
Mysql DQL
基本格式
select [表字段名称|列名]|[*] from 数据表的名称 [where] [查询的条件] [and] [条件1] [group by 分组条件] [having 过滤] [order by 排序] [LIMIT offset ,num 分页]
常见语法和函数使用
模板表
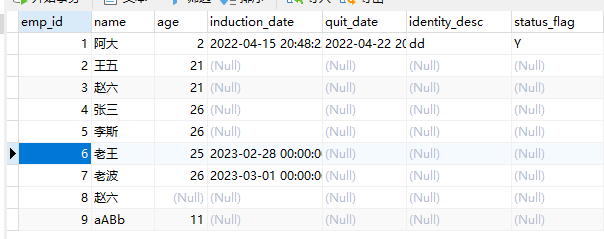
常用语法操作
select * 查所有字段
查询emp所有的数据信息 SELECT * FROM EMP 默认按行显示,加上\G 就是按列显示
指定查询某个字段
指定查询emp表中的某个字段 SELECT ename,job,sal FROM EMP
取别名
取别名称 SELECT ename 员工名称,job as 职位,sal empSal FROM EMP
利用select进行计算
注意: SELECT 1+1 在mysql中是可以进行执行的,但是在Orcale中不能进行执行的(了解:SELECT 1+1 FROM dual
DISTINCT去重
对一个或者多个字段进行去重
只能放在所有字段最前面
只能在select 语句中使用
如果后面有多个字段,会进行组合去重,也就是多个字段组合起来比较是否一样
只能返回目标字段而不能返回其它字段
去重 DISTINCT SELECT DISTINCT job from EMP
一般用来查询不重复条数
SELECT COUNT(DISTINCT name,age) FROM student;
like模糊查询
查询员工名字中有A的员工信息 select * from EMP where ename like '%A%' 查询员工名字中第二个字母为A的员工信息 select * from EMP where ename like '_A%' 查询员工名字中第三个字母为A的员工信息 select * from EMP where ename like '__A%' 注意的: 如like查询的条件中带有%标识0个或者多个 _:一个下划线表一个字符
大小写问题
mysql默认字符集不区分大小写,所以使用like时默认不区分大小写
此时,如果要区分大小写,可以加上binary
SELECT `name` FROM `emploee` WHERE `name` LIKE BINARY '%aA%'
在部署时一般使用大小写敏感的字符集规则如utf8mb4_bin
此时,如果要实现忽略大小写模糊查询
方式一:通过在sql查询时指定字符规则集不区分大小写
select * from test1 where b like "A%" COLLATE utf8mb4_0900_ai_ci;
方式二:使用upper()、lower()函数,将整列与查询条件同时转换为大写或者小写 推荐
select * from test1 where upper(b) like upper('A%');
mysql8.0可以创建函数索引
alter table test1 add index idx_b ( (upper(b)));
in(set)集合查询
set不超过100个
查询工资是1600,800,1250 select * from EMP where sal IN(1600,800,1250)
between and 区间范围
闭区间
查询工资在2450到3000之间(包含2450/3000) select * from EMP where sal between 2450 and 3000
is not null 不为空
select * from EMP where comm is not null
is null 判空
SELECT age from emploee WHERE age is null
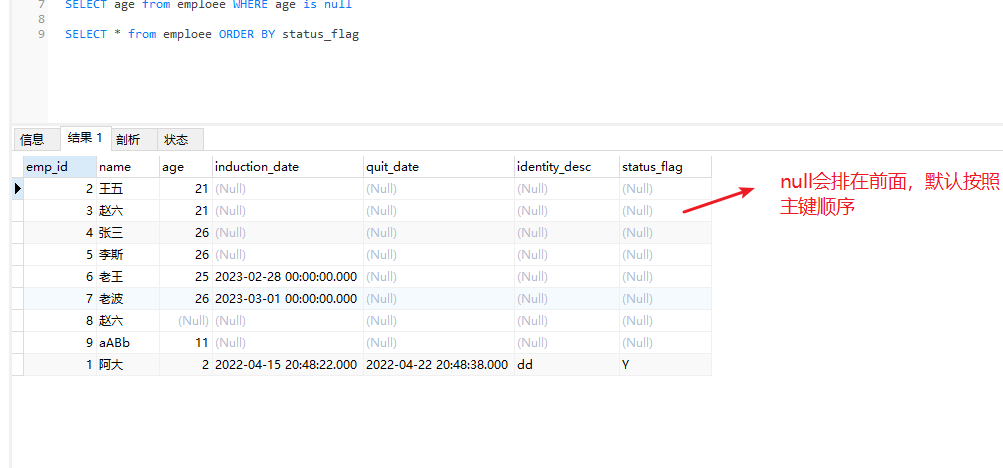
order by 排序
语法
select [表字段名称|列名]|[*] from 数据表的名称 [where] [查询的条件] [and] [条件1] [order by 列名1 ASC|DESC ,列名2 ASC|DESC .... ]
默认使用升序的方式进行排序 ASC (可以不写)
降序 DESC
有索引时,排序字段顺序与索引字段顺序一致
查询员工的薪资从低到高的进行排序 SELECT * FROM EMP ORDER BY sal asc 查询员工的薪资从高到低的进行排序 SELECT * FROM EMP ORDER BY sal desc 查询员工奖金以降序的方式进行排序(注意奖金有空值的) SELECT * FROM EMP ORDER BY comm desc 查询部门编号和工资,部门编号升序排序,工资安装降序排序 SELECT * FROM EMP ORDER BY deptno,sal desc 查询部门编号和奖金,部门编号降序排序,奖金降序排序 SELECT * FROM EMP ORDER BY comm desc,deptno desc
null的会排在最前面
group by分组
select [表字段名称|列名]|[*] from 数据表的名称 [where] [查询的条件] [and] [条件1] [group by 分组条件] [having 过滤]
统计所有的部门的平均工资 SELECT DEPTNO,ROUND(AVG(sal)) FROM EMP GROUP BY DEPTNO #group by后面可以跟多个条件,按顺序分组
having 过滤
滤出来的是要的数据
having not 是过滤掉
select [表字段名称|列名]|[*] from 数据表的名称 [where] [查询的条件] [and] [条件1] [group by 分组条件] [having 过滤]
分析: 1、分组统计所有部门的平均工资 SELECT DEPTNO,ROUND(AVG(sal)) FROM EMP GROUP BY DEPTNO 2、找出工资大于2500的部门 SELECT DEPTNO,ROUND(AVG(sal)) avg FROM EMP GROUP BY DEPTNO HAVING ROUND(AVG(sal))>2500 3、工资小于1500 SELECT sal FROM emp HAVING sal<1500; 扩展:Oracle中 HAVING不带上别名
lilmit 分页
select 表字段1,表字段2,... from 表名 limit 初始偏移量,查询行数; 第2-8条记录:select 表字段1,表字段2,... from 表名 limit 1,7;
函数
数字处理函数
max() 最大值
如:计算工资最大数据 :SELECT MAX(sal) FROM EMP
min()最小值
如:计算工资最小数据 :SELECT min(sal) FROM EMP
sum()求和
如:计算员工的总工资 :SELECT sum(sal) FROM EMP
avg()计算平均值
SELECT SUM(comm)/COUNT(*) FROM EMP
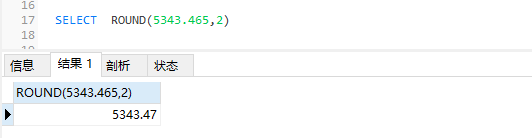
round四舍五入
ROUND(参数1,参数2)
参数1源数据,参数2[可写可不写]
如写了就从参数2(小数点开始计算)开始四舍五入,
如不写就从小数点之后开始四舍五入
参数2:
0标识从小数点
整数(1,2,3...)表示小数点之后的..
负数(-1,-2,-3。。。。)表示小数点之前的开始
日期函数
now()当前时间的年月日时分秒

curdate()年月日

curtime()时分秒

字符串函数
concat()拼接字符串
ONCAT() 函数用于将多个字符串连接成一个字符串 返回结果: • 返回结果为连接参数产生的字符串。 • 如有任何一个参数为NULL ,则返回值为 NULL。
SELECT CONCAT('姓名:',ename) eanme from EMP
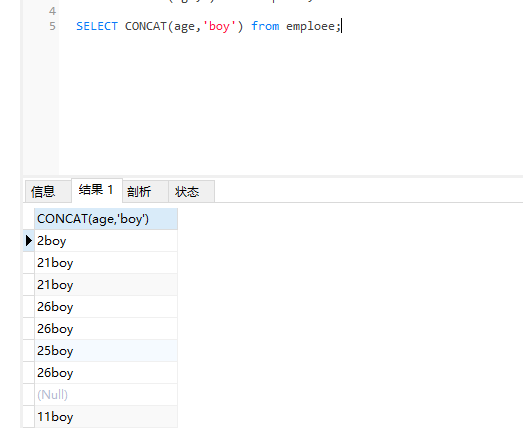
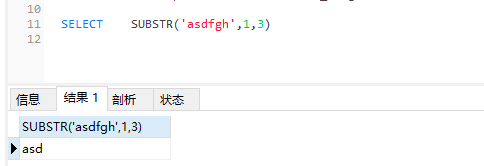
substr(str,start,end)字符串截取
index从1开始
参数1就是数据源 ,参数2起始索引,参数3就截取的长度 SELECT SUBSTR('asdfgh',1,3)
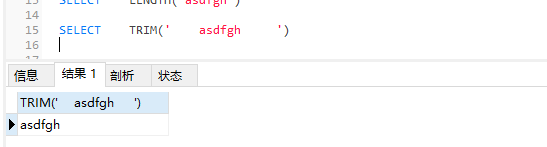
length(str)获取长度

trim(str)去除左右空格
时间函数
TIMESTAMPDIFF(时间单位,参数1,参数2) 时间差
可以设置参数,可以精确到天(DAY),小时(HOUR),分钟(MINUTE),秒(SECOND),毫秒(FRAC_SECOND(低版本不支持,可以用秒,再乘1000))
计算机制为参数2-参数1,最后结果为数字,单位为第一个参数设置的值 (week 周,month 月,quarter 季度,year 年 )
差一天
select TIMESTAMPDIFF(DAY,'2018-03-20', '2018-03-21'); select TIMESTAMPDIFF(DAY,'2018-03-20 00:00:00', '2018-03-21 00:00:00'); 差49小时
select TIMESTAMPDIFF(HOUR, '2018-03-20 09:00:00', '2018-03-22 10:00:00'); 差2940分钟
select TIMESTAMPDIFF(MINUTE, '2018-03-20 09:00:00', '2018-03-22 10:00:00'); 差176400秒
select TIMESTAMPDIFF(SECOND, '2018-03-20 09:00:00', '2018-03-22 10:00:00');
查询员工入职天数
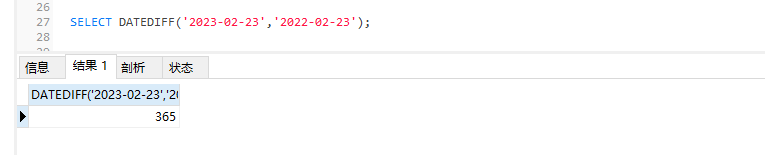
SELECT DATEDIFF(NOW(),hiredate) FROM EMP
DATEDIFF(参数1,参数2) 返回值为相差的天数
int类型,不能定位到时分秒,因为固定天数为单位,所以比上面的少一个可设置的参数,且计算机制为参数1-参数2,与上面的计算机制相反,如果搞错了会计算出负数,mysql也算是给埋了个坑
条件函数
case when 条件语句
写法1: 适用于按值匹配场景
CASE <表达式> WHEN <值1> THEN <操作> WHEN <值2> THEN <操作> ... ELSE <操作> END as 别名
写法2: 适用于按条件匹配场景
CASE WHEN <条件1> THEN <命令> WHEN <条件2> THEN <命令> ... ELSE commands END AS 别名
eg:
SELECT CASE WHEN age > 10 THEN age WHEN age = 2 THEN 0 ELSE age END as age FROM `emploee`

SELECT CASE age WHEN 2 THEN 10086 ELSE age END as age FROM `emploee`

IF(expr1,expr2,expr3)

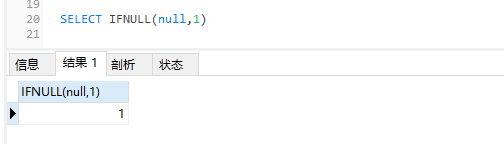
IFNULL(expr1,expr2)
其他
count()计数
如:计算员工人数 : SELECT COUNT(*) FROM EMP
多表查询
笛卡尔乘积
多变连接查询的原理
就是把两张表组合查询,左表每一条数据按条件连接另一张表的符合条件的数据 条数为两两相乘
如:SELECT * FROM EMP e,DEPT d WHERE e.deptno=d.deptno
select * from 表名1,表名2
#不加条件就全量数据相乘了
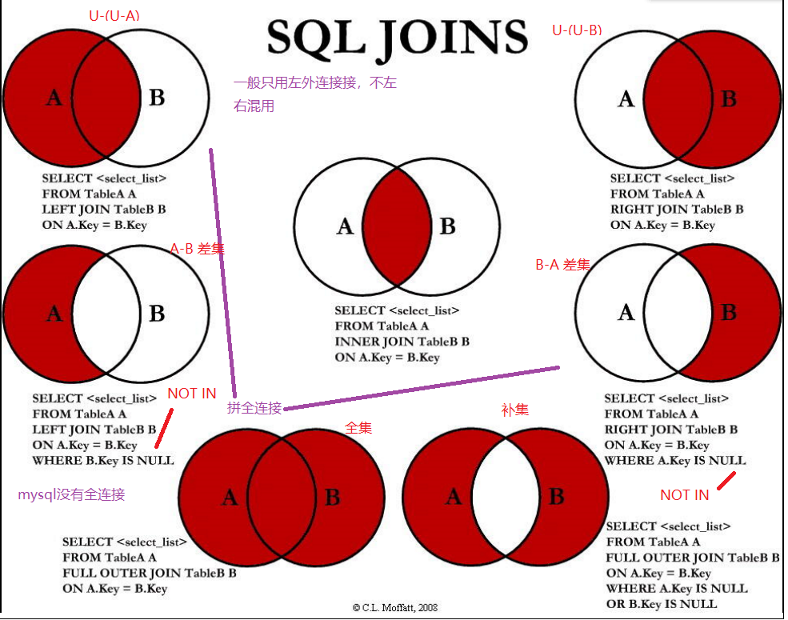
JOIN
嵌套
统计薪资 大于 薪资最高的员工 所在部门 的平均工资 和 薪资最低的员工所在部门的平均工资 的平均工资 的员工信息。 SELECT *
from emp k , (SELECT SUM(sal)/COUNT(*) averagesal1
FROM emp g, (SELECT empno,deptno FROM emp e,(SELECT MAX(sal) max FROM emp ) f WHERE e.sal=f.max) h WHERE g.deptno=h.deptno) l, (SELECT SUM(sal)/COUNT(*) averagesal2 FROM emp i,
(SELECT empno,deptno FROM emp e,(SELECT Min(sal) min FROM emp ) f WHERE e.sal=f.min) j WHERE i.deptno=j.deptno) m WHERE k.sal> (l.averagesal1+m.averagesal2)/2;
子查询
集合运算
交集、并集、差集
交集
查询的两表结果集相交的部分
EXISTS 关键字实现
查询工资大于1500 和部门编号是20号部门的交集(又…又) //可以理解为表1存在表2的部分(交) SELECT * from EMP e1 where EXISTS (SELECT * from EMP e where e1.deptno=e.deptno and e.deptno=20 )
并集
union 1.查询工资大于1500 和部门编号是20号部门 的并集 (去除重复) SELECT * from EMP where sal > 1500 UNION SELECT * from EMP where deptno =20 (不去除重复) SELECT * from EMP where sal > 1500 UNION ALL SELECT * from EMP where deptno =20 有可能同时满足两个条件,一般都去重
差集
通过 not EXISTS 实现
交集是存在的部分,差集是排掉存在的部分,所以都可以赢EXISTS关键字实现
//可以理解为表1不存在表2的部分(差) 将表1查询的结果-表2查询的结果,得到的部分就是两个结果的相减 SELECT * from EMP e1 where not EXISTS (SELECT * from EMP e where e1.deptno=e.deptno and e.deptno=20 )
行转列实现
把行按值区分形成新的列,行一定减少,列不一定增加
把行干到列上面去,多行变一行,自然要用到聚合和group by
常用case when结合聚合函数实现
case when实现
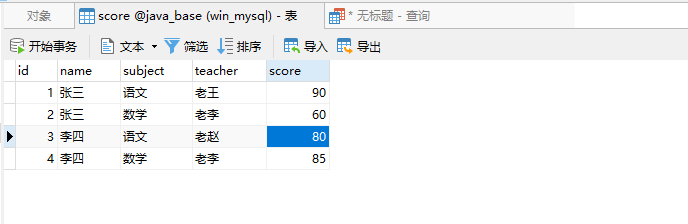
SELECT name, -- 受group by限制,需要用函数包裹 MAX(CASE SUBJECT WHEN '语文' THEN score ELSE 0 END) as '语文', MAX(CASE SUBJECT WHEN '数学' THEN score ELSE 0 END) as '数学' FROM `score` GROUP BY `name`

多列
select name, max(case subject when '语文' then score end) as "chinese", max(case subject when '语文' then goal end) as "chinese_goal", max(case subject when '数学' then score end) as "math", max(case subject when '数学' then goal end) as "math_goal" from (select * from (values (1, '张三', '语文', 80, 100), (2, '张三', '数学', 80, 95), (3, '李四', '语文', 80, 88), (4, '李四', '数学', 60, 90)) as t(id, name, subject, score, goal) )t group by name;

列转行实现
把各列的值聚拢缩成一列,列不一定减少,行一定增加
=》90°旋转

列转行一般取想要的值后用union取合并表然后对合并后的表进行排序
union实现
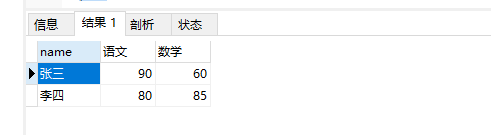
-- 对合并后的表按姓名和科目进行排序 SELECT name, subject,score from ( -- 按名称取语文的分数 SELECT `name`, '语文' as subject, `语文` as score FROM (SELECT name, -- 受group by限制,需要用函数包裹 MAX(CASE SUBJECT WHEN '语文' THEN score ELSE 0 END) as '语文', MAX(CASE SUBJECT WHEN '数学' THEN score ELSE 0 END) as '数学' FROM `score` GROUP BY `name` ) st union -- 按名称取数学的分数 SELECT `name`, '数学' as subject, `数学` as score FROM (SELECT name, -- 受group by限制,需要用函数包裹 MAX(CASE SUBJECT WHEN '语文' THEN score ELSE 0 END) as '语文', MAX(CASE SUBJECT WHEN '数学' THEN score ELSE 0 END) as '数学' FROM `score` GROUP BY `name` ) st ) tb order BY `name` , subject
作者: deity-night
出处: https://www.cnblogs.com/deity-night/
关于作者:码农
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 原文链接 如有问题, 可邮件(***@163.com)咨询.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号