Protobuf 对比 json
1. protobuf 类似的协议有哪些
Protocol Buffers(protobuf)是一种由Google开发的二进制序列化协议,它定义了一种紧凑的二进制格式,用于高效地序列化结构化数据。与protobuf类似的协议包括:
- Apache Thrift:这是一个由Facebook开发的RPC框架,旨在提供“可扩展的跨语言服务开发”。Thrift不仅支持多种编程语言,还包含一个完整的客户端/服务端堆栈,可以快速实现RPC通信。与protobuf相比,Thrift更加注重于提供RPC功能,并且支持同步和异步通信。
- Apache Avro:Avro是一个数据序列化协议,最初是为Hadoop RPC设计的。它使用JSON来描述数据模式,并且模式和数据是统一存储的,这使得消息具有自描述性。Avro不需要生成stub代码,这与protobuf有所不同。Avro也支持多种编程语言,并且在性能上与protobuf相当。
- eProsima Fast Buffers:这是一个针对性能进行优化的开源序列化引擎,基于CDR(通用数据表示)标准。虽然它在某些方面与protobuf相似,但Fast Buffers更注重于高性能和实时系统。
这些协议都具有高效、跨语言和可扩展性的特点,适用于不同的分布式系统和网络通信场景。在选择适合的序列化协议时,需要考虑系统的具体需求,例如性能、兼容性、动态特性以及RPC功能等因素。
2. 举例:服务端返回有可能3个字段,也有可能4个字段,或n个字段,用json,就没有什么问题,客户端 也不需要升级,若用protobuf ,针对这种服务端返回字段不确定的情形 是否需要 升级客户端
在使用Protobuf时,如果服务端返回的字段是不确定的,确实会带来一些挑战。Protobuf是强类型的,意味着在.proto文件中定义的每个字段都需要在编译时确定。如果服务端返回的字段数量或类型不确定,客户端通常需要事先知道这些字段才能正确解析。
然而,Protobuf 3引入了一种名为Any的类型,它允许你在消息中嵌入任意类型的消息。此外,Protobuf也支持oneof结构,这种结构可以用来表示一个字段可能有多种不同的数据类型,但只能设置其中一个。这些特性为处理不确定字段提供了一定的灵活性。
对于服务端返回字段不确定的情形,有几种方法可以处理,而无需频繁升级客户端:
-
使用
Any类型:你可以将不确定的字段封装在Any类型中。这样,即使服务端添加了新的字段类型,客户端也可以解析已知字段,而忽略不认识的Any字段。 -
使用
oneof结构:如果返回的字段类型是有限的几种,你可以使用oneof来定义这些可能的字段。这样,客户端可以解析它认识的字段,并忽略不认识的字段。 -
扩展字段:Protobuf也支持扩展字段,这允许你在不破坏向后兼容性的情况下添加新的字段。客户端可以忽略它不理解的扩展字段。
-
使用包装类型:对于可选的字段,可以使用Protobuf的包装类型(如
google.protobuf.StringValue、Int32Value等),这样即使某些字段在某些情况下不被设置,也不会破坏消息的格式。
尽管有上述方法可以增加Protobuf的灵活性,但如果服务端返回的字段变化非常大或者频繁变化,使用Protobuf可能会比使用JSON更加复杂。在这种情况下,使用JSON可能更为合适,因为它不需要预先定义结构,可以动态地处理字段的变化。
总的来说,如果服务端返回的字段经常变化或者变化很大,而且你希望客户端能够灵活地处理这些变化而不需要频繁升级,那么JSON可能是一个更好的选择。如果你追求更高的性能和更小的消息体积,并且字段变化不大,那么Protobuf可能更适合你的需求。在选择时,需要根据实际情况进行权衡。
综上2点,1.protobuf 不是未来,还有同类产品在竞争;2. Protobuf 需要 通信的两端 强一致,不像json是松散的;
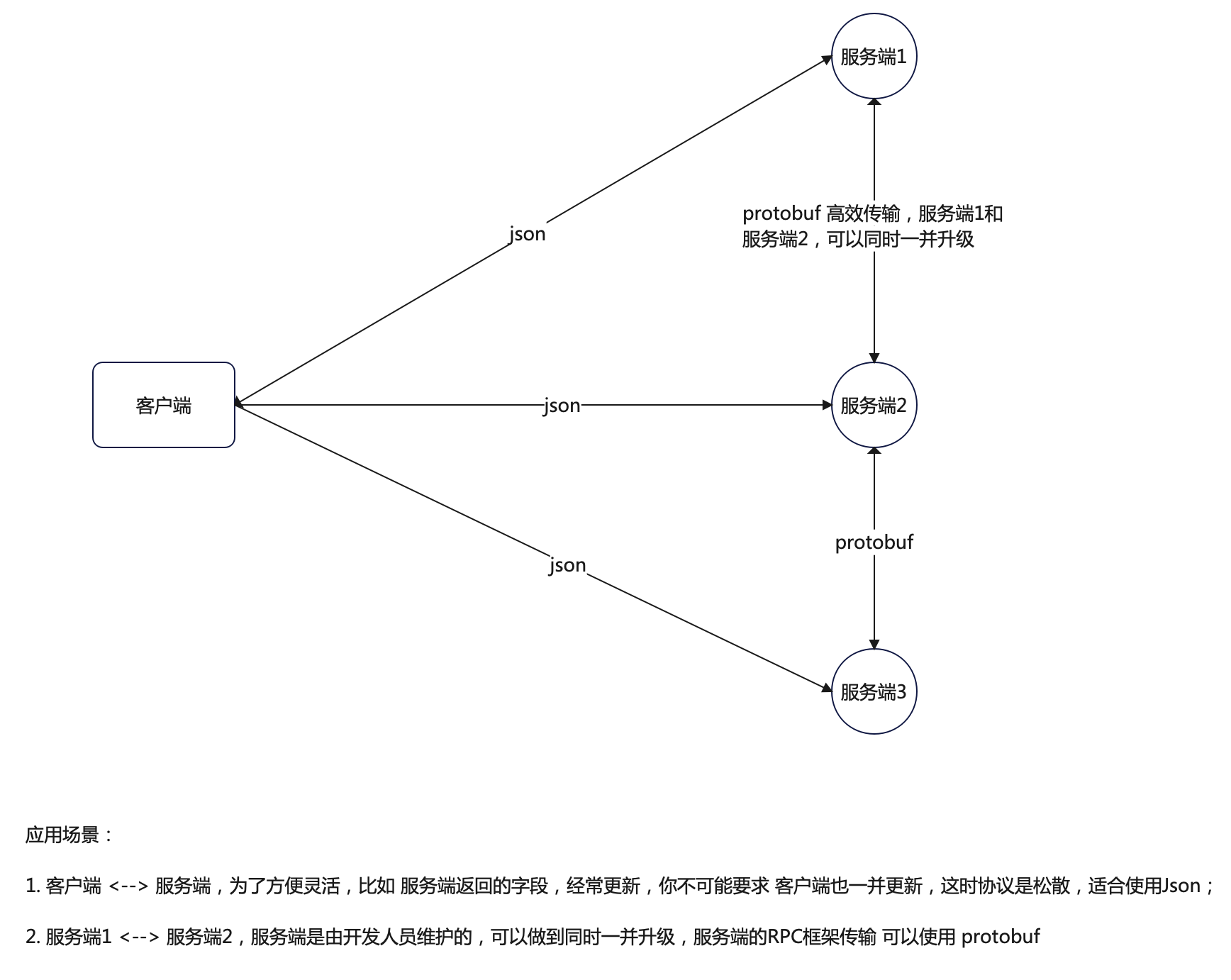
JSON与Protobuf的对比可以从以下几个方面进行:
一、数据格式与可读性
-
JSON:数据格式简洁明了,易于人类阅读和编写。它是一种轻量级的数据交换格式,采用文本格式表示数据,使得数据交换更加直观。
-
Protobuf:数据格式为二进制,不直接可读,需要通过专门的工具或库进行序列化和反序列化。虽然对人类读者不直观,但其在机器之间的数据传输效率上表现优秀。
二、性能与效率
-
JSON:在处理数字时,特别是DOUBLE类型,效率相对较低。对于字符串的编解码,由于需要进行字符集转换,也会有一定的性能损耗。
-
Protobuf:在处理数字和整数或浮点数数组的编解码时,效率远超JSON。它使用数字标签代替字符串格式的字段名进行内容分发,这也有助于提高效率。然而,在处理字符串或对象内都是字符串的情况下,效率提升可能并不明显。
三、数据大小和空间效率
-
JSON:数据表示相对冗长,特别是对于包含大量数字或复杂数据结构的数据,会占用更多的存储空间和网络带宽。
-
Protobuf:由于采用二进制格式,数据序列化后体积更小,更适合网络传输,可以节省带宽和存储空间。
四、跨平台与兼容性
-
JSON:被广泛支持,几乎所有的编程语言都有处理JSON的库,使得它在不同平台和系统之间的数据交换变得简单。
-
Protobuf:也支持跨平台和多种语言,但需要依赖Google提供的库或工具进行序列化和反序列化操作。
五、应用场景
-
JSON:更适合用于需要人类可读性和简单数据交换的场景,如Web服务、API接口、配置文件等。
-
Protobuf:更适合用于对性能和空间有要求、需要严格数据结构定义和更好扩展性的场景,如实时系统、游戏、高性能API等。
综上所述,JSON和Protobuf各有其优势和适用场景。JSON以其可读性和广泛支持在Web开发等领域占据重要地位;而Protobuf则以其高性能和数据压缩能力在需要快速数据传输和处理的领域表现出色。
Protobuf与JSON相比,其劣势可以归纳为以下几点:
- 可读性较差:Protobuf使用二进制格式进行编码,这导致其数据不如JSON格式的文本数据那么容易直接阅读和理解。对于需要人工查看或编辑数据的场景,JSON更为友好。
- 学习成本高:相对于JSON的简单直观,Protobuf的语法和使用方式需要一定的学习成本。开发人员需要熟悉Protobuf的语法规则、数据类型以及如何使用Protobuf编译器等工具。
- 不支持动态解析:Protobuf在编码和解码时需要预先定义数据结构,因此它不支持像JSON那样可以动态地解析任意结构的数据。这在处理一些需要灵活处理数据结构的场景时可能会受到限制。这项绝对导致,他不适合客户端 <---> 服务端之间的通讯,因为接口会经常更新,变化,不能动态适应,导致客户端也需要升级,是不现实的。
- 调试和查看困难:由于Protobuf使用二进制编码,数据无法直接查看和调试。开发人员可能需要使用特定的工具来解析和查看Protobuf数据的内容,这增加了调试的复杂性。
- 应用不够广泛:相比XML和JSON等更为常见的数据格式,Protobuf的应用范围相对较小。这可能导致在某些场景下,使用Protobuf可能会遇到兼容性和集成上的问题。
需要注意的是,虽然Protobuf在某些方面相对于JSON存在劣势,但它也有其独特的优势,如高效的编码和解码性能、跨平台和语言支持、良好的可扩展性等。因此,在选择数据格式时,应根据具体的应用场景和需求进行权衡。
本文来自博客园,作者:del88,转载请注明原文链接:https://www.cnblogs.com/del88/p/18143941

 浙公网安备 33010602011771号
浙公网安备 33010602011771号