
Redis高可用
引入
参考博文:https://blog.csdn.net/qq_15270521/article/details/122795605、https://juejin.cn/post/7097521572885299214
redis有提供了主从、哨兵、代理集群与分片集群的高可用机制来保证出现单点问题时能够及时的切换机器以保障整个系统不受到影响。后续的三种高可用机制都是基于主从的基础上来实现的
主从复制
解决读写压力,提高吞吐量
优点:
- 能够为后续的高可用机制打下基础
- 在持久化的基础上能够将数据同步到其他机器,在极端情况下做到灾备的效果
- 能够通过主写从读的形式实现读写分离提升Redis整体吞吐,并且读的性能可以通过对从节点进行线性扩容无限提升
缺点:
- 全量数据同步时如果数据量比较大,在之前会导致线上短暂性的卡顿
- 一旦主节点宕机,从节点晋升为主节点,同时需要修改应用方的主节点地址,还需要命令所有从节点去复制新的主节点,整个过程需要人工干预
- 写入的QPS性能受到主节点限制,虽然主从复制能够通过读写分离来提升整体性能,但是只有从节点能够做到线性扩容升吞吐,写入的性能还是受到主节点限制
- 木桶效应,整个Redis节点群能够存储的数据容量受到所有节点中内存最小的那台限制,比如一主两从架构:master=32GB、slave1=32GB、slave2=16GB,那么整个Redis节点群能够存储的最大容量为16GB
主从复制原理:
Redis2.8之前使用sync[runId][offset]同步命令,Redis2.8之后使用psync[runId][offset]命令。两者不同在于,sync命令仅支持全量复制过程,psync支持全量和部分复制
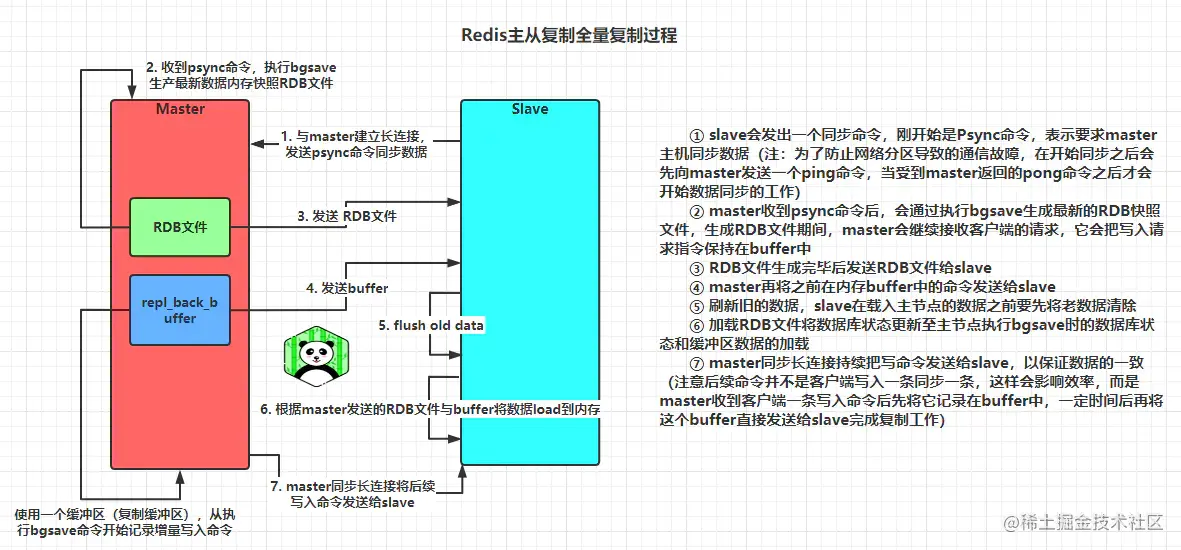
psyn部分复制

一主多从的形式
主能读能写(能写就能读),从只能读 (保证数据一致)
一般是master写,slave读, 通过对slave节点线性扩容可以提高读的QPS
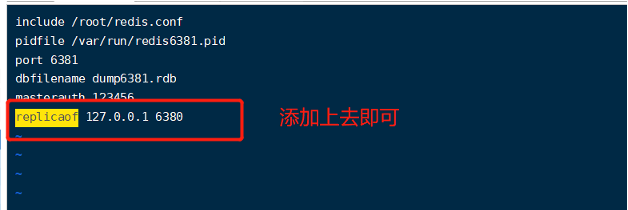
创建配置文件
主服务器宕机,要在剩下的从服务器再次建立主从关系的话,需要将其中一个解除主从关系——slaveof no one,再与另外的建立主从关系,共两步。
创建配置文件
配置配置文件

启动服务
查看启动的服务

查看服务器信息
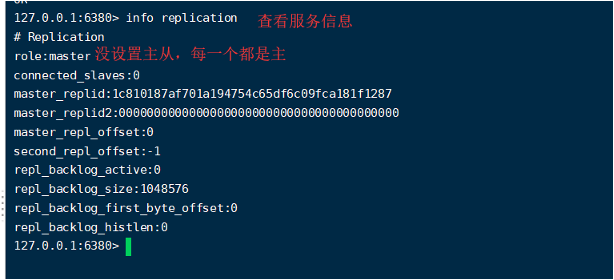
切入点问题,slave1、slave2是从头开始复制还是从切入点开始复制?
比如从set k4进来,那之前的set 123是否也可以复制?
答:可以,只要主从上线,主从数据一定一致
从机是否可以写?
主机shutdown后情况如何?从机是上位还是原地待命?
答:原地待命
主机又回来了后,主机新增记录,从机还能否顺利复制?
答:主从时刻保持一致
其中一台从机down后情况如何?依照原有它能跟上大部队吗?
答:down机后从新连接上,依旧保持主从数据一致
主从全部关闭后,主从关系还在不在?
答:主从全部关闭后,主从关系将不存在,除非在配置文件中配置主从关系
薪火相传的形式
• 上一个slave可以是下一个slave的Master,slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master, 可以有效减轻master的写压力,去中心化降低风险。
• 用 slaveof 添加主从关系
• 中途变更转向:会清除之前的数据,重新建立拷贝最新的
• 风险是一旦某个slave宕机,后面的slave都没法备份

若第二个宕机,第一个和第三个没有关系,无法备份
反客为主:当第一个宕机,第二个还可以用slaveof no one 解除与第一个的主从关系,只保持与第三个的主从关系 ,一步就能够维持主从复制
哨兵模式
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器(通过slave of 解除主从关系,然后与新的从机建立主从),这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。
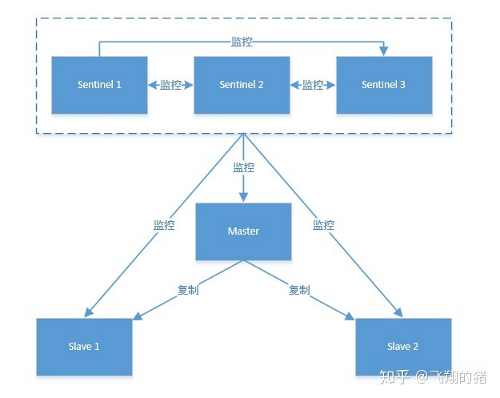
能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库.哨兵是一个独立的进程,对redis实例起到监控作用 包括主、从节点
作用:
- 监控 对所有redis实例进行监控 info主节点和从节点获取级联信息
- 留言 决定master是否故障 每隔1s会ping其他哨兵节点和主从节点做心跳检查
- 投票 选择一个slave作为master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机 通过订阅频道来了解其他哨兵节点信息以及对主节点的存活判断

缺点:主数据库出现故障时,选举切换的时候容易出现瞬间断线现象
判断在线情况: 默认情况下,每个 Sentinel 节点会以 每秒一次 的频率对 Redis 节点和 其它 的 Sentinel 节点发送 PING 命令,
并通过节点的 回复 来判断节点是否在线。
主观下线:
主观下线 适用于所有 主节点 和 从节点。如果在 down-after-milliseconds 毫秒内,Sentinel 没有收到 目标节点 的有效回复(ping-pang机制),
则会判定 该节点为主观下线,然后询问其他sentinal是否同意(客观下线)(要求其他哨兵也对该节点进行判断)
客观下线:
只有半数个哨兵节点都主观判定主节点down掉,此时多个哨兵节点交换主观判定结果,才会判定主节点客观下线。
票数:
sentinel monitor mymaster 127.0.0.1 6379 2(qurom)
只需要多个sentinel互相沟通来确认某个master是否真的死了,这个2(qurom)代表,当集群中有2个sentinel认为master死了时,才能真正认为该master已经不可用了(客观下线)
一般设置为 setinel总个数/2+1
选举:
每个发现主服务器进入客观下线的sentinel都可以要求其他sentinel选自己为领头sentinel,选举是先到先得。
同时每个sentinel每次选举都会自增配置纪元,每个纪元中只会选择一个领头sentinel。
如果所有超过一半的sentinel选举某sentinel领头sentinel。之后该sentinel进行故障转移操作。
failover故障转移(大多数条件):
超过qurom个sentinal判定主节点客观下线 会触发failover 故障迁移
当failover主备切换真正被触发后,failover并不会马上进行,还需要sentinel中的大多数sentinel授权(选举领头sentinal)后,
由领头sentinal可以进行failover。(如果票数比大多数还要大的时候,则询问更多的sentinel)
eg:例如,集群中有5个sentinel,票数被设置为2,当2个sentinel认为一个master已经不可用了以后,将会触发failover,
但是,进行failover的那个sentinel必须先获得至少3个sentinel的授权才可以实行failover。
哨兵机制优点:
解决了之前主从切换需要人工干预问题,保证了一定意义上的高可用
哨兵机制缺点:
全量数据同步仍然会导致线上出现短暂卡顿
写入QPS仍然受到主节点单机限制,对于写入并发较高的项目无法满足需求
仍然存在主从复制时的木桶效应问题,存储容量受到节点群中最小内存机器限制
配置哨兵
• 假设调整为一主二从
• 在使用目录下新建sentinel.conf文件
• 在配置文件中填写内容:
sentinel monitor mymaster 127.0.0.1 6379 1
• 其中mymaster是为监控对象起的服务器名称, 1 为 至少有多少个数量的哨兵同意迁移(投票)
• 补充:要加入master的密码,不然切换不了

启动:
执行配置的sentinel.conf配置文件 redis-sentinel /xxx/sentinel.conf
故障恢复:

可在配置文件中设置优先级 replica-priority 100 为默认值 值越小,优先级越高
master shutdown后按上面三个优先顺序进行选择切换新的master,新的master要重新auth
关闭master后
51688:X 08 Aug 2020 21:55:54.304 # +switch-master mymaster 127.0.0.1 6380 127.0.0.1 6382 用6382替换 51688:X 08 Aug 2020 21:55:54.307 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6382 重新设置6381主从 51688:X 08 Aug 2020 21:55:54.307 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6382 重新设置6380主从 51688:X 08 Aug 2020 21:56:24.348 # +sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6382
分片式集群
所谓的集群,就是通过添加服务器的数量,提供相同的服务,从而让服务器达到一个稳定、高效的状态。
redis cluster是去中心化,去中间件的,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
客户端连接任意节点即可,可以设置从节点只能读,在从节点读取数据后会自动跳到该键对应主节点连接上
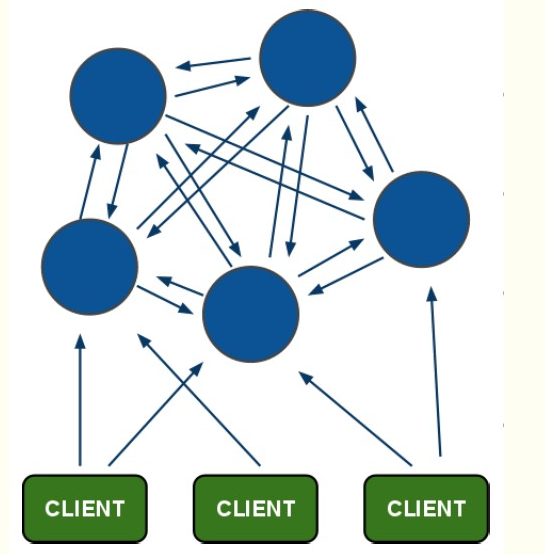
投票容错机制
超过半数的节点投票认为节点挂了,那么节点就被认为是挂了
实时监控
每个节点都可以认为是哨兵,发现某节点ping不通后(主观下线)广播信息给其他节点要求判断节点状态,其他节点对该故障节点进行判断(ping-pang),将结果信息发送给发起节点,发现超过半数认为故障(客观下线)即将该节点状态标记为故障
集群的重新选举Master
某从节点发现主节点故障,要求进行投票,其他Master进行投票,获得超过半数票数的slave晋升为新master
如果选举不成功,会等待随机时间后重新进行选举
必要性
(1)单个redis存在不稳定性。当redis服务宕机了,就没有可用的服务了。
(2)单个redis的读写能力是有限的。
说明
(1)redis集群中,每一个redis称之为一个节点。
(2)redis集群中,有两种类型的节点:主节点(master)、从节点(slave)。
(3)redis集群,是基于redis主从复制实现。
如何分配节点和数据?
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的(数据分片)。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。
注意的是:必须要3个以上的主节点,否则在创建集群时会失败。
基于主从模式
redis cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当这个主节点挂掉后,就会从节点中选取一个来充当主节点,从而保证集群不会挂掉。
主节点下线,从节点自动升为主节点
主节点恢复后自动变为从节点
集群挂掉
某一段插槽的主从节点都宕机,redis集群服务不可用,redis.conf中的参数 cluster-require-full-coverage yes为默认值,限制16384个slot都正常的时候才能对外提供服务
为什么至少三主三从?
- 2个主节点,没法获得超过半数票数认为节点挂了,所以最少3个,加上每个主节点一个slave进行备份,就是6个,即三主三从
- 奇数个主节点比偶数个更能节约机器资源,比如三个主节点与四个主节点相比,假如都挂了一个,三个主节点的只需要两个节点参与投票就能判断挂了,四个主节点的需要剩下三个节点都参与投票才能判断节点是否挂了
作者: deity-night
出处: https://www.cnblogs.com/deity-night/
关于作者:码农
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 原文链接 如有问题, 可邮件(***@163.com)咨询.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号