


Http与Https
参考:java3y《对线面试官》
介绍
HTTP协议是客户端和服务器交互的一种通讯方式
所谓协议是双方约定好的“格式”,让双方都能看得懂
“交互”就是请求和响应

基于TCP的应用层协议,不关心数据传输细节,主要用来规定客户端和服务端的数据传输格式
无状态,默认端口80
什么是无状态
假设用户A向服务B发了一个请求1,再次发送一个请求2。 服务端本身完全不知道两个请求来自同一个用户,这在协议层次就是【无状态】的
http【无状态】仅仅是在*协议层*,当业务需要状态的时候,可以通过request中数据携带所需状态的id来实现。例如,为了让服务器知道是同一个用户的请求,请求1和请求2中必须携带一个相同的id,让服务端可以根据这个id,最终找到用户数据(【状态】)。
实现1:这个状态如果放在处理请求的服务器进程中(例如session),那服务器进程就是有状态的,该用户下一个请求如果没分发到这个进程,就会拿不到上一次请求留下的状态,这样会影响负载均衡和缓存的实现。
实现2:这个状态如果放在处理请求的服务器进程之外的集中式存储,那服务器进程仍然是无状态的,可以集群、负载均衡。无状态服务一般都用这种方案。
https://www.cnblogs.com/yfish/p/8481380.html
Http请求报文
https://www.bilibili.com/video/BV1JT411X7dt?p=3&vd_source=152ad2dc192867dca92d66a24472c851
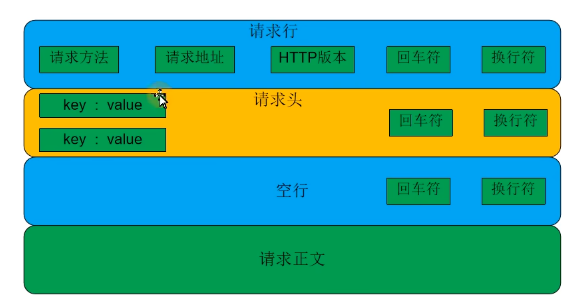
Http响应报文

HTTP个版本间的区别
Http1.0默认是短连接,每次与服务器交互都需要新开一个连接
HTTP1.1 最主要的是“默认持久连接”。只要客户端服务端没有断开TCP连接,就一直保持连接,可以发送多次HTTP请求,
其次是“断点续传”。利用Http看消息头使用分块传输编码,将实体主体分块进行传输
HTTP/2不再以⽂本的⽅式传输,采⽤「⼆进制分帧层」,对头部进⾏了「压缩」,⽀持「流控」,最主要就是HTTP/2是⽀持「多路复⽤」的(通过单⼀的TCP连接「并⾏」发起多个的请求和响应消息)
HTTP1.1提出的「管线化」只能「串⾏」(⼀个响应必须完全返回后,下⼀个请求才会开始传输)
HTTP/2多路复⽤则是利⽤「分帧」数据流,把HTTP协议分解为「互不依赖」的帧(为每个帧「标序」发送,接收回来的时候按序重组),进⽽可以「乱序」发送避免「⼀定程度上」的队⾸阻塞问题

但是,⽆论是HTTP1.1还是HTTP/2,response响应的「处理顺序」总是需要跟request请求顺序保持⼀致的。假如某个请求的response响应慢了,还是同样会有阻塞的问题。
这受限于HTTP底层的传输协议是TCP,没办法完全解决“线头阻塞”的问题
HTTP/3 跟前⾯版本最⼤的区别就是:HTTP1.x和HTTP/2底层都是TCP,⽽HTTP/3底层是UDP。使⽤HTTP/3能够减少RTT「往返时延」(TCP三次握⼿,TLS握⼿)

常见请求头
https://juejin.cn/post/6844903745004765198
Accept
- Accept: text/html 浏览器可以接受服务器回发的类型为 text/html。
- Accept: */* 代表浏览器可以处理所有类型,(一般浏览器发给服务器都是发这个)。
Host
- Host:www.baidu.com 请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的。
Refer
- Referer:https://www.baidu.com/?tn=62095104_8_oem_dg 当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的,服务器籍此可以获得一些信息用于处理。
Cookie
- Cookie是用来存储一些用户信息以便让服务器辨别用户身份的(大多数需要登录的网站上面会比较常见),比如cookie会存储一些用户的用户名和密码,当用户登录后就会在客户端产生一个cookie来存储相关信息,这样浏览器通过读取cookie的信息去服务器上验证并通过后会判定你是合法用户,从而允许查看相应网页。当然cookie里面的数据不仅仅是上述范围,还有很多信息可以存储是cookie里面,比如sessionid等。
常见响应头
https://juejin.cn/post/6844903745004765198
Content-Type
- Content-Type:text/html;charset=UTF-8 告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
Content-Encoding
- Content-Encoding:gzip 告诉客户端,服务端发送的资源是采用gzip编码的,客户端看到这个信息后,应该采用gzip对资源进行解码。
Access-Control-Allow-Origin
- Access-Control-Allow-Origin: * *号代表所有网站可以跨域资源共享,如果当前字段为*那么Access-Control-Allow-Credentials就不能为true
- Access-Control-Allow-Origin: www.baidu.com 指定哪些网站可以跨域资源共享
Https
待续。。。
Https与Http的区别
https://juejin.cn/post/7144400185731317768
作者: deity-night
出处: https://www.cnblogs.com/deity-night/
关于作者:码农
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 原文链接 如有问题, 可邮件(***@163.com)咨询.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现