

本节是关于MySQL的复合索引相关的知识,两个或更多个列上的索引被称作复合索引,本文主要介绍了mysql 联合索引生效的条件及失效的条件
对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c)。 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找;
复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。所以说创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
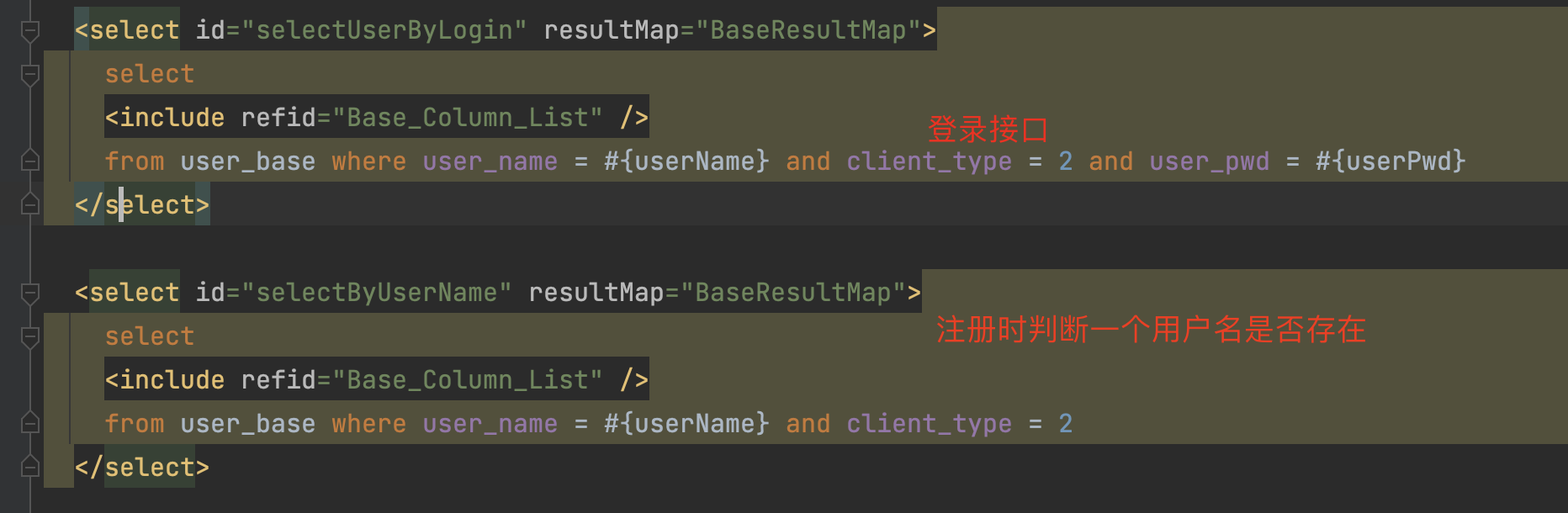
可见 登录和注册时判断一个用户名是否存在都使用了 user_name + client_type 这2列,且要求用户名 + 终端类型 必须唯一,若只单独给这2列加一个唯一索引,则登录时 又查询了 user_pwd 所以,最好这3列一并组成一个唯一索引,才能发挥最佳效率,以下我们测试一下:
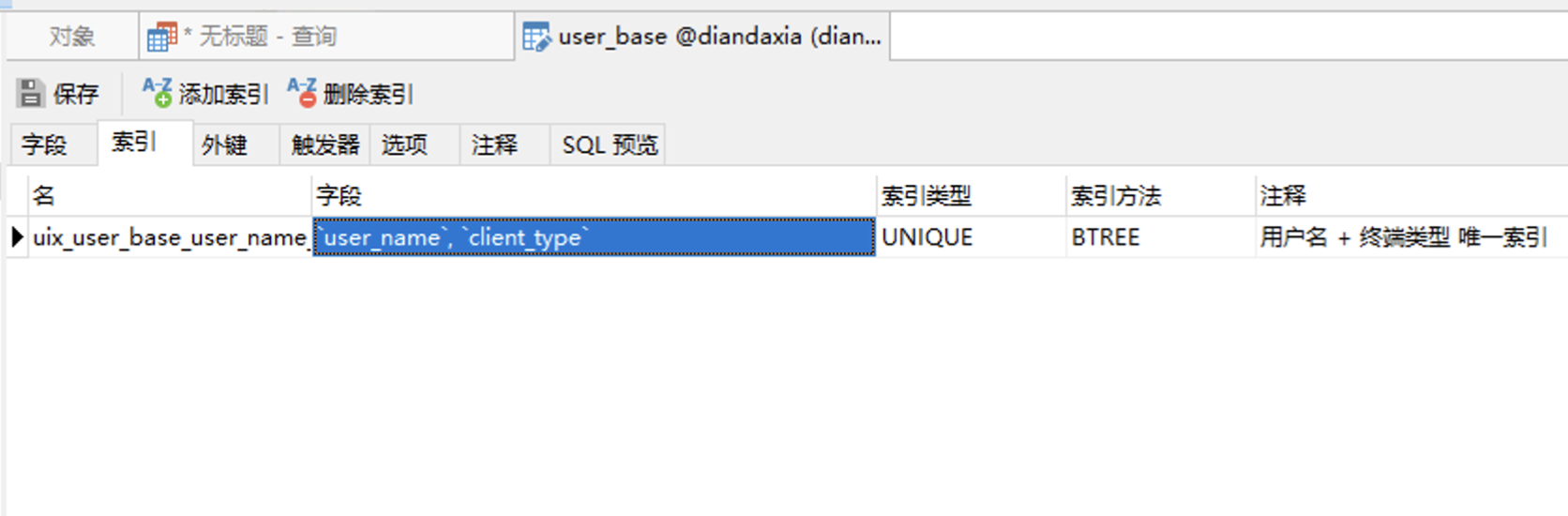
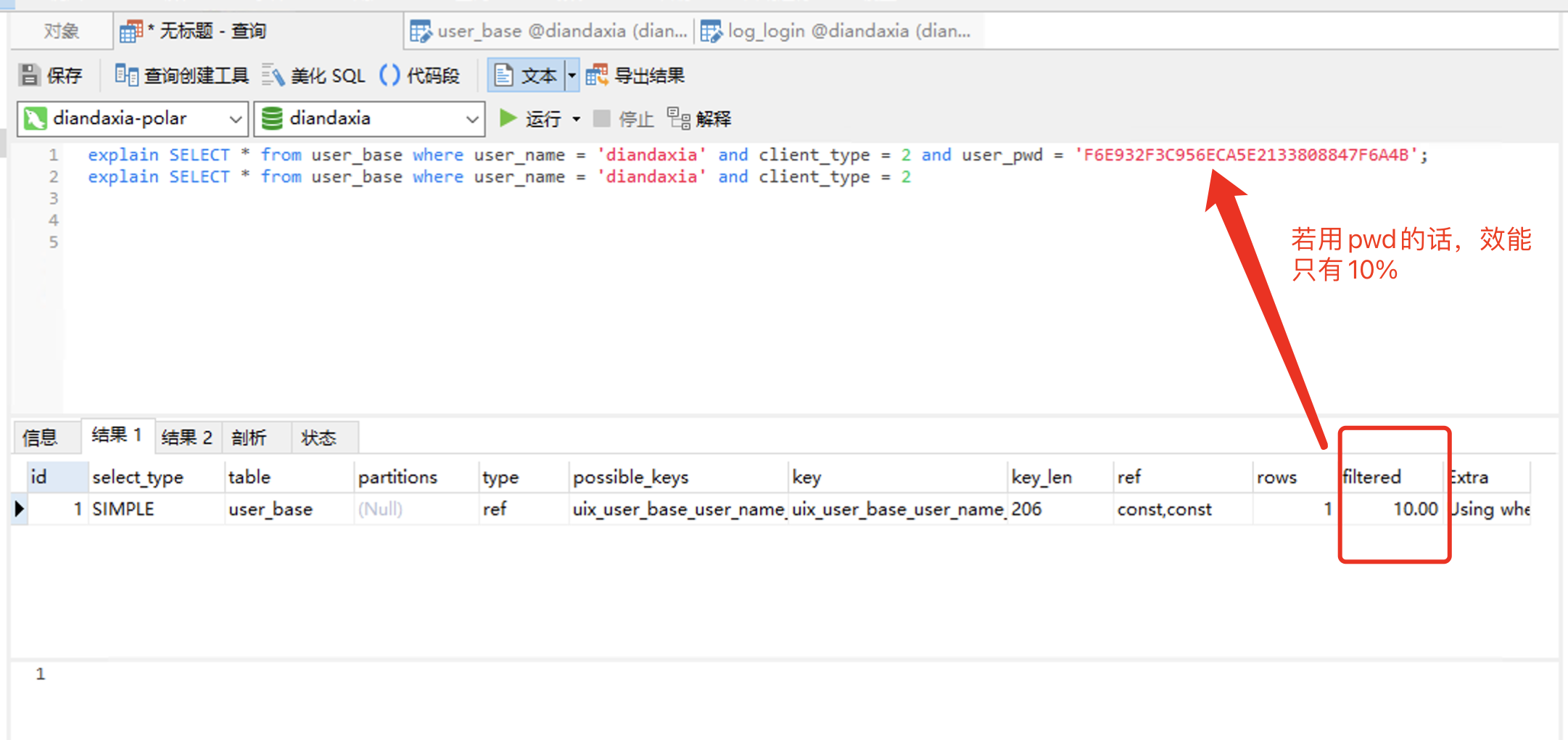
1. 首先只user_name + client_type 组成唯一索引,若登录的话看下查询效能:
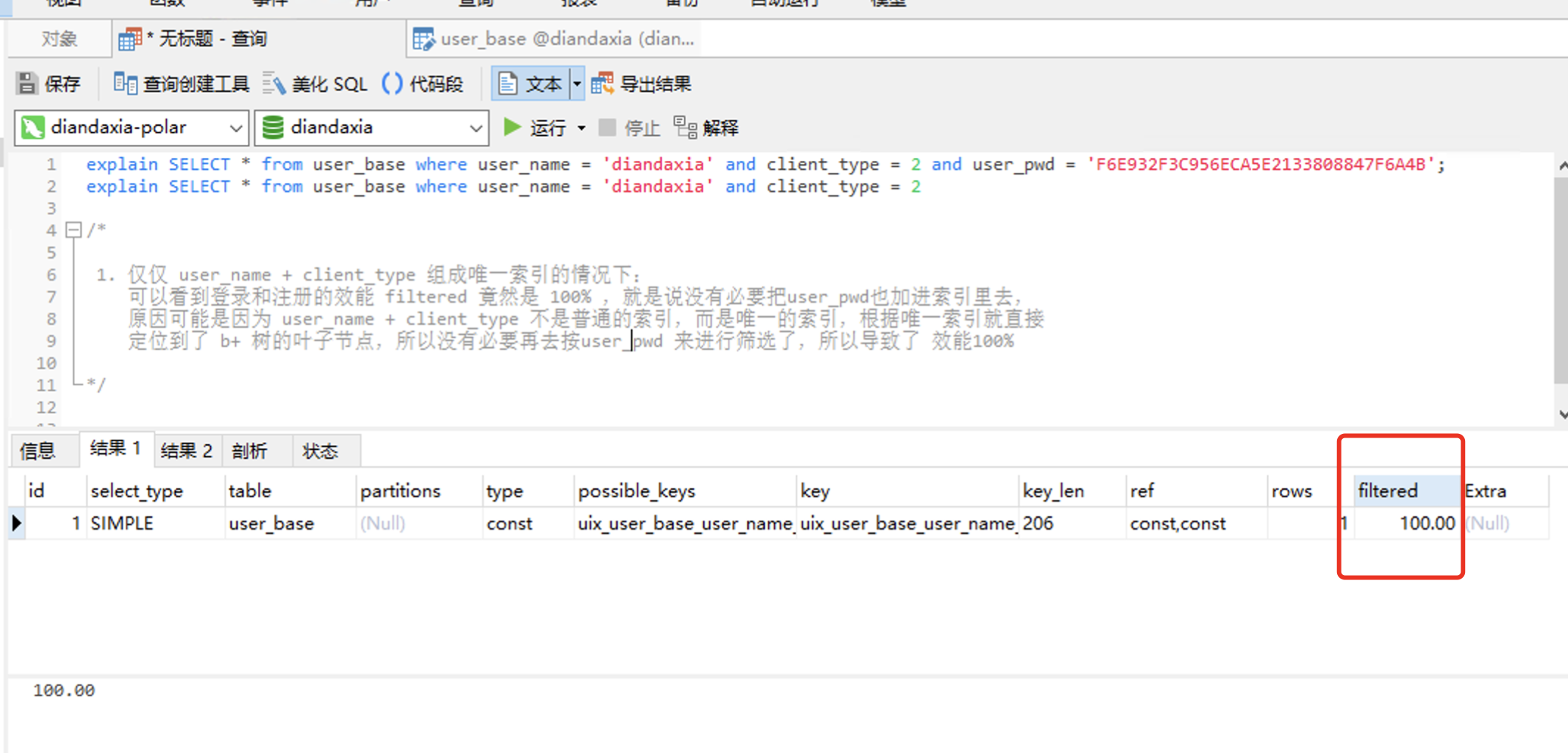
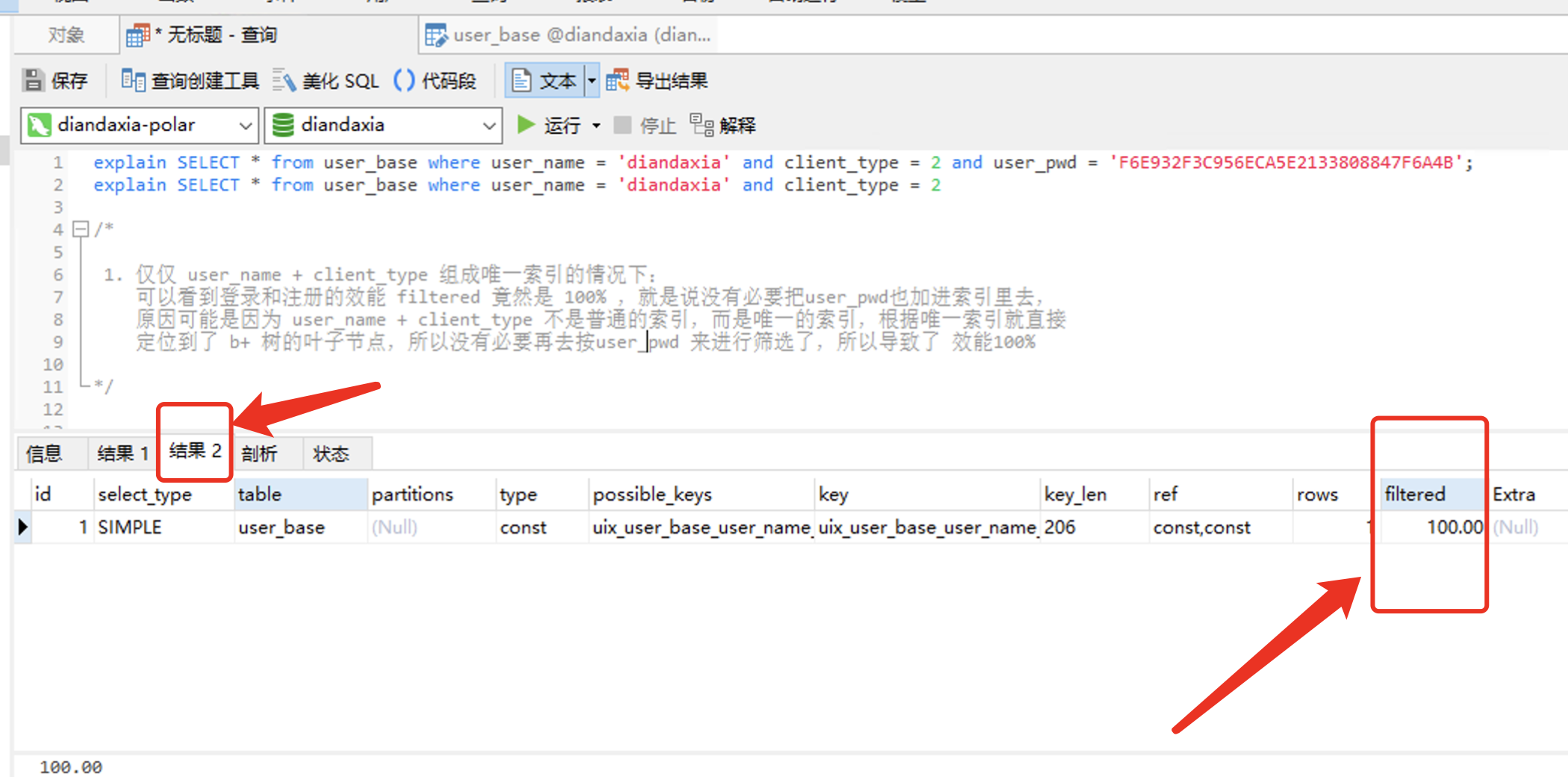
explain SELECT * from user_base where user_name = 'diandaxia' and client_type = 2 and user_pwd = 'F6E932F3C956ECA5E2133808847F6A4B'; explain SELECT * from user_base where user_name = 'diandaxia' and client_type = 2 /* 1. 仅仅 user_name + client_type 组成唯一索引的情况下: 可以看到登录和注册的效能 filtered 竟然是 100% ,就是说没有必要把user_pwd也加进索引里去, 原因可能是因为 user_name + client_type 不是普通的索引,而是唯一的索引,根据唯一索引就直接 定位到了 b+ 树的叶子节点,所以没有必要再去按user_pwd 来进行筛选了,所以导致了 效能100% */
2. 根据上面的分析,接下来这样搞下,把user_name + client_type 搞成 非 唯一索引。再来测试一下效能:
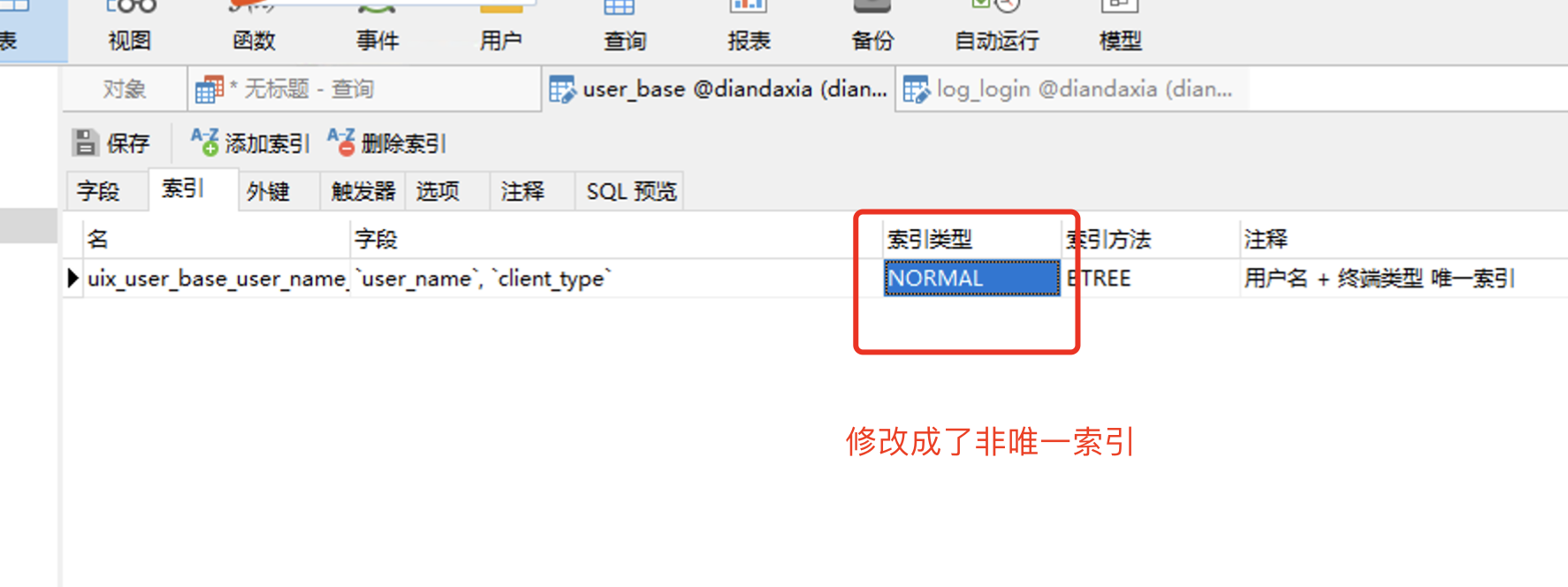
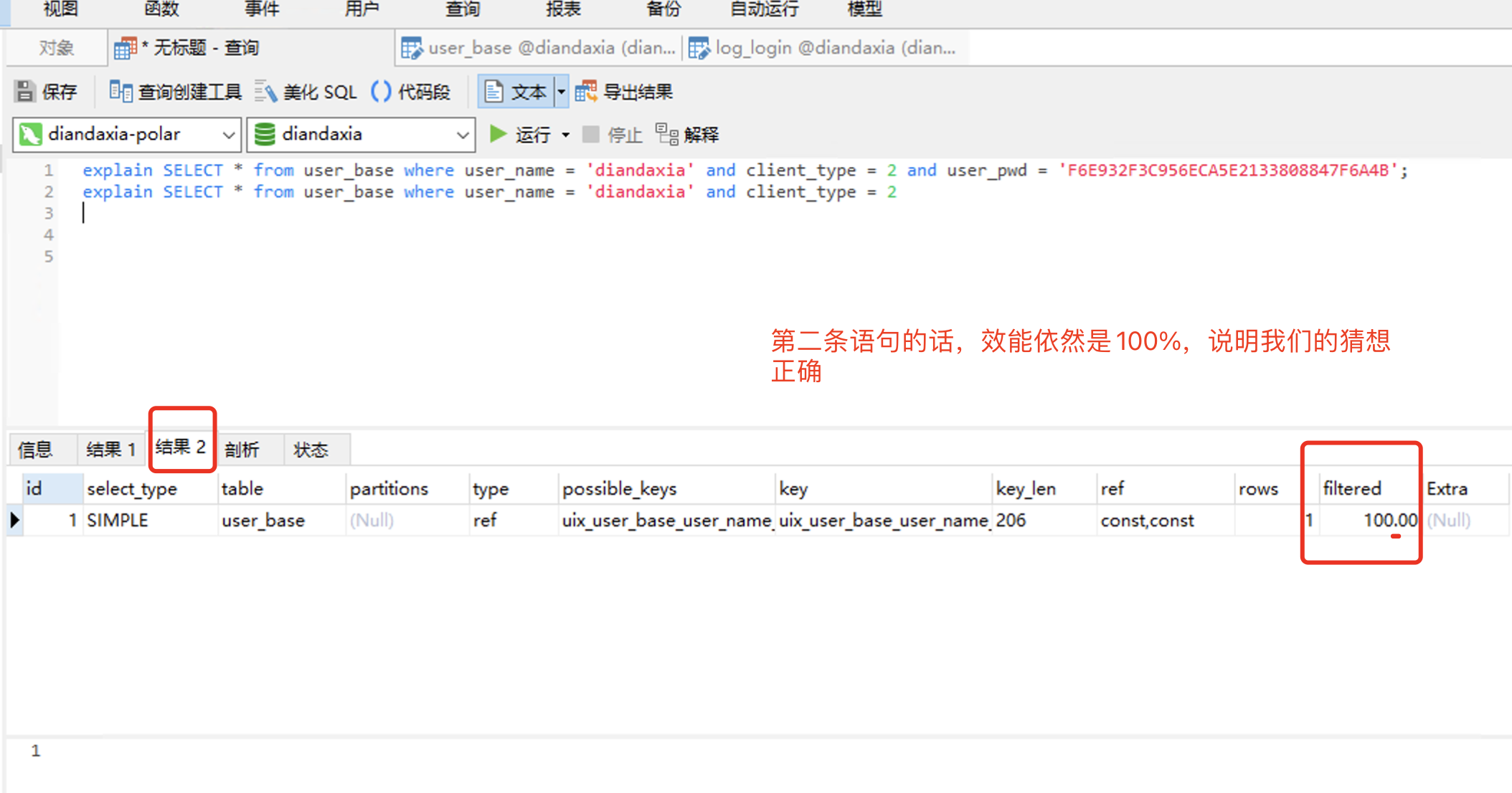
所以,user_base 表中,只需要 user_name + client_type 组成唯一索引就行了,没有必要把 user_pwd 也加进索引中,浪费索引空间。这点对我以后用户表的开发设计,非常重要的思想,即只要是用户表 通常就是
1. 若没有client_type项的话,user_id 主键 、user_name 唯一索引;
2. 若有 client_type 字段的话,则是 user_id 主键、user_name + client_type 唯一索引就可 保证登录 + 注册时判断用户是否存在 最优化。
好了,接下来 开始优化一下 log_login 表的索引,因为这个表也是常用的表;
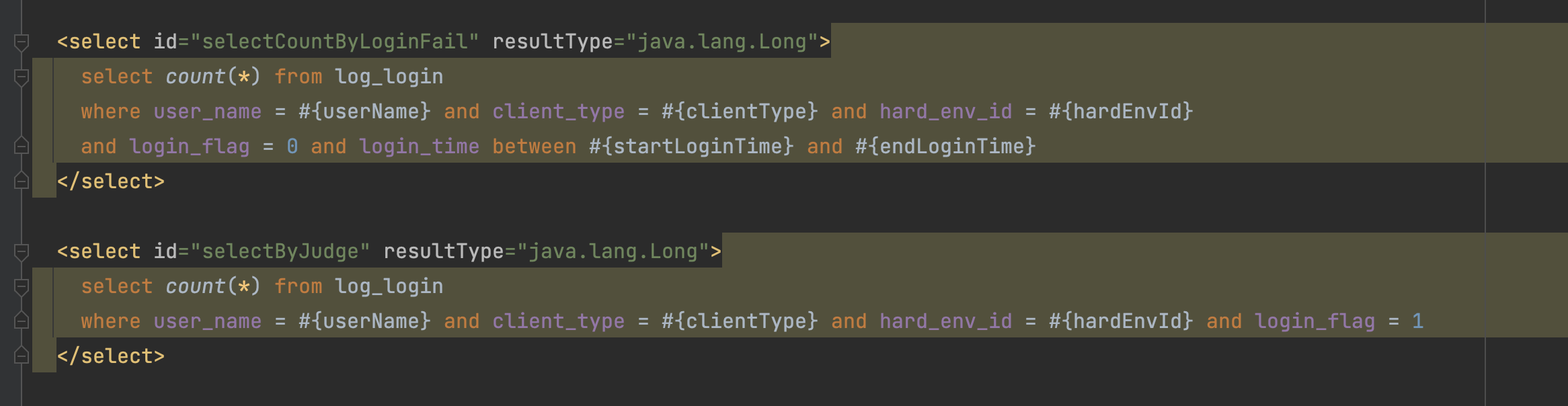
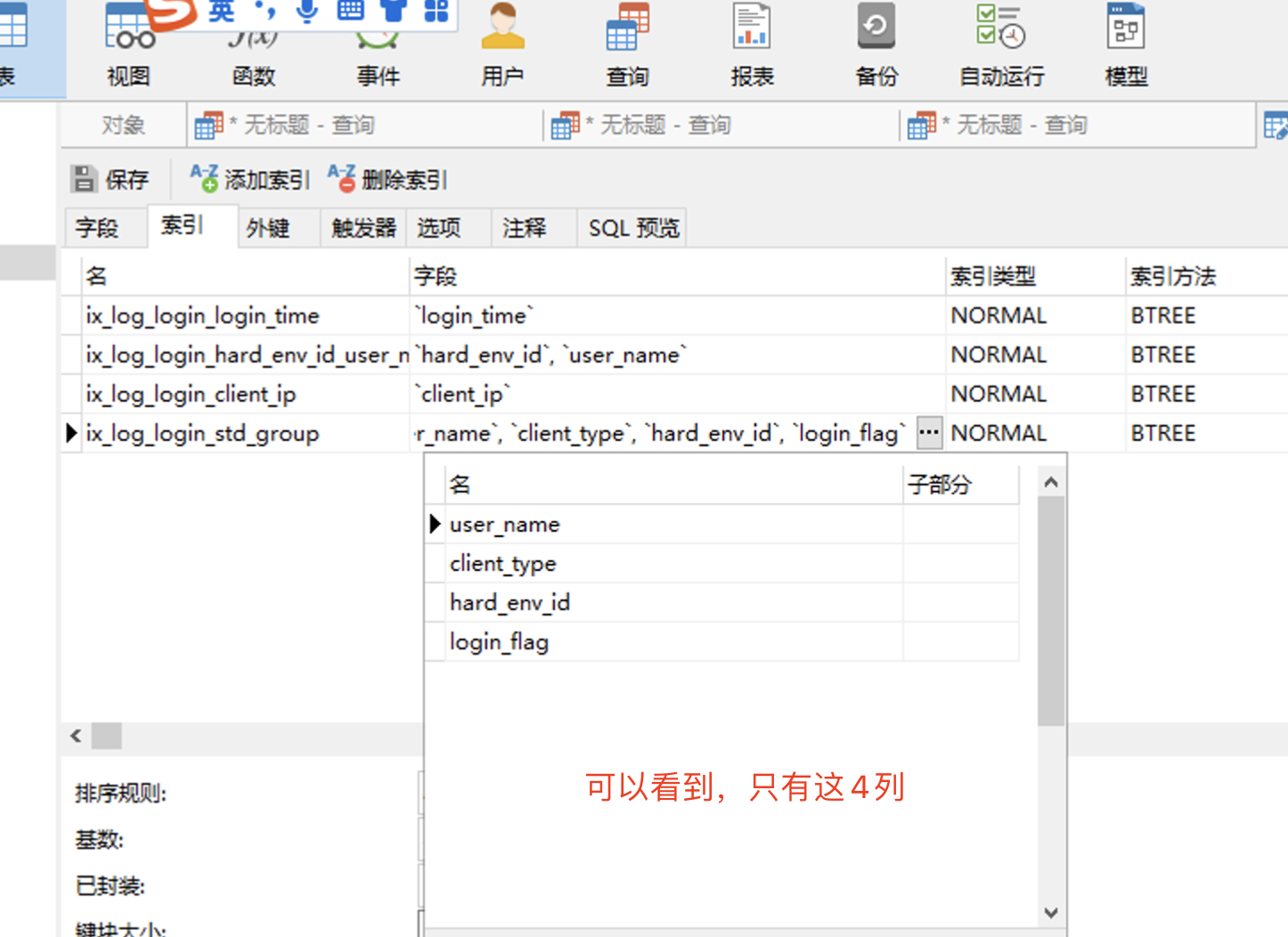
可以看到,这2个查询 都用到了 user_name + client_type + hard_env_id + login_flag 所以 这 4列 应该是可以确定的需要组成一个索引,没有必要是唯一索引,因为业务上 这个不唯一。
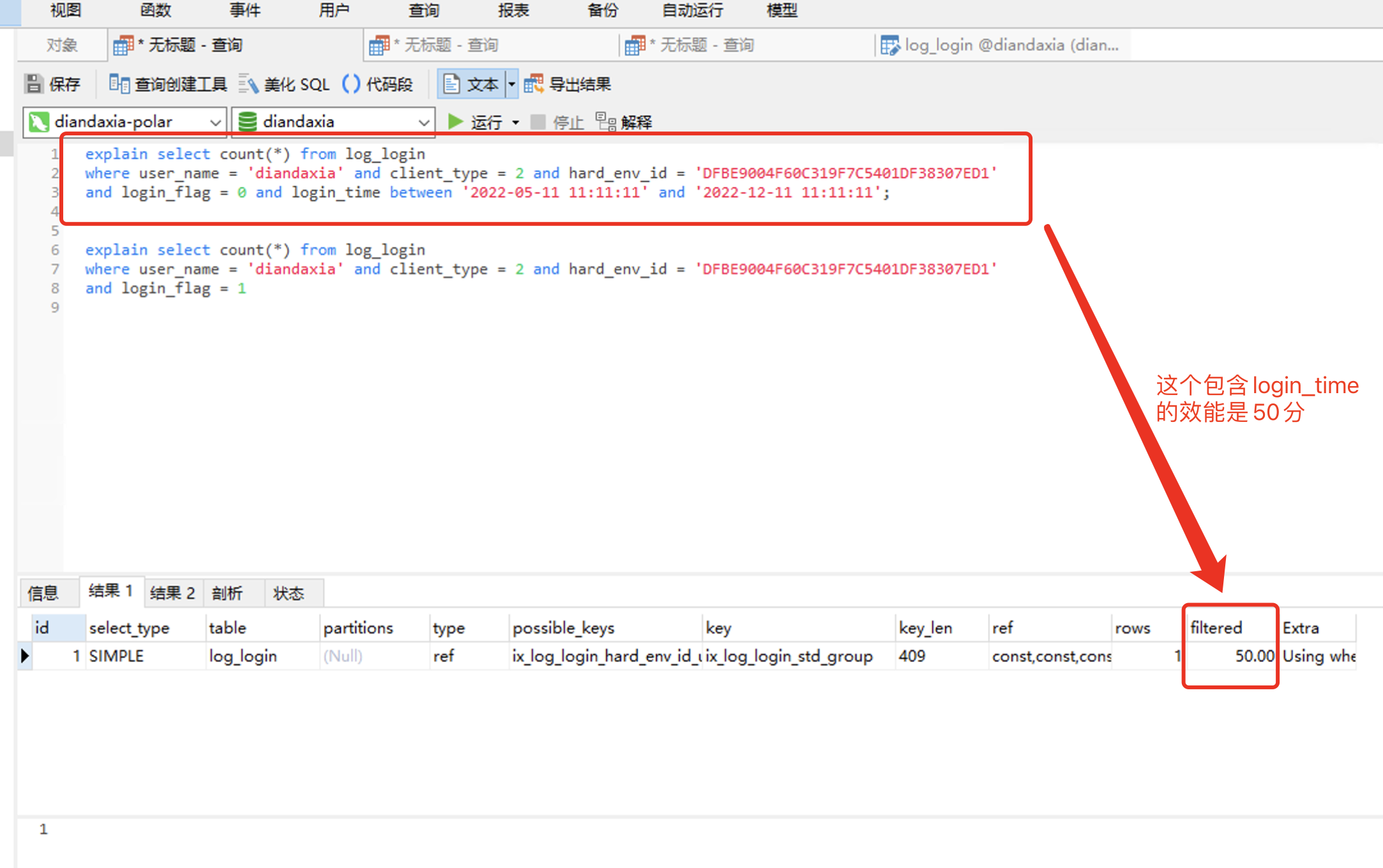
那么 login_time 呢,这个需要也加索引吗,接下来就用 explain 来测试 对比下 效能
1. 仅那4列 有索引
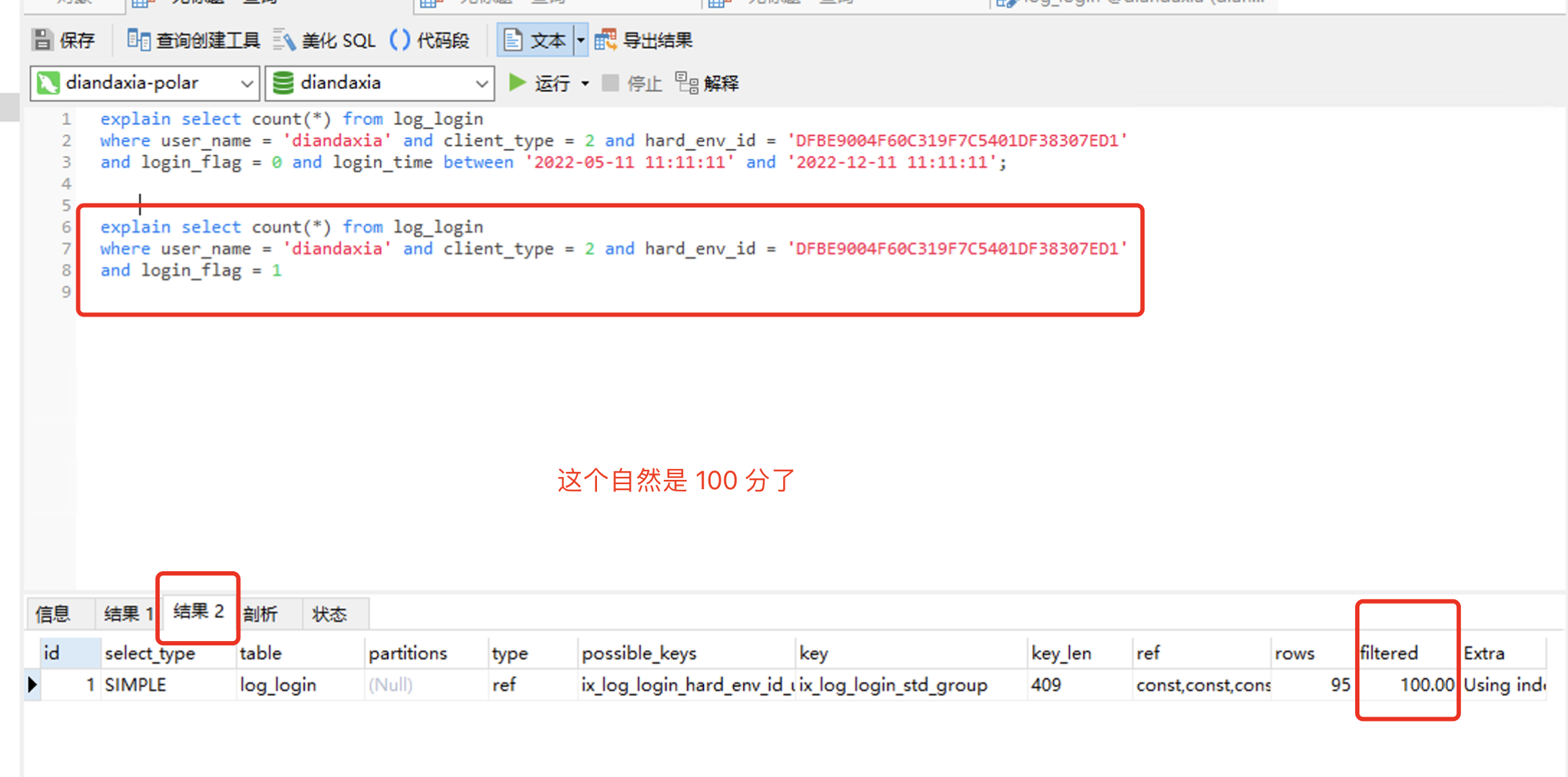
2. 接下来就是给把login_time 也加进组合索引中去:
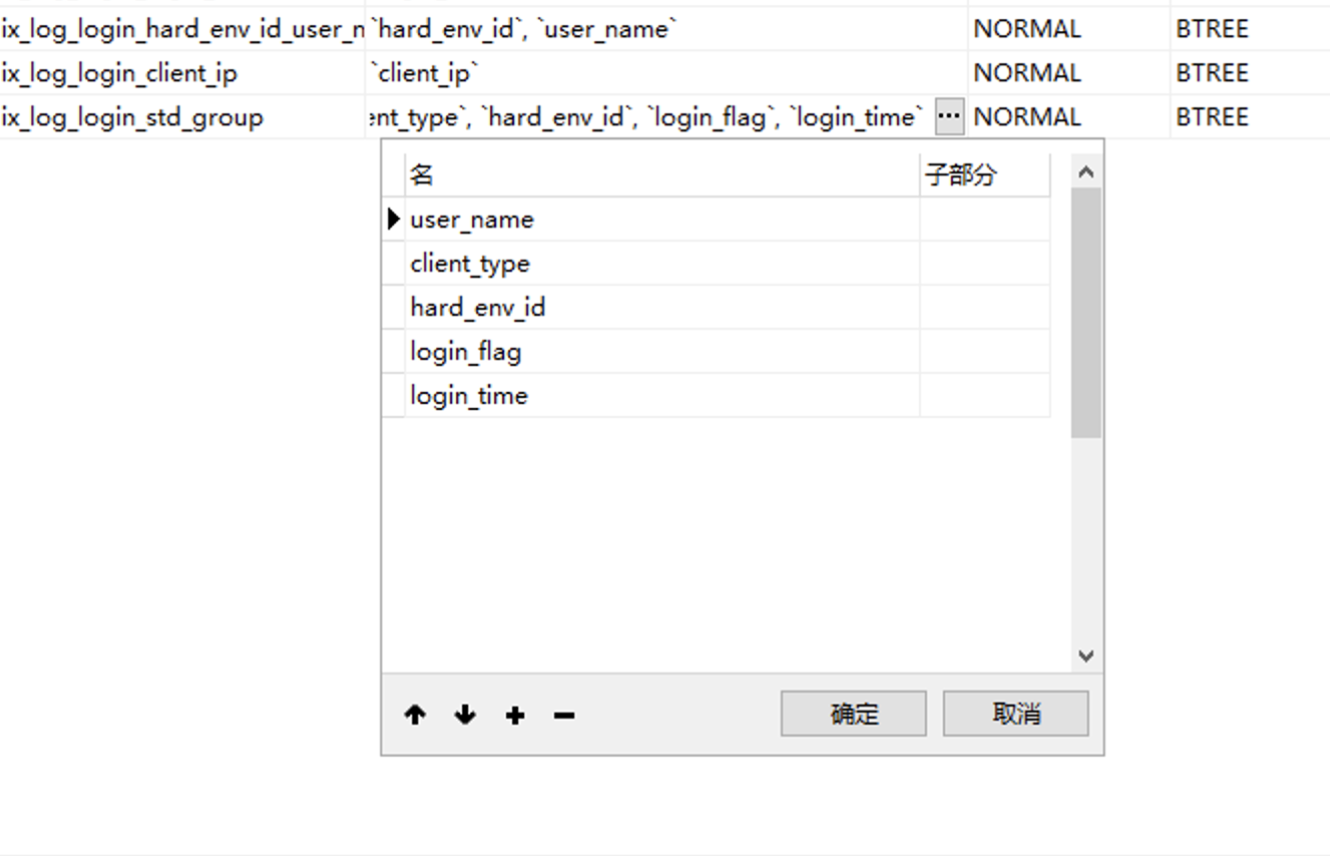
explain select count(*) from log_login where user_name = 'diandaxia' and client_type = 2 and hard_env_id = 'DFBE9004F60C319F7C5401DF38307ED1' and login_flag = 0 and login_time between '2022-05-11 11:11:11' and '2022-12-11 11:11:11'; explain select count(*) from log_login where user_name = 'diandaxia' and client_type = 2 and hard_env_id = 'DFBE9004F60C319F7C5401DF38307ED1' and login_flag = 1
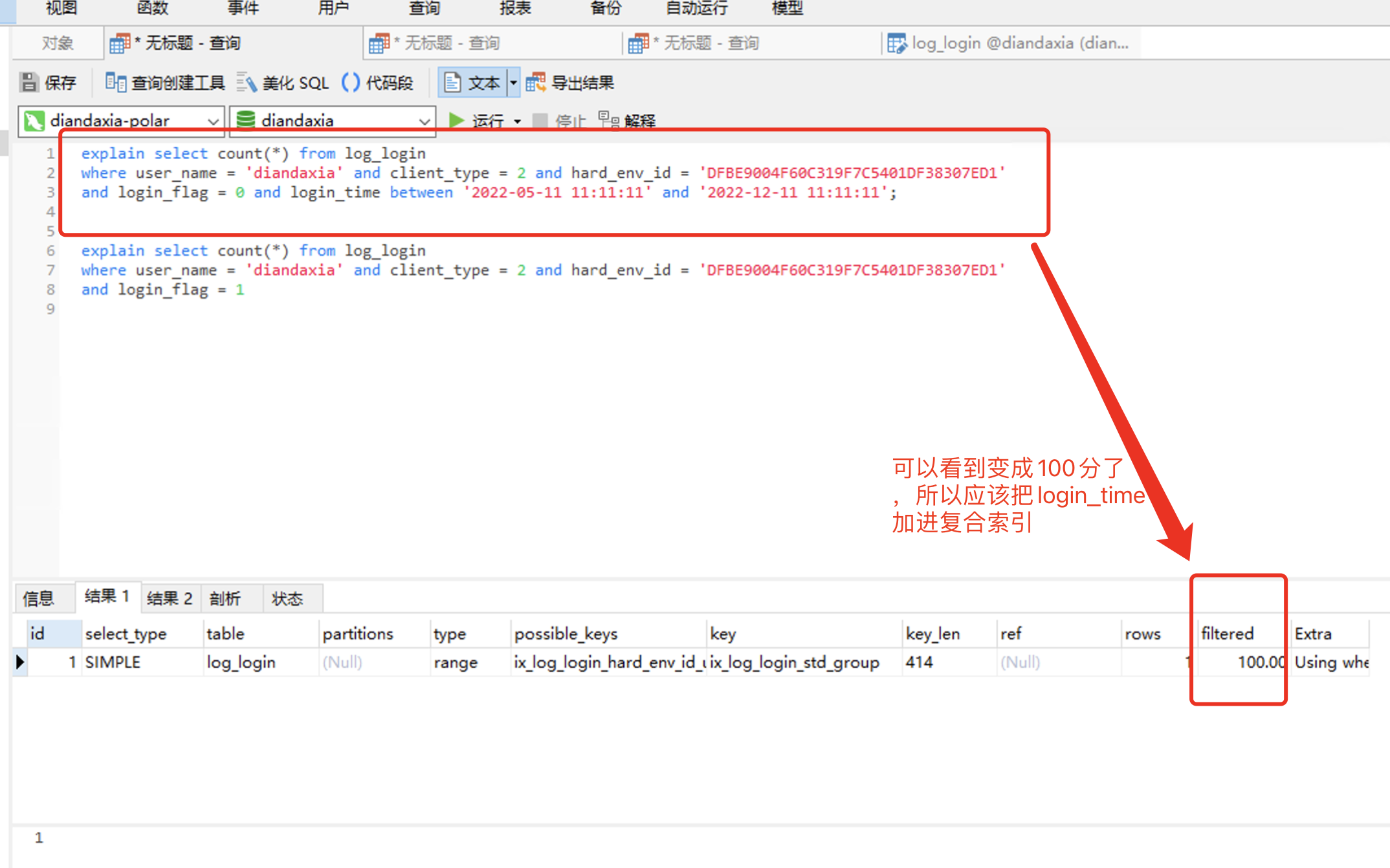
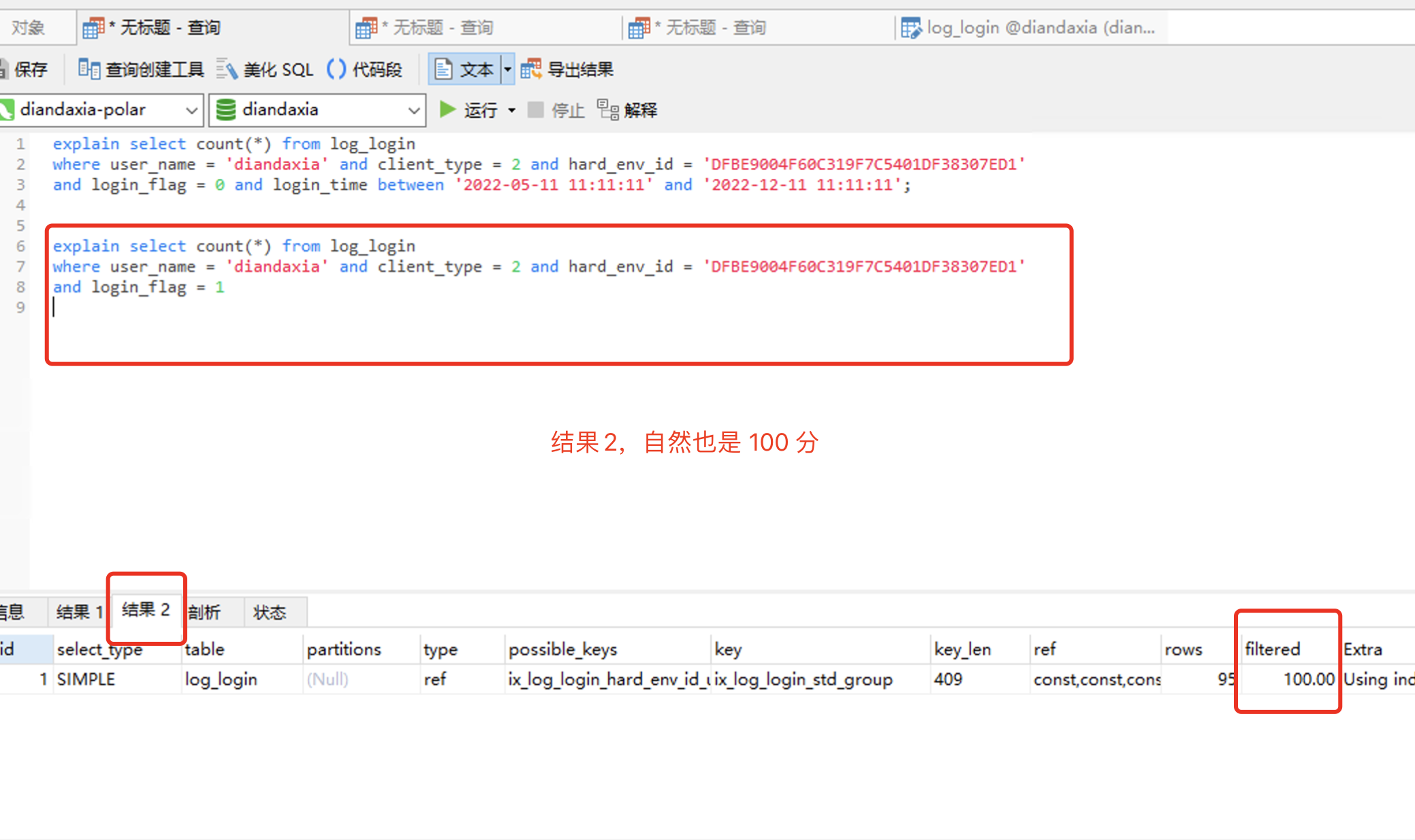
====================================================================
这里我又有个疑问,就是 联合索引里,若有范围查询的怎么办,比如上面的这个login_time ,这个需要 大于 或 小于 这种的 范围查询

接下来我们测试一下,把login_time 放到 中间,看看,是否会向他说的那样,后阻碍后面的索引;
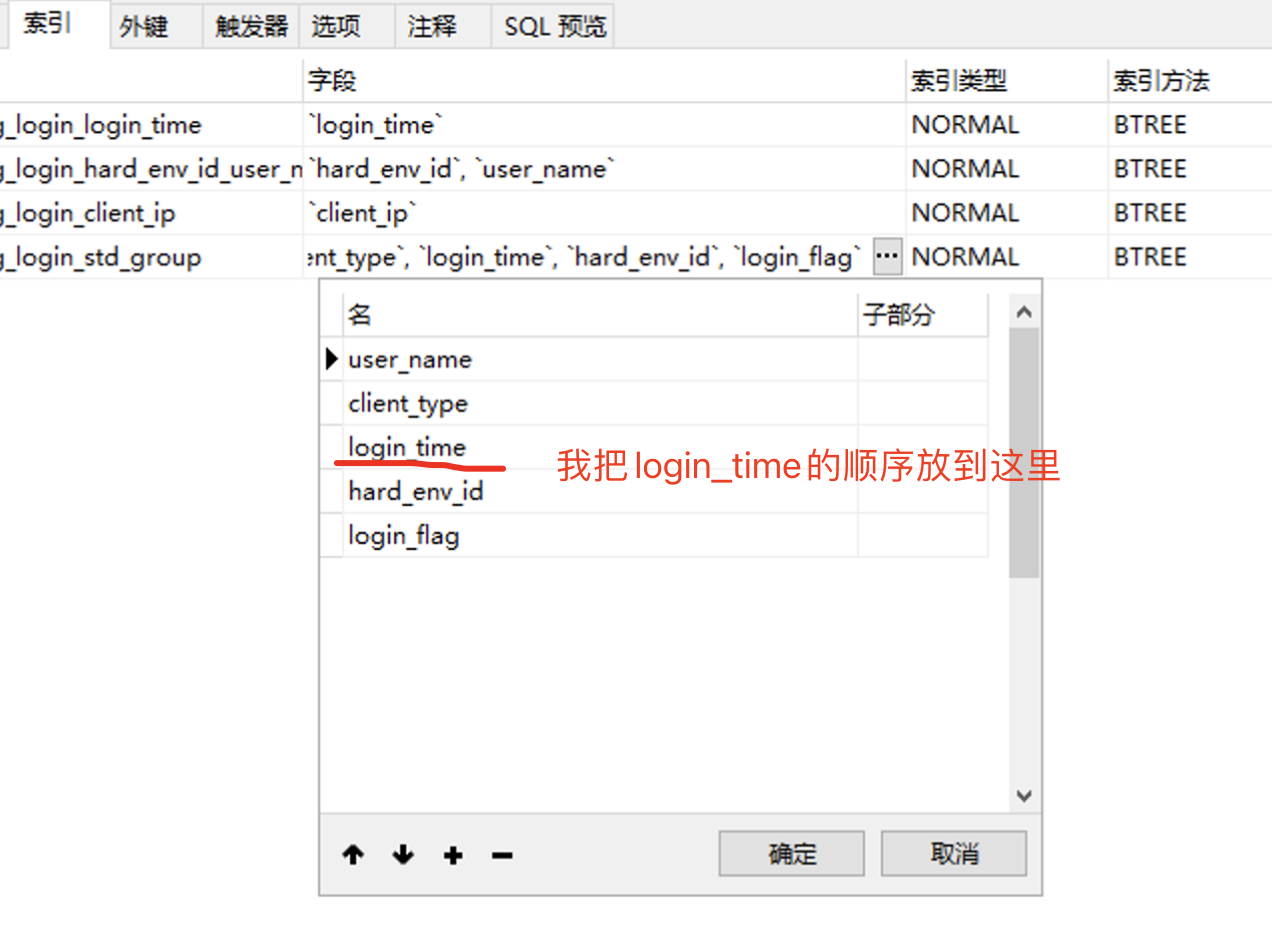
然后sql语句修改下:
explain select count(*) from log_login where user_name = 'diandaxia' and client_type = 2 and login_time between '2022-05-11 11:11:11' and '2022-12-11 11:11:11' and hard_env_id = 'DFBE9004F60C319F7C5401DF38307ED1' and login_flag = 0;
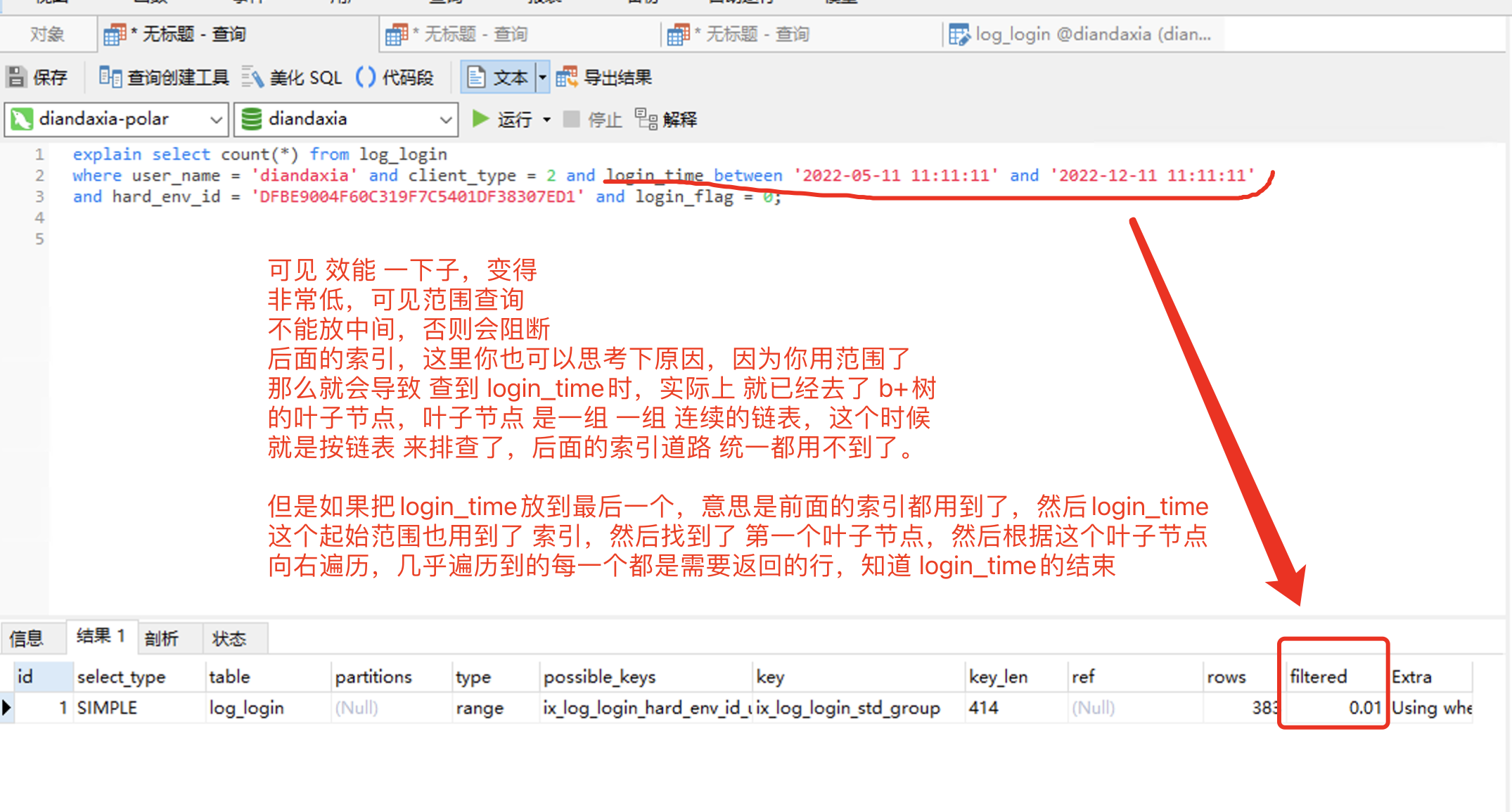
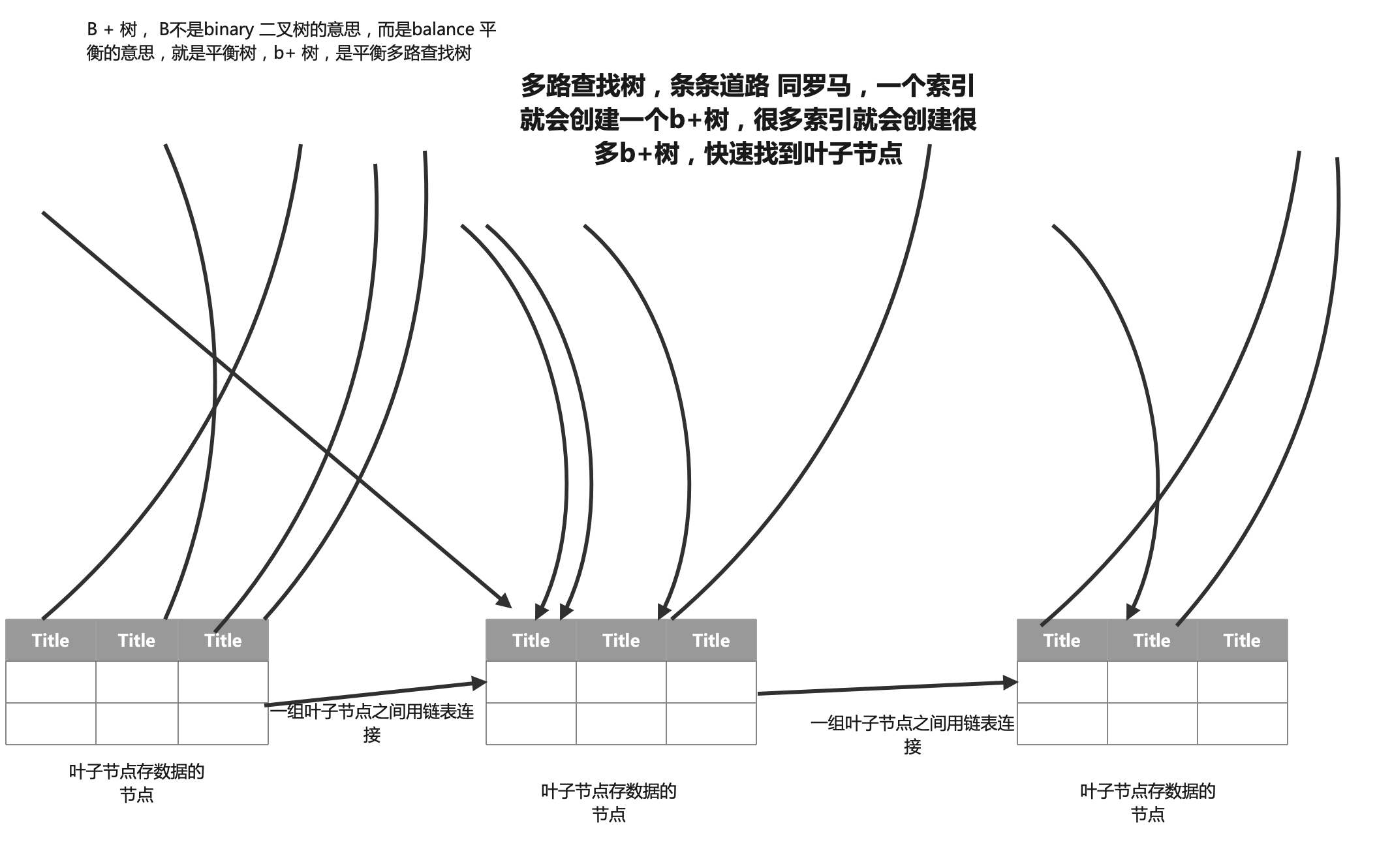
最后 B+ 树的原理:
本文来自博客园,作者:del88,转载请注明原文链接:https://www.cnblogs.com/del88/p/16886339.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号