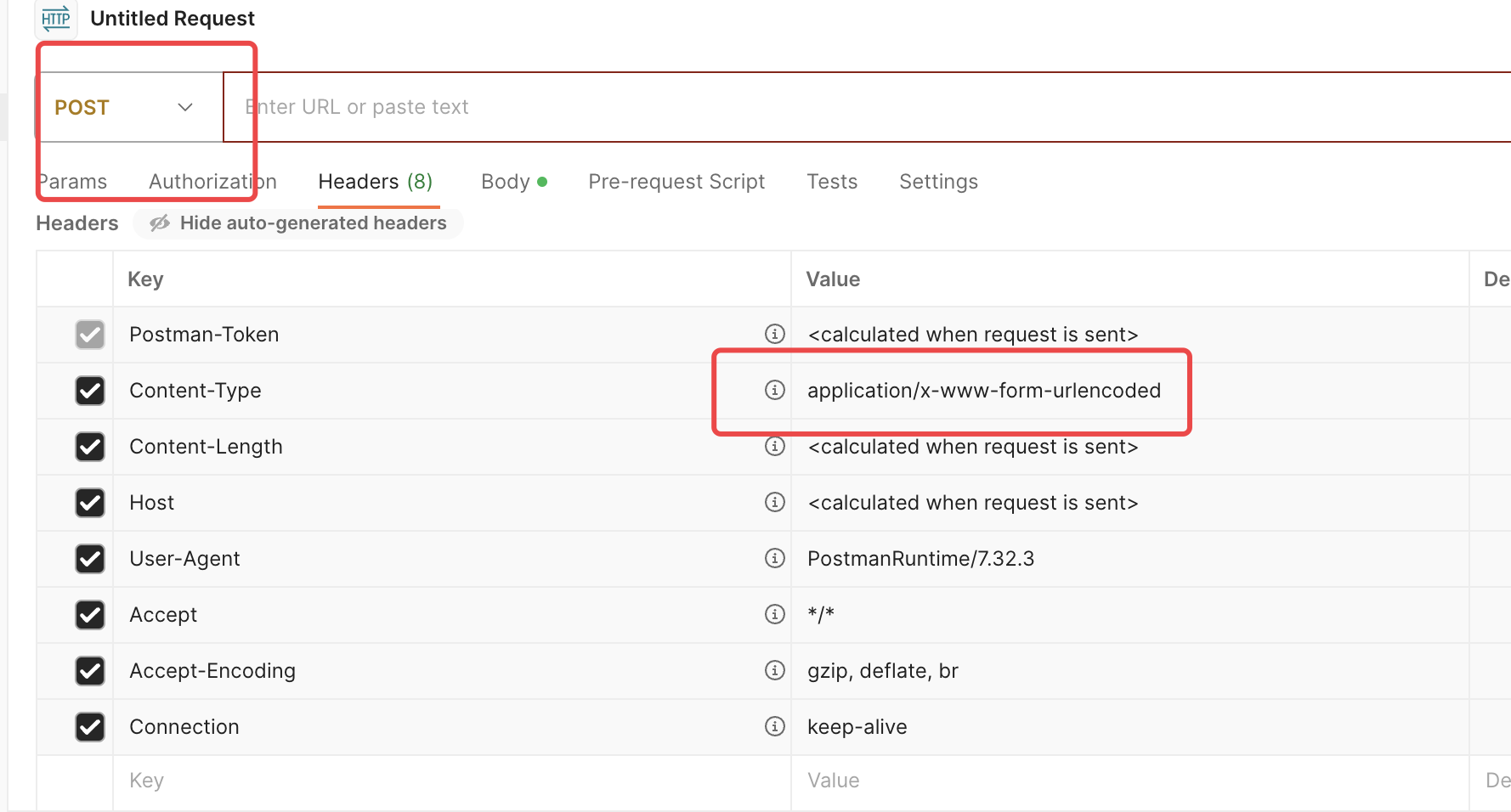
出现歧义的地方,我来说下:
1. 你要区分 get请求 与 application/x-www-form-urlencoded,我来举个例子:
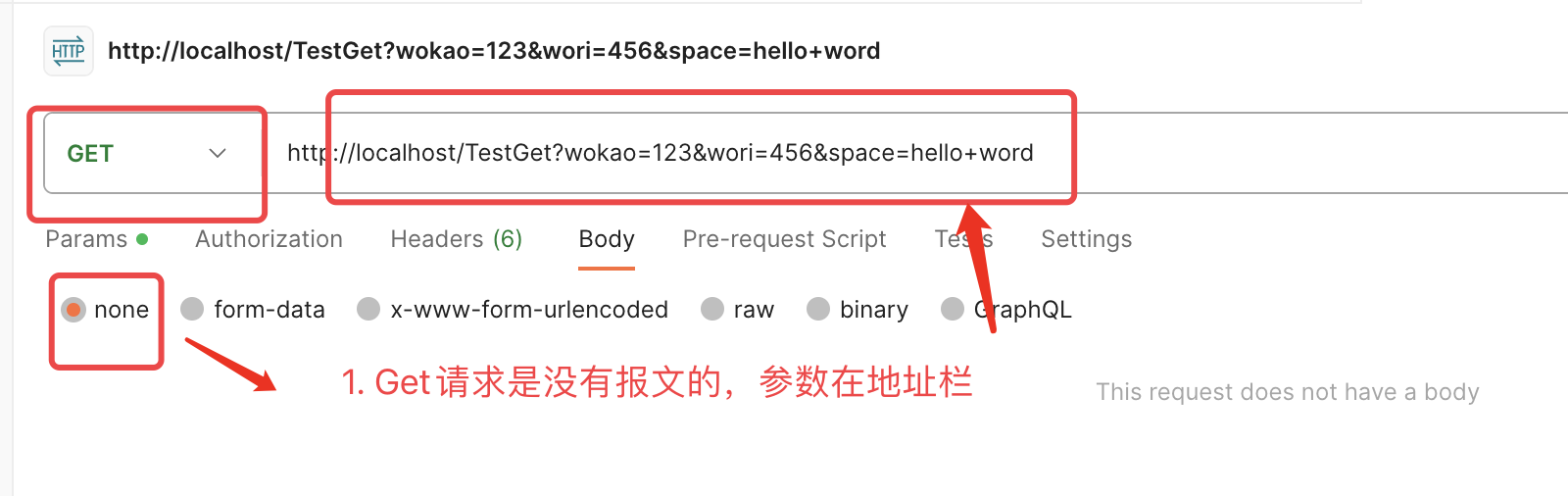
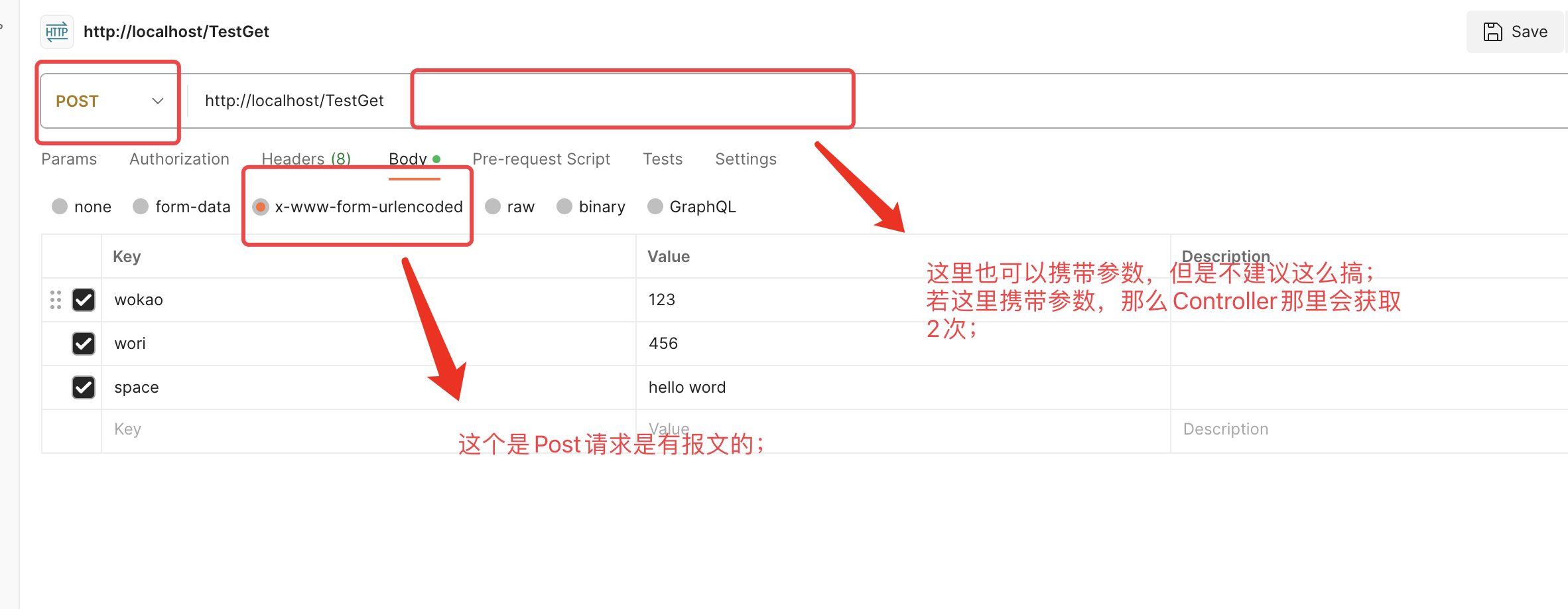
知道了以上两种的区别后,针对以上2种,有两套标准;
这2套标准有个细微的差异,那就是空格的问题;
get 请求的话,要求空格 变成 %20;
post_form的话,要求空格变成 + ;
现实中你会发现,别人都帮你搞定了,就是说 get请求的话,你把空格弄成+也没有问题,post_form弄成%20;也没有问题;出现问题的时候再去解决,你有个依据就行;
那么接下来谈一下Java里的 UrlEncoder

System.out.println(URLEncoder.encode("hello word", "utf-8")); // hello+word可以看到Java的 URLEncoder是 遵循 post_form规范的,真的吗?

总结:http协议中 有post和get提交:
1.如果是get提交 或者是路径的话 如: http://www.bai du.com?wo=he he&ni=abc 就应该遵循RFC1738、RFC2396;就变成:http://www.bai%20du.com?wo=he%20he&ni=abc;
2.如果是post提交:因为post提交的参数依然是被弄成键值对的方式传递的类似GET的QueryString方式,即需要提交的参数应该是: wo=he he&ni=abc;但是由于 html是一种常用语言,它里面有post提价方式,他也有自己的规范,他规定post生成的键值对参数中 参数的值如果有空格应该编码成+号(注意不是%20)见上面链接打开后的下图:

Java官方的URLEncoder.encode 实际上是为了post请求的content-type为x-www-form-urlencoded来设计的。所以没有什么bug可言。
结论:
1.资源路径中含有空格时应该转码为%20,
举例:http://www.baidu.com/he he/index.jsp -----> http://www.baidu.com/he%20he/index.jsp
2.get请求的QueryString里含有空格的话应该转码为%20;
举例:http://www.abc.com?wo=he he ------> http://www.abc.com?wo=he%20he
3.post请求时,content-type = application/x-www-form-urlencoded (一般默认都是这个)时,空格应该转码为+;
举例:向http://www.abc.com/发post请求,参数的值有空格,最终的参数键值对是 wo=he+he;
2017.11.05补充。。。。。。。。。。。。。。
在Delphi中;
get请求的时候可以用,TNetEncoding.URL.EncodeQuery,
post请求的时候可以用,TNetEncoding.URL.EncodeForm
2019-11-03 补充。。。。。。。。。。。。
procedure TfrmAesForm.Button3Click(Sender: TObject); begin { 空格的问题,根据国际URL标准,GET请求是包含在路径里的,所以与Post请求的标准不同 GET请求参数包含在URL路径里,他们有一个标准 RFC1738,RFC3986; 此标准要求空格转为%20 POST请求参数不包含在URL路径里,他们的参数传输有一个自己的标准 application/x-www-form-urlencoded MIME format; 此标准要求空格转为+ } Memo1.Lines.Add(TNetEncoding.URL.EncodeQuery(' '));//%20 GET请求的参数用这个URLEncode Memo1.Lines.Add(TNetEncoding.URL.EncodeForm(' '));//+ POST请求的参数用这个URLEncode Memo1.Lines.Add(TNetEncoding.URL.Encode(' '));//+ get提交的时候不要用这个,这个会搞成+ end;
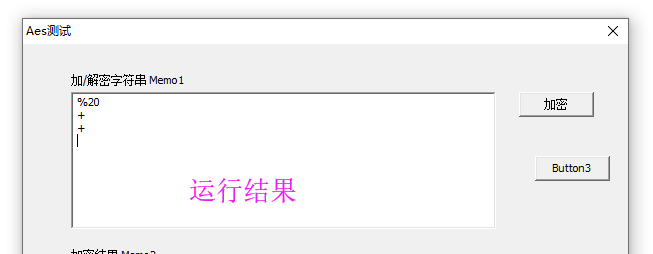
=======================================================================================================================
好了,再来说下这个Base64URL;
我们知道 Base64会出来3个特殊字符,+、/、=,很遗憾这3个字符,都是URL特殊意义的字符;尤其是+号,跨越2个标准,非常容易产生意义,从而
导致Token校验失败;/、=这2个字符基本没有什么异议,get和post_form都会被转换成%XX形式;
System.out.println(URLEncoder.encode("/", "utf-8")); //%2F
System.out.println(URLEncoder.encode("=", "utf-8")); //%%3D
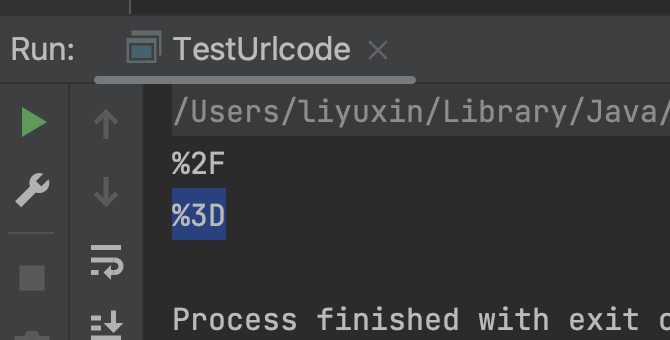
这样来回转换标准,各种转换会导致 错误的概率上升;
尤其是Token这样重要的字符串,有的时候需要get请求,有的时候需要http头部,有的时候需要post_form,有的时候需要post_json;
get 需要 urlencode() 采用get标准
post_form 需要 urlencode 采用HTML 标准
http头部,直接base64就可;
post_json,也是二进制的,也是直接 base64即可;
为了避免转换,减少出错的概率,token最好设计成不需要urlencode,绕开这2个标准;
于是就有了接下来的Base64Url,看定义:


这样做后,开发中 与 token有关的坑就会消失,就是说 无论是 get 还是 post 还是其它请求,token 都不需要 关心 + 号的问题和 urlEncode UrlDecode的问题。
这里你可能有个疑问,那就是编码时,把末尾的=标记去除了,那解码时怎么接,没有标记符号了怎么解,答案是:
1Byte 示例:Base64("a") ,需要补4bit 需要2个等号 YQ==
2Byte 示例:Base64("ab") ,需要补2bit 需要1个等号 YWI=
3Byte 示例:Base64("abc") ,需要补4bit 需要2个等号 = YWJj
你会发现一个规律,就是Base64出来的结果在字符串一定 /4 整除,所以当尾部的=号被消掉后,依然是可以解码的,Base64Url解码方式:
1)把"-"替换成"+"
2)把"_"替换成"/"
3)(计算BASE64URL编码长度)%4
a)结果为0,不做处理
b)结果为2,字符串添加"=="
c)结果为3,字符串添加"="
Java里的方式为:
public static void main(String[] args) throws UnsupportedEncodingException {
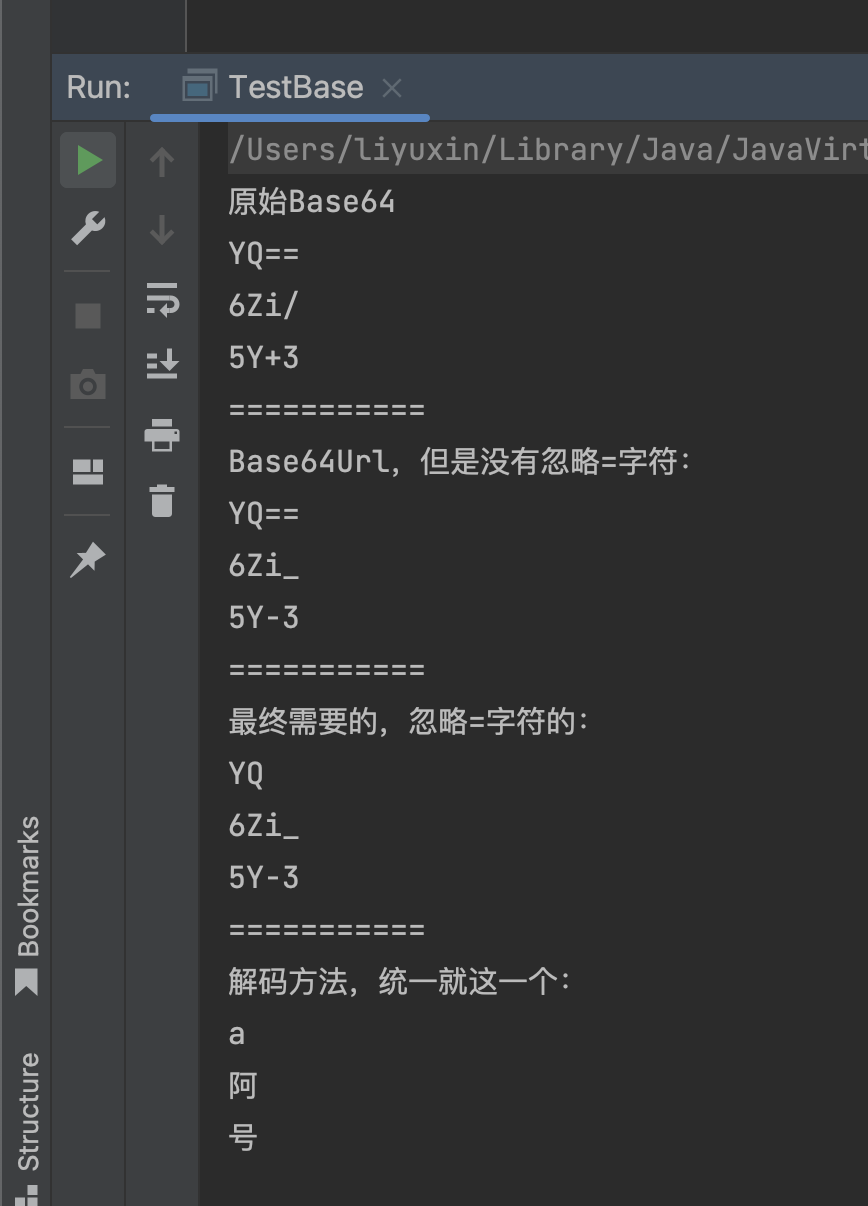
System.out.println("原始Base64");
System.out.println(Base64.getEncoder().encodeToString("a".getBytes(StandardCharsets.UTF_8)));
System.out.println(Base64.getEncoder().encodeToString("阿".getBytes(StandardCharsets.UTF_8)));
System.out.println(Base64.getEncoder().encodeToString("号".getBytes(StandardCharsets.UTF_8)));
System.out.println("===========");
System.out.println("Base64Url,但是没有忽略=字符:");
System.out.println(Base64.getUrlEncoder().encodeToString("a".getBytes(StandardCharsets.UTF_8)));
System.out.println(Base64.getUrlEncoder().encodeToString("阿".getBytes(StandardCharsets.UTF_8)));
System.out.println(Base64.getUrlEncoder().encodeToString("号".getBytes(StandardCharsets.UTF_8)));
System.out.println("===========");
System.out.println("最终需要的,忽略=字符的:");
System.out.println(Base64.getUrlEncoder().withoutPadding().encodeToString("a".getBytes(StandardCharsets.UTF_8)));
System.out.println(Base64.getUrlEncoder().withoutPadding().encodeToString("阿".getBytes(StandardCharsets.UTF_8)));
System.out.println(Base64.getUrlEncoder().withoutPadding().encodeToString("号".getBytes(StandardCharsets.UTF_8)));
System.out.println("===========");
System.out.println("解码方法,统一就这一个:");
System.out.println(new String(Base64.getUrlDecoder().decode("YQ"), StandardCharsets.UTF_8));
System.out.println(new String(Base64.getUrlDecoder().decode("6Zi_"), StandardCharsets.UTF_8));
System.out.println(new String(Base64.getUrlDecoder().decode("5Y-3"), StandardCharsets.UTF_8));
}
Java官方的Base64Url为:
编码:Base64.getUrlEncoder().withoutPadding().encodeToString("xxx".getBytes(StandardCharsets.UTF_8));
解码:new String(Base64.getUrlDecoder().decode("xxx"), StandardCharsets.UTF_8);Delphi 官方的Base64Url为:
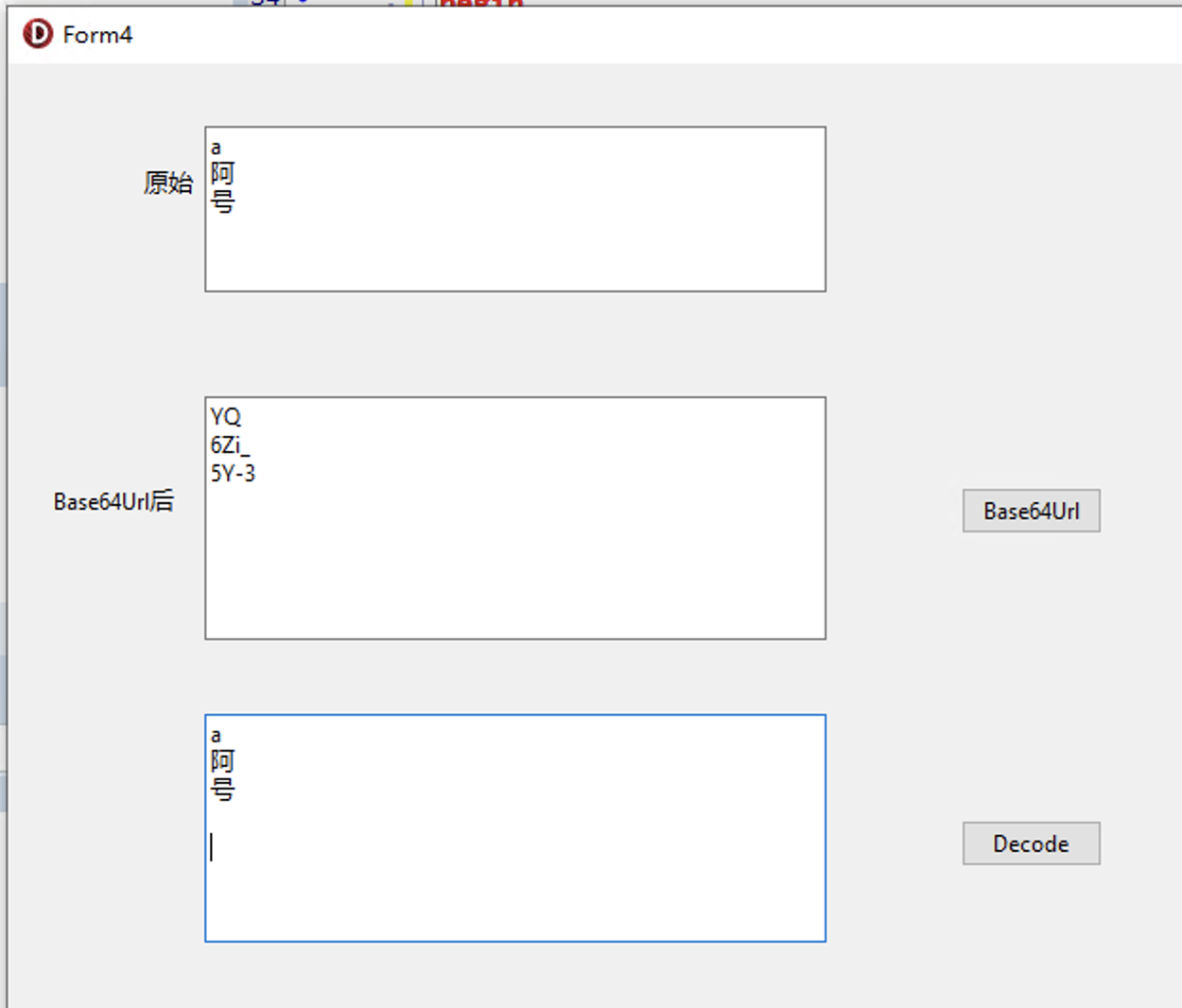
procedure TForm4.btn1Click(Sender: TObject);
begin
var strs := mmo1.Lines.Text.Split([sLineBreak]);
mmo2.Lines.Clear;
for var str in strs do
begin
mmo2.Lines.Add(TBase64URLEncoding.Base64URL.Encode(str));
end;
end;
procedure TForm4.btn2Click(Sender: TObject);
begin
var strs := mmo2.Lines.Text.Split([sLineBreak]);
mmo3.Lines.Clear;
for var str in strs do
begin
mmo3.Lines.Add(TBase64URLEncoding.Base64URL.Decode(str));
end;
end;TBase64URLEncoding.Base64URL.Encode(str)
TBase64URLEncoding.Base64URL.Decode(str)
-------------
最后不同一下 Base64Url(xxx) != UrlEncode(Base64(xxx));这完全是两码事,是不同的规则定义。
public static void main(String[] args) throws UnsupportedEncodingException {
System.out.println(Base64.getUrlEncoder().withoutPadding().encodeToString("a".getBytes(StandardCharsets.UTF_8)));
System.out.println(Base64.getUrlEncoder().withoutPadding().encodeToString("阿".getBytes(StandardCharsets.UTF_8)));
System.out.println(Base64.getUrlEncoder().withoutPadding().encodeToString("号".getBytes(StandardCharsets.UTF_8)));
System.out.println("===========");
System.out.println(URLEncoder.encode(Base64.getEncoder().encodeToString("a".getBytes(StandardCharsets.UTF_8)), "UTF-8"));
System.out.println(URLEncoder.encode(Base64.getEncoder().encodeToString("阿".getBytes(StandardCharsets.UTF_8)), "UTF-8"));
System.out.println(URLEncoder.encode(Base64.getEncoder().encodeToString("号".getBytes(StandardCharsets.UTF_8)), "UTF-8"));
}
/* 输出:
YQ
6Zi_
5Y-3
===========
YQ%3D%3D
6Zi%2F
5Y%2B3
*/
本文来自博客园,作者:del88,转载请注明原文链接:https://www.cnblogs.com/del88/p/6496825.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号