
Postgresql
引入
商业角度:使用Mysql需要向Oracle付费或者将程序开源,postGreSql允许开发人员做任何事情,包括在开源或者闭源产品中商用
建表
语法
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] table_name ( [ { column_name data_type [ COMPRESSION compression_method ] [ COLLATE collation ] [ column_constraint [ ... ] ] | table_constraint | LIKE source_table [ like_option ... ] } [, ... ] ] ) [ INHERITS ( parent_table [, ... ] ) ] [ PARTITION BY { RANGE | LIST | HASH } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ] [ USING method ] [ WITH ( storage_parameter [= value] [, ... ] ) | WITHOUT OIDS ] [ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ] [ TABLESPACE tablespace_name ] CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] table_name OF type_name [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] [ PARTITION BY { RANGE | LIST | HASH } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ] [ USING method ] [ WITH ( storage_parameter [= value] [, ... ] ) | WITHOUT OIDS ] [ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ] [ TABLESPACE tablespace_name ] CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] { FOR VALUES partition_bound_spec | DEFAULT } [ PARTITION BY { RANGE | LIST | HASH } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ] [ USING method ] [ WITH ( storage_parameter [= value] [, ... ] ) | WITHOUT OIDS ] [ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ] [ TABLESPACE tablespace_name ] where column_constraint is: [ CONSTRAINT constraint_name ] { NOT NULL | NULL | CHECK ( expression ) [ NO INHERIT ] | DEFAULT default_expr | GENERATED ALWAYS AS ( generation_expr ) STORED | GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY [ ( sequence_options ) ] | UNIQUE [ NULLS [ NOT ] DISTINCT ] index_parameters | PRIMARY KEY index_parameters | REFERENCES reftable [ ( refcolumn ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELETE referential_action ] [ ON UPDATE referential_action ] } [ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ] and table_constraint is: [ CONSTRAINT constraint_name ] { CHECK ( expression ) [ NO INHERIT ] | UNIQUE [ NULLS [ NOT ] DISTINCT ] ( column_name [, ... ] ) index_parameters | PRIMARY KEY ( column_name [, ... ] ) index_parameters | EXCLUDE [ USING index_method ] ( exclude_element WITH operator [, ... ] ) index_parameters [ WHERE ( predicate ) ] | FOREIGN KEY ( column_name [, ... ] ) REFERENCES reftable [ ( refcolumn [, ... ] ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELETE referential_action ] [ ON UPDATE referential_action ] } [ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ] and like_option is: { INCLUDING | EXCLUDING } { COMMENTS | COMPRESSION | CONSTRAINTS | DEFAULTS | GENERATED | IDENTITY | INDEXES | STATISTICS | STORAGE | ALL } and partition_bound_spec is: IN ( partition_bound_expr [, ...] ) | FROM ( { partition_bound_expr | MINVALUE | MAXVALUE } [, ...] ) TO ( { partition_bound_expr | MINVALUE | MAXVALUE } [, ...] ) | WITH ( MODULUS numeric_literal, REMAINDER numeric_literal ) index_parameters in UNIQUE, PRIMARY KEY, and EXCLUDE constraints are: [ INCLUDE ( column_name [, ... ] ) ] [ WITH ( storage_parameter [= value] [, ... ] ) ] [ USING INDEX TABLESPACE tablespace_name ] exclude_element in an EXCLUDE constraint is: { column_name | ( expression ) } [ opclass ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] referential_action in a FOREIGN KEY/REFERENCES constraint is: { NO ACTION | RESTRICT | CASCADE | SET NULL [ ( column_name [, ... ] ) ] | SET DEFAULT [ ( column_name [, ... ] ) ] }
复制并创建表
create table as
--where 1=0不成立,但是表结构会创建,否则会将数据插入 CREATE TABLE employees_history As SELECT * FROM employees WHERE 1=0;
select into froim
select *(查询出来的结果) into newtable(新的表名) from oldtable where (后续条件)
约束
字段约束
表级约束
CREATE TABLE employees ( employee_id INTEGER NOT NULL , first_name CHARACTER VARYING(20) , last_name CHARACTER VARYING(25) NOT NULL , email CHARACTER VARYING(25) NOT NULL , phone_number CHARACTER VARYING(20) , hire_date DATE NOT NULL , salary NUMERIC(8,2) , commission_pct NUMERIC(2,2) , manager_id INTEGER , department_id INTEGER , CONSTRAINT emp_emp_id_pk PRIMARY KEY (employee_id) , CONSTRAINT emp_salary_min CHECK (salary > 0) , CONSTRAINT emp_email_uk UNIQUE (email) , CONSTRAINT emp_dept_fk FOREIGN KEY (department_id) REFERENCES departments(department_id) , CONSTRAINT emp_manager_fk FOREIGN KEY (manager_id) REFERENCES employees(employee_id) ) ;
修改表
添加字段
ALTER TABLE table_name ADD COLUMN column_name data_type column_constraint;
删除字段
--字段删除后相关的约束也会没有 ALTER TABLE table_name DROP COLUMN column_name;
添加约束
ALTER TABLE table_name ADD table_constraint;
删除约束
ALTER TABLE table_name DROP CONSTRAINT constraint_name [ RESTRICT | CASCADE ];
特殊删除非空约束
ALTER TABLE table_name ALTER COLUMN column_name DROP NOT NULL;
修改字段默认值
ALTER TABLE table_name ALTER COLUMN column_name SET DEFAULT value;
删除已有默认值
ALTER TABLE table_name ALTER COLUMN column_name DROP DEFAULT;
DQL
分页
分页 limit 条数 offet 偏移量 (mysql 中 limit offset,number)
模糊匹配
like 普通模糊匹配
ilike 支持忽略带小写模糊匹配
distinct
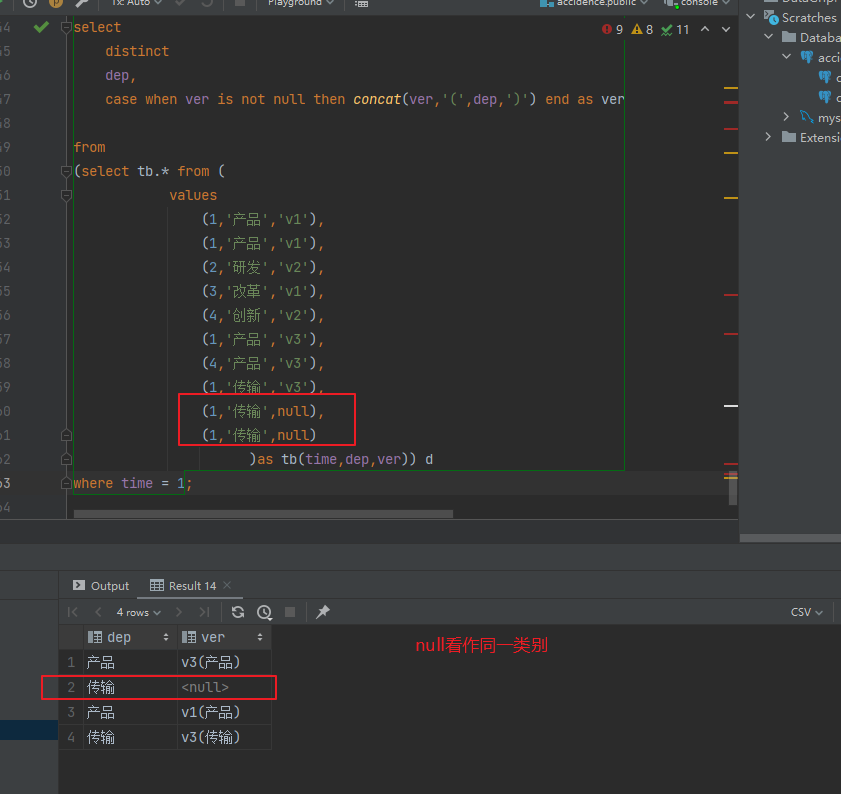
只能放在字段开头,后面的所有字段一起去重,去重时null看作同一类,和group by一样
select distinct dep, case when ver is not null then concat(ver,'(',dep,')') end as ver from (select tb.* from ( values (1,'产品','v1'), (1,'产品','v1'), (2,'研发','v2'), (3,'改革','v1'), (4,'创新','v2'), (1,'产品','v3'), (4,'产品','v3'), (1,'传输','v3'), (1,'传输',null), (1,'传输',null) )as tb(time,dep,ver)) d where time = 1;
批量(/关联)更新
可以通过关联更新实现
表emp1与表emp id相等的就进行更新,要通过条件进行关联
UPDATE emp1 SET salary = emp.salary, department_id = emp.department_id, manager_id = emp.manager_id FROM emp WHERE emp1.employee_id = emp.employee_id;
批量(/连表)删除
批量删除可以用连表删除来实现
DELETE FROM emp1 USING emp WHERE emp1.employee_id = emp.employee_id;
多表全量数据全连接
数据分析
相交的正常连接,不相交的单独占一行,没关联数据的那张表的这一行字段全为null
表a full outer join 表b,先看表b的 反着看
有值的表代表那一行数据
两张表全连接select * from(select * from( values ('ys','yun', '1', '张'), ('ys','yun', '3', '张'), ('ys','lite', '2', '张'), ('nn','v', '9', '张'))as tb(vv,time, relate, com)) a full outer join ( (select * from (values (1,'1','李'), (2,'3','李'), (3,'2','李'), (4,'4','李'), (5,'11','李') )as tb(id,relate,haha) ) ) b

三张表关联
select * from(select * from( values ('ys','yun', '1', '张'), ('ys','yun', '3', '张'), ('ys','lite', '2', '张'), ('nn','v', '9', '张'))as tb(vv,time, relate, com)) a full outer join ( (select * from (values (1,'1','李'), (2,'3','李'), (3,'2','李'), (4,'4','李'), (5,'11','李') )as tb(id,relate,haha) ) ) b on a.relate = b.relate full outer join( (select * from (values (1,'1','sit'), (2,'3','sit'), (3,'2','sit'), (4,'11','sit'), (79,'9','sit') )as tb(xx,relate,yeye)) )c on b.relate = c.relate;

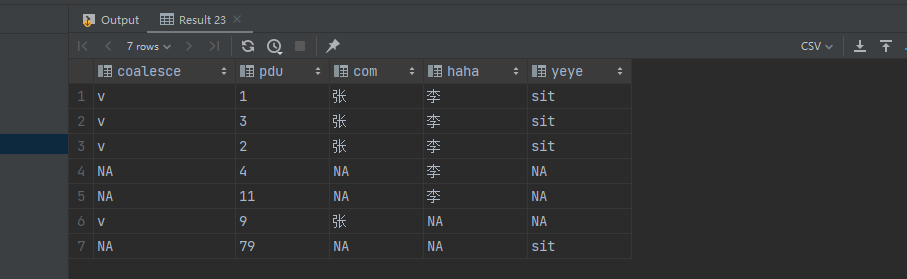
--三张表全连接,连接字段relation,没有值的填充NA
select coalesce(a.time, 'NA'), -- 关联字段 coalesce(a.relate,b.relate,c.relate) as pdu, coalesce(a.com, 'NA') com, coalesce(b.haha, 'NA') haha, coalesce(c.yeye, 'NA') yeye from (select tb.* from (values ('v', '1', '张'), ('v', '3', '张'), ('v', '2', '张'), ('v', '9', '张')) as tb(time, relate, com))a full outer join (select tb.* from ( values (1,'1','李'), (2,'3','李'), (3,'2','李'), (4,'4','李'), (5,'11','李') )as tb(id,relate,haha)) b on a.relate = b.relate full outer join (select tb.* from ( values (1,'1','sit'), (2,'3','sit'), (3,'2','sit'), (4,'79','sit') )as tb(xx,relate,yeye)) c --关联条件 on b.relate = c.relate
通过pdu关联
多关联字段
跟一个关联字段一样的,就把多个关联字段当成一个关联字段就ok了
select * from (select * from (values (1,'1','李'), (2,'3','李') )as tb(id,relate,haha) ) a full outer join (select * from (values (1,'1','李'), (2,'4','李') )as tb(id,relate,haha) ) b on a.id = b.id and a.relate = b.relate;

合并
select --关联字段,谁有值取谁 coalesce(a.id,b.id) as id, coalesce(a.relate,b.relate) as relate, --非关联字段,没有就为空 coalesce(a.avalue, 'NA'), coalesce(b.bvalue, 'NA') from (select * from (values (1,'1','李'), (2,'3','李') )as tb(id,relate,avalue) ) a full outer join (select * from (values (1,'1','李'), (2,'4','李') )as tb(id,relate,bvalue) ) b on a.id = b.id and a.relate = b.relate;
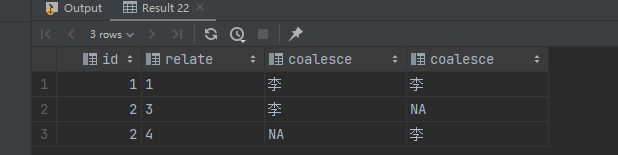
对于关联字段有为空的
理论上空应该认为相同,数据相交的数据,但是默认认为不同
select --关联字段,谁有值取谁 coalesce(a.id,b.id) as id, coalesce(a.relate,b.relate) as relate, --非关联字段,没有就为空 coalesce(a.avalue, 'NA'), coalesce(b.bvalue, 'NA') from (select * from (values (1,'1','李'), (2,null,'sdv') )as tb(id,relate,avalue) ) a full outer join (select * from (values (1,'1','妹'), (2,null,'sit') )as tb(id,relate,bvalue) ) b on a.id = b.id and a.relate = b.relate;
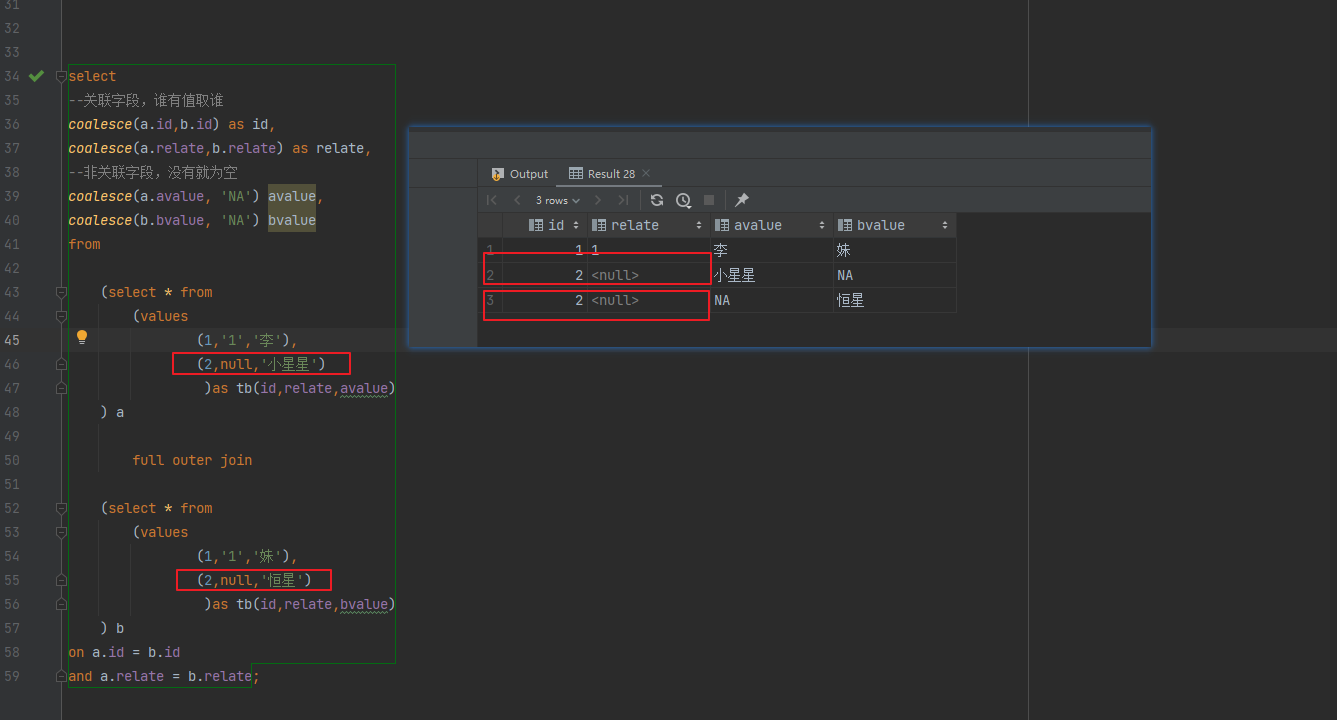
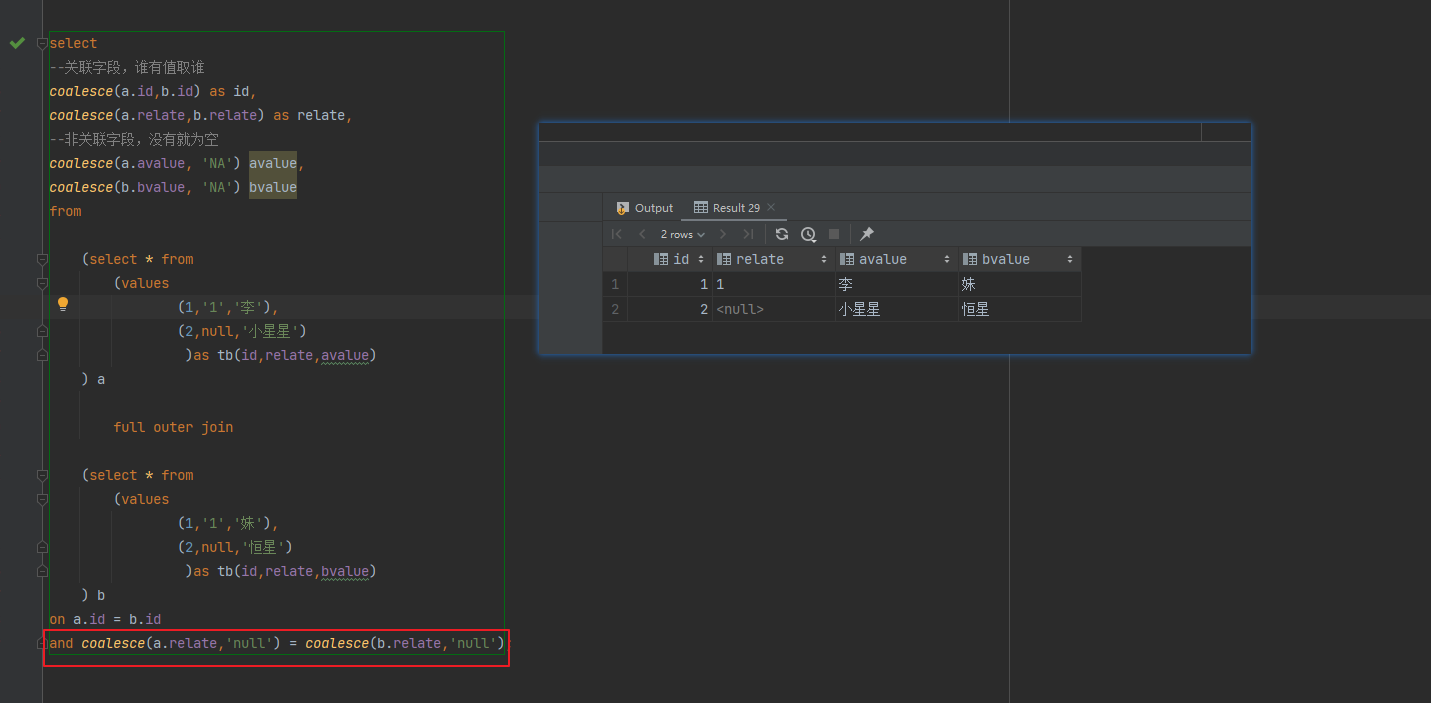
解决:作为关联条件判断时,可以通过对为空的情况做下处理
select --关联字段,谁有值取谁 coalesce(a.id,b.id) as id, coalesce(a.relate,b.relate) as relate, --非关联字段,没有就为空 coalesce(a.avalue, 'NA') avalue, coalesce(b.bvalue, 'NA') bvalue from (select * from (values (1,'1','李'), (2,null,'小星星') )as tb(id,relate,avalue) ) a full outer join (select * from (values (1,'1','妹'), (2,null,'恒星') )as tb(id,relate,bvalue) ) b on a.id = b.id and coalesce(a.relate,'null') = coalesce(b.relate,'null');
自定义排序
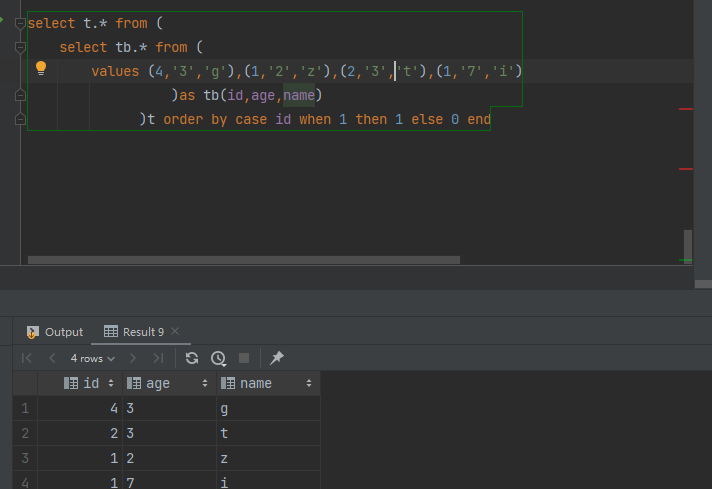
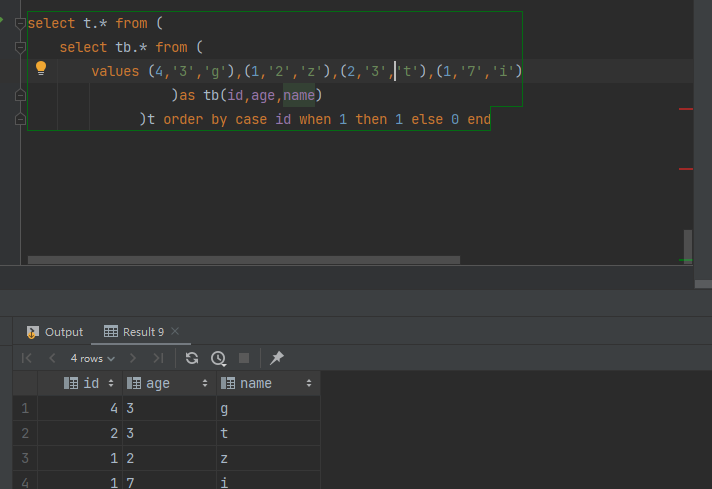
case when 指定顺序
select t.* from ( select tb.* from ( values (4,'3','g'), (1,'2','z'), (2,'3','t'), (1,'7','i') )as tb(id,age,name) )t order by case id when 1 then 0 else 1 end
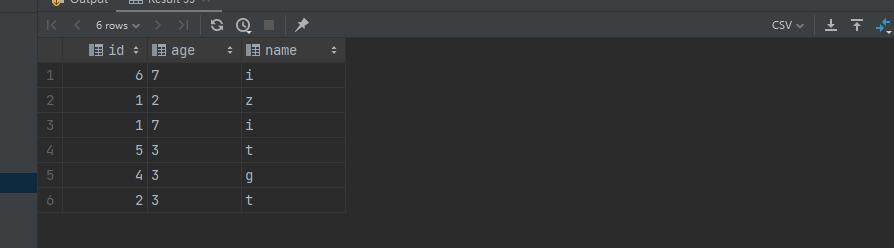
select t.* from (select tb.* from ( values (6, '7', 'i'), (5, '3', 't'), (4, '3', 'g'), (1, '2', 'z'), (2, '3', 't'), (1, '7', 'i') )as tb(id, age, name)) t order by case id when 6 then 1 when 1 then 3 when 3 then 2 end;
分段排序
select t.* from ( select tb.* from ( values (4,'3','g'),(1,'2','z'),(2,'3','t'),(1,'7','i') )as tb(id,age,name) )t order by id < 2, id;
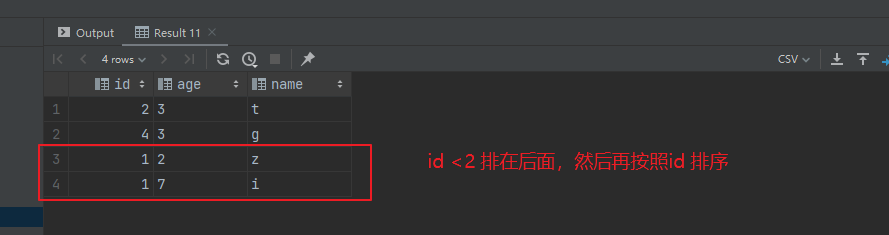
外连接
- 左外连接(LEFT OUTER JOIN)
- 右外连接(RIGHT OUTER JOIN)
- 全外连接(FULL OUTER JOIN)
窗口函数排名
select id,age,name,
--partition 分组字段 order by 比较字段/排序字段 row_number() over (partition by id order by age), rank() over (partition by id order by age), dense_rank() over (partition by id order by age), percent_rank() over (partition by id order by age) from ( select tb.* from ( values (4,'3','g'), (1,'2','z'), (2,'3','t'), (1,'7','i'), (1,'8', null), (1,null, null), (1,'8', null), (1,'9', null) )as tb(id,age,name) )t

多表全量数据连接结合排名窗口
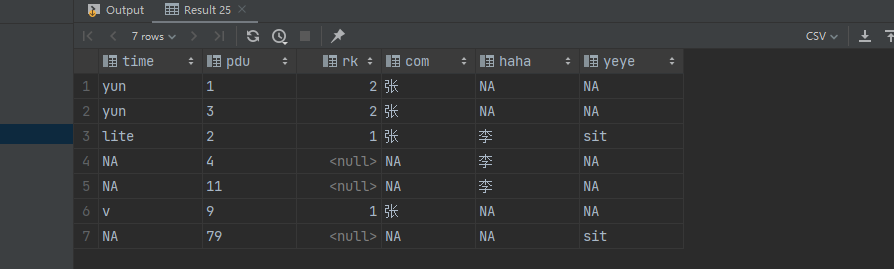
select coalesce(a.time, 'NA') as time, -- 关联字段 coalesce(a.relate,b.relate,c.relate) as pdu, a.rk, coalesce(a.com, 'NA') com, -- 如果rk不是第一个,余下的就NA case when a.rk <> 1 then 'NA' else coalesce(b.haha, 'NA') end as haha, case when a.rk <> 1 then 'NA' else coalesce(c.yeye, 'NA') end as yeye from (select tb.*,rank() over (partition by vv order by time) rk from (values ('ys','yun', '1', '张'), ('ys','yun', '3', '张'), ('ys','lite', '2', '张'), ('nn','v', '9', '张')) as tb(vv,time, relate, com))a full outer join (select tb.* from ( values (1,'1','李'), (2,'3','李'), (3,'2','李'), (4,'4','李'), (5,'11','李') )as tb(id,relate,haha)) b on a.relate = b.relate full outer join (select tb.* from ( values (1,'1','sit'), (2,'3','sit'), (3,'2','sit'), (4,'79','sit') )as tb(xx,relate,yeye)) c --关联条件 on b.relate = c.relate
索引
Explain
利用 EXPLAIN 命令可以看到数据库的执行计划
explain analyze SELECT name FROM test WHERE id = 10000; QUERY PLAN | ------------------------------------------------------------------------| Gather (cost=1000.00..107137.70 rows=1 width=11) (actual time=50.266..12082.777 rows=1 loops=1) | Workers Planned: 2 | Workers Launched: 2 | -> Parallel Seq Scan on test (cost=0.00..106137.60 rows=1 width=11) (actual time=7674.992..11553.964 rows=0 loops=3)| Filter: (id = 10000) | Rows Removed by Filter: 3333333 | Planning Time: 16.480 ms | Execution Time: 12093.016 ms
Parallel Seq Scan 表示并行顺序扫描,执行消耗了 12s;由于表中有包含大量数据,而查询只
返回一行数据,显然这种方法效率很低。
参考:https://tonydong.blog.csdn.net/article/details/103579177
Index Scan 表示索引扫描
创建索引
CREATE INDEX index_name ON table_name [USING method] (column_name [ASC | DESC] [NULLS FIRST | NULLS LAST]);
• index_name 是索引的名称,table_name 是表的名称;
• method 表示索引的类型,例如 btree、hash、gist、spgist、gin 或者 brin。默认为 btree;
• column_name 是字段名,ASC 表示升序排序(默认值),DESC 表示降序索引;
• NULLS FIRST 和 NULLS LAST 表示索引中空值的排列顺序,升序索引时默认为 NULLS
LAST,降序索引时默认为 NULLS FIRST
唯一索引
对于主键和唯一约束,PostgreSQL 会自动创建一个唯一索引,从而确保唯一性。
CREATE UNIQUE INDEX index_name ON table_name (column_name [ASC | DESC] [NULLS FIRST | NULLS LAST]);
组合索引
CREATE [UNIQUE] INDEX index_name ON table_name [USING method] (column1 [ASC | DESC] [NULLS FIRST | NULLS LAST], ...);
对于多列索引,应该将最常作为查询条件使用的字段放在左边,较少使用的字段放在右边。
例如,基于(c1, c2, c3)创建的索引可以优化以下查询:
WHERE c1 = v1 and c2 = v2 and c3 = v3; WHERE c1 = v1 and c2 = v2; WHERE c1 = v1;
以下查询无法使用该索引:
WHERE c2 = v2; WHERE c3 = v3; WHERE c2 = v2 and c3 = v3;
对于多列唯一索引,字段的组合值不能重复;但是如果某个字段是空值,其他字段可以出现
重复值
函数
字符串函数
参考:https://lewky.cn/posts/postgresql-string.html/
以什么字符开头可以用left(str,length)实现
select * from "testTable" where left(name, 1) like 'z';

字符串长度
-- 单个参数 仅判断长度 select length('xxx'); -- 多个参数,可以指定字符编码 select length('xxx', 'UTF8');
聚合函数
STRING_AGG ( expression, separator [order_by_clause] ) 用于连接字符串列表并在字符串之间放置分隔符。
expression是可以解析为字符串的任何有效表达式。separator是串联字符串的分隔符。
条件函数
case when then end
case column when value then returnValue end eg: case class_type when 'tax' then code end
coalesce
COALESCE(exp1,exp2,expn…) 从头开始判断,返回非空值
SELECT date_in, (date_in + '1 D') "date_in+ 1" FROM et WHERE date_in BETWEEN '2022-04-15 21:37:00' AND COALESCE(NULL, date_in + interval '1 D') // 或者 '1' DAY
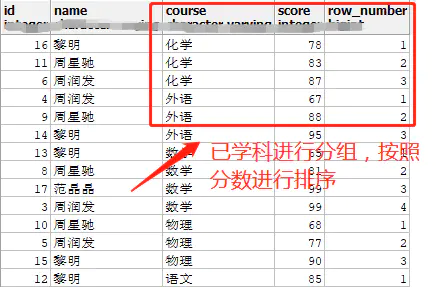
分组排序函数
分组排序 row_number() over( [partition by col1] order by col2[desc])
row_number():为返回的记录定义各行编号
partition by col1:根据col1进行分组;
order by col2:根据col2进行排序。
原始数据:
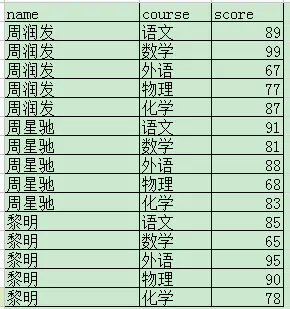
select *, row_number() over(partition by course order by score desc) from student;
参考:https://www.jianshu.com/p/955aff947788
存储过程
定义
CREATE [ OR REPLACE ] PROCEDURE name ( [ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ] ) AS $$ DECLARE declarations BEGIN statements; ... END; $$ LANGUAGE plpgsql;
列转行
方式一:union
方式二:unnest
unnest的数组有长度限制 40 左右
单个unnest使用
select '张三' as name , unnest(string_to_array('语文,数学,英语',',')) as subject;
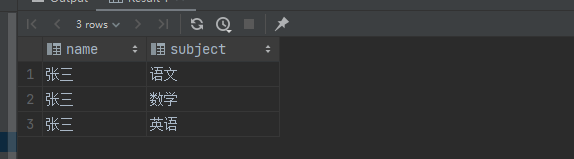
多个unnest使用
不同unnest的数组长度一样/不一样都是是按顺序1对1匹配 pg15是这样,旧版本长度不一致可能迪卡尔乘积
长度一样
select '张三' as name , unnest(string_to_array('语文,数学,英语',',')) as subject, unnest(string_to_array('124,69,120',',')) as score;

数组长度不一样
select '张三' as name , unnest(string_to_array('语文,数学,英语',',')) as subject, unnest(string_to_array('124,69',',')) as score;
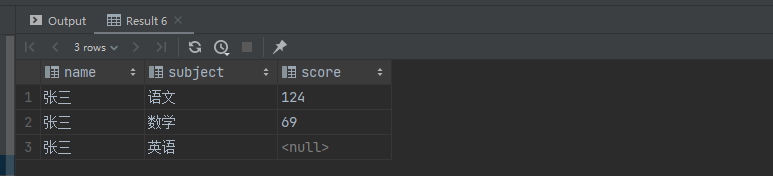
处理尾随0
https://www.modb.pro/db/427676
pg12
rtrim结合numeric类型
select rtrim('100.00','0')::numeric||'%';
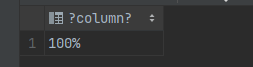
select rtrim('100.50','0')::numeric||'%';
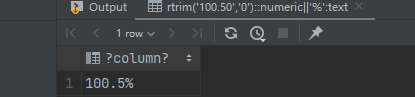
PostgreSQL 13 及以上
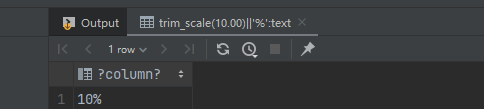
SELECT trim_scale(10.00)||'%';
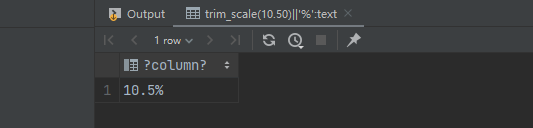
SELECT trim_scale(10.50)||'%';
换行
使用 逃逸字符 表示法 E '\n'
select string_agg(subject,E'\n') from (select * from (values (1, '张三', '语文', 80, 100,'1'), (2, '张三', '数学', 80, 95,'%'), (3, '李四', '语文', 80, 88,'1'), (4, '李四', '数学', 60, 90,'%')) as t(id, name, subject, score, goal,unit)) b group by name
作者: deity-night
出处: https://www.cnblogs.com/deity-night/
关于作者:码农
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 原文链接 如有问题, 可邮件(***@163.com)咨询.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号