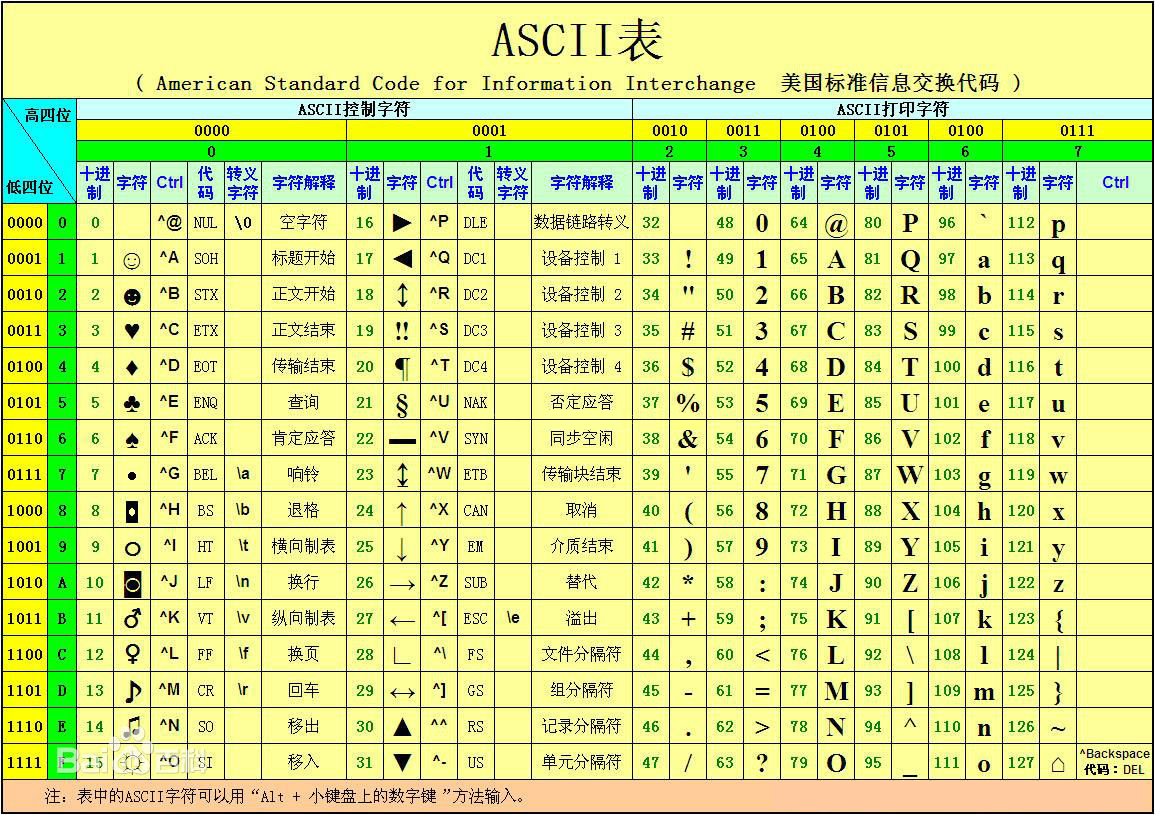
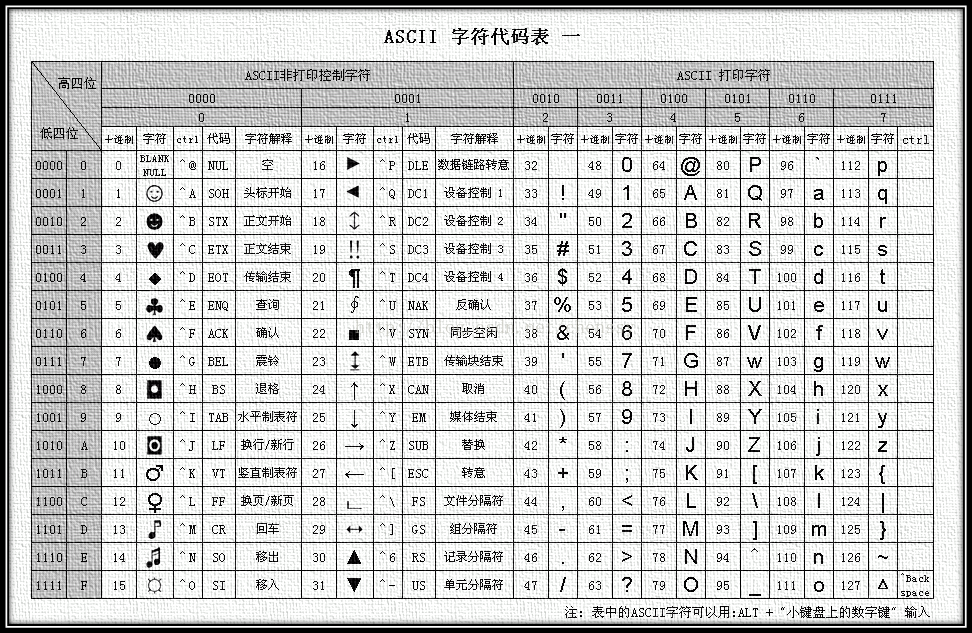
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是最初基于拉丁字母的一套电脑编码系统,它主要用于显示现代英语和其他西欧语言。它于1963年由美国标准化协会(ASA)制定,并在1967年成为美国国家标准(ANSI)。ASCII码表包括128个字符,使用7位二进制数来表示,其中0-31是控制字符,32-126是可打印字符(数字、字母、符号共95个),127是删除命令。
ASCII码表可以分为两部分:
-
标准ASCII码(0-127):
- 控制字符(0-31及127):这些是不可打印的字符,用于控制计算机或通信设备的操作。例如,字符7代表响铃(bell),字符10代表换行(line feed),字符13代表回车(carriage return),127是删除命令等。
- 可打印字符(32-126):这些字符包括空格、标点符号、数字(0-9)、大写字母(A-Z)和小写字母(a-z)。
-
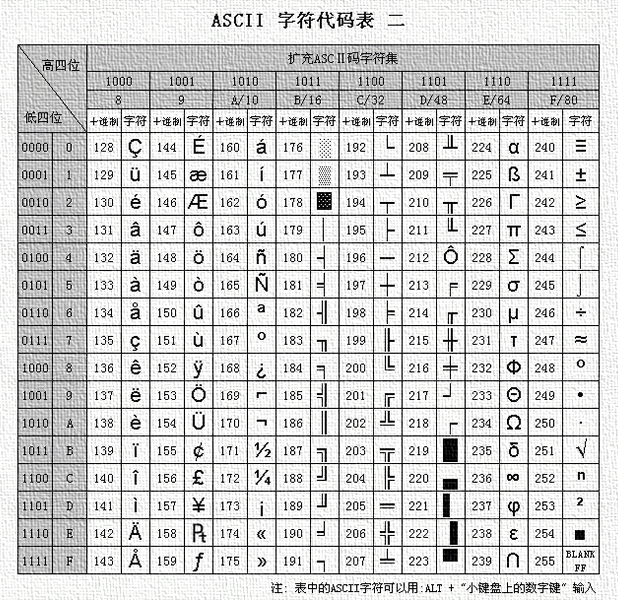
扩展ASCII码(128-255):
扩展ASCII码实际上不是ASCII标准的一部分,而是对原始ASCII标准的扩展。它通常被称为“扩展ASCII”或“高ASCII”。这部分字符集在不同的系统和地区有不同的定义,因此不是通用的。-
常见的扩展字符集包括ISO 8859-1(西欧字符集)、ISO 8859-2(东欧字符集)、Windows-1252(针对西欧语言的Windows字符集)等。这些字符集在ASCII码的基础上增加了额外的字符,以支持不同的语言和符号。
-
Unicode是一个更广泛使用的字符编码标准,旨在包含世界上所有语言的字符。Unicode的最初版本(UCS-2)使用16位来表示字符,而现在的版本(UTF-8、UTF-16等)支持更灵活的编码方式。UTF-8是一种特别流行的Unicode编码方式,因为它与ASCII码兼容(即ASCII字符在UTF-8编码中具有相同的字节表示)。
-
请注意,当提到“扩展ASCII码”时,人们可能指的是特定于某个系统或应用程序的8位字符集。这些字符集通常包括原始ASCII字符以及额外的128个字符,但这些额外字符的定义并不是标准化的。
由于扩展ASCII码没有统一的标准定义,因此不同的系统和应用程序可能会使用不同的字符集。这可能导致在不同系统之间交换文本时出现乱码问题。为了避免这种问题,最好使用更通用的字符编码标准,如UTF-8编码的Unicode。
本文来自博客园,作者:del88,转载请注明原文链接:https://www.cnblogs.com/del88/p/18050310

 浙公网安备 33010602011771号
浙公网安备 33010602011771号