
Redis
是什么
推荐掘金博文:https://juejin.cn/post/7097521572885299214
键值类型数据库,主要用来做缓存
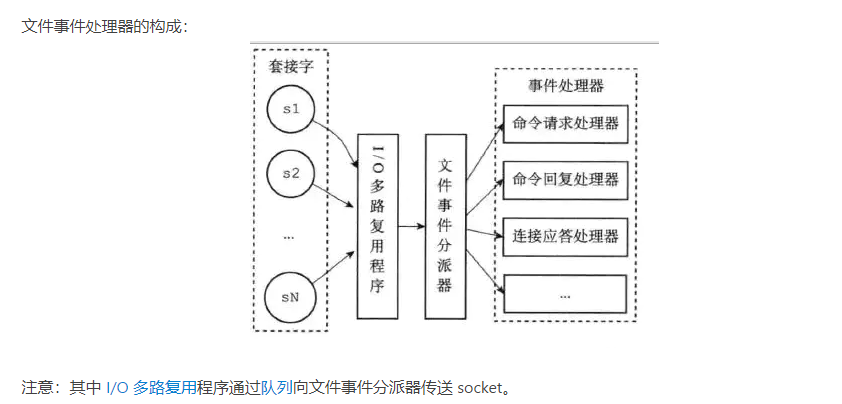
单线程+多路IO复用
多路IO复用:
实时监视redis全部请求任务,已经准备好的请求直接交给redis处理,redis不会停,没有阻塞状态
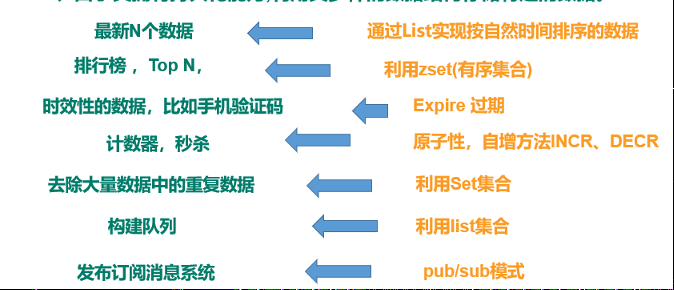
数据类型
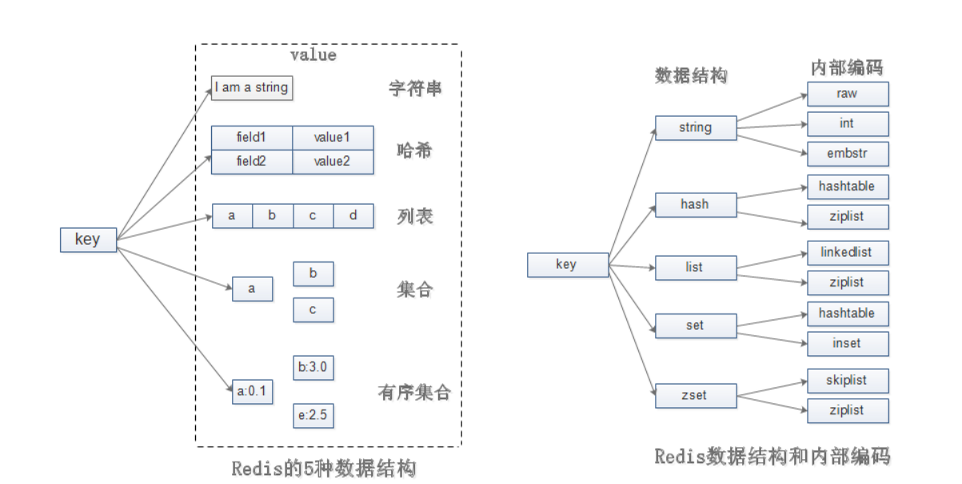
String
字符串以 k v的形式,redis存储默认没有双引号
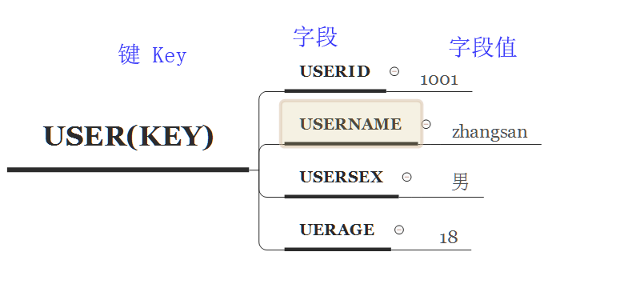
Hash
以 key field1 value1,field2 value2,field3 value3…的形式
hash叫散列类型,它提供了字段和字段值的映射,字段值只能是字符串,不支持散列类型、集合类型等其它类型
List
以 key value1 value2 value3…的形式
底层是双向链表
set
以 key value1 value2 value3… 的形式
sorted set
每个元素维护一个分数,基于分数排序
k score1 member1 score2 member2…
对应场景
为什么是单线程
什么是多路IO复用
redis基于系统函数seledt/poll/epoll/kqueue等,实现单线程监听多个socket就绪状态来管理多个IO流
操作系统为你提供了一个功能,当你的某个 socket 可读或者可写的时候,它可以给你一个通知,通过select/poll/epoll等系统函数实现。这些函数可以同时监听多个描述符的读写就绪状态,
这样,多个描述符的 I/O 操作都能在一个线程内并发交替地顺序完成,这就叫多路IO复用。
多路---指的是多个 socket 连接,复用---指的是复用同一个 Redis 处理线程
多路复用主要有三种技术:select,poll,epoll。
多路复用三种模式
select->poll→epoll
前两种都是轮询,只不过Poll解决了select监视文件描述符个数上的限制
epoll遍历后告知应该做的操作,解决了个数限制与轮询的问题
为什么快
Redis 是基于内存的,内存的读写速度非常快
Redis 是单线程的,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
Redis 使用多路复用技术,可以处理并发的连接。非阻塞 IO 实现采用 epoll,采用了 epoll+自己实现的简单的事件框架。epoll 中的读、写、关闭、连接都转化成了事件,然后利用 epoll 的多路复用特性,绝不在 IO 上浪费一点时间
数据结构简单,对数据操作也简单
Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
Redis没有多线程?
Redis6.0 引⼊多线程主要是为了提⾼⽹络 IO 读写性能,因为这个算是 Redis 中的⼀个性能瓶颈
(Redis 的瓶颈主要受限于内存和⽹络)。
虽然,Redis6.0 引⼊了多线程,但是 Redis 的多线程只是在⽹络数据的读写这类耗时操作上使⽤
了, 执⾏命令仍然是单线程顺序执⾏。因此,你也不需要担⼼线程安全问题。
Redis6.0 的多线程默认是禁⽤的--参考javaGuide面试指导
为什么给缓存数据设置过期时间?
因为内存是有限的
Redis中除了字符串类型有⾃⼰独有设置过期时间的命令 setex 外,其他⽅法都需要依靠
expire 命令来设置过期时间 。另外, persist 命令可以移除⼀个键的过期时间
而且设置过期时间可以用在数据在一定时间后失效的场景,如验证码
Redis如何判断数据是否过期
Redis 通过⼀个叫做过期字典(可以看作是hash表)来保存数据过期的时间。过期字典的键指向
Redis数据库中的某个key(键),过期字典的值是⼀个long long类型的整数,这个整数保存了key所
指向的数据库键的过期时间(毫秒精度的UNIX时间戳)--参考javaGuide
过期数据的删除策略
常⽤的过期数据的删除策略
1. 惰性删除 :只会在取出key的时候才对数据进⾏过期检查。这样对CPU最友好,但是可能会造成太多过期 key 没有被删除。
2. 定期删除 : 每隔⼀段时间抽取⼀批 key 执⾏检查并删除过期key操作。并且,Redis 底层会通过限制删除操作执⾏的时⻓和频率来减少删除操作对CPU时间的影响。
定期删除对内存更加友好,惰性删除对CPU更加友好。两者各有千秋,所以Redis 采⽤的是 定期删除+惰性/懒汉式删除 。
--参考javaGuide
内存淘汰机制
总有过期删除漏掉的,Redis有数据淘汰策略
1. volatile-lru(least recently used):从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使⽤的数据淘汰 最近最少使用淘汰机制
2. volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰 临近过期淘汰机制
3. volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰 已设置过期时间中任意淘汰机制
4. allkeys-lru(least recently used):当内存不⾜以容纳新写⼊数据时,在键空间中,移除最近最少使⽤的 key(这个是最常⽤的) 内存不足时最近最少使用淘汰机制5. allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰 直接任意淘汰
6. no-eviction:禁⽌驱逐数据,也就是说当内存不⾜以容纳新写⼊数据时,新写⼊操作会报 内存不够时禁止写入
错。这个应该没⼈使⽤吧!4.0 版本后增加以下两种:
7. volatile-lfu(least frequently used):从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使⽤的数据淘汰 已设置过期时间中最少使用淘汰机制8. allkeys-lfu(least frequently used):当内存不⾜以容纳新写⼊数据时,在键空间中,移除最不经常使⽤的 key 内存不足时最少使用淘汰机制
--参考javaGuide
Redis持久化
两种方式
- rdb方式 半持久化 快照 redis默认开启
- aof方式 全持久化 文件追加
默认存储在当前目录下,在哪启动redis就存储在哪,AOF存储位置与RDB相同
可以单独使用或者结合使用。
配置可以禁用 持久化功能
也可以同时使用两种方式,此时,以aof为准。
rdb持久化方法
经过指定的时间间隔将内存中的数据集快照写入硬盘,服务器启动后就构建数据库。
实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储,压缩体积。存储的是数据,恢复也是直接恢复数据。采用写时拷贝技术,持久化的时候才会占用内存。

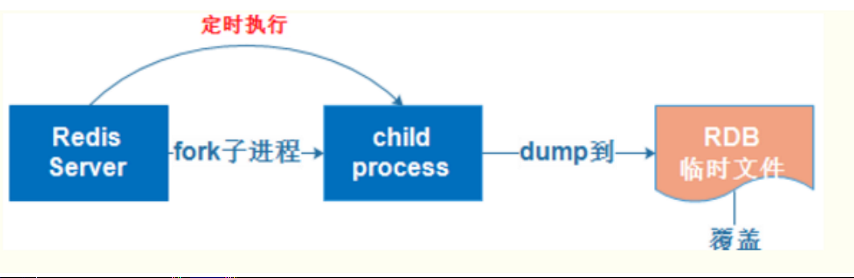
三种触发方式
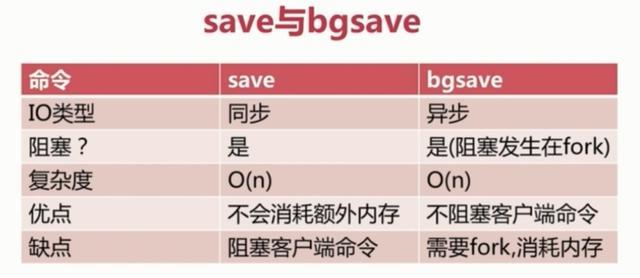
1、save触发方式
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。具体流程如下:
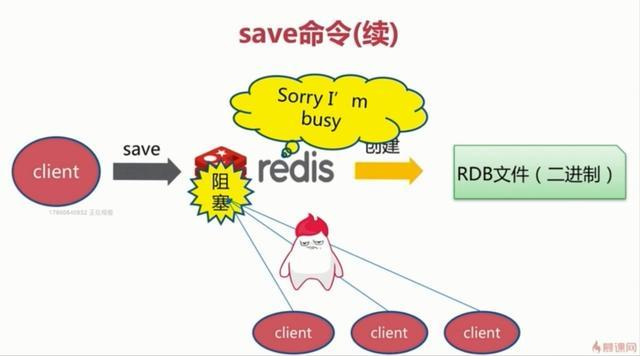
执行完成时候如果存在老的RDB文件,就用新的替代掉旧的。我们的客户端可能都是几万或者是几十万,这种方式显然不可取。
2、bgsave触发方式
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体流程如下:
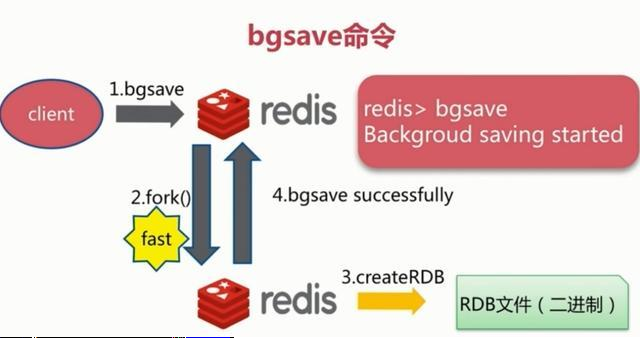
具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
3.自动保存方式(通常都是这个)
自动触发是由我们的配置文件来完成的。在redis.conf配置文件中,里面有如下配置,我们可以去设置:
①save:这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
默认如下配置:
- 表示900 秒内如果至少有 1 个 key 的值变化,则保存save 900 1
- 表示300 秒内如果至少有 10 个 key 的值变化,则保存save 300 10
- 表示60 秒内如果至少有 10000 个 key 的值变化,则保存save 60 10000
满足保存策略或者正常关闭 shutdown都会触发rdb持久化
不需要持久化,那么你可以注释掉所有的 save 行来停用保存功能。
②stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
③rdbcompression ;默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。
④rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
⑤dbfilename :设置快照的文件名,默认是 dump.rdb
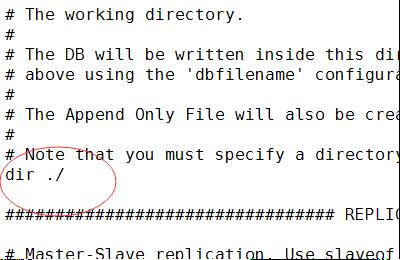
⑥dir:设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名,默认是当前文件夹下
save配置

文件名默认是dump.rdb
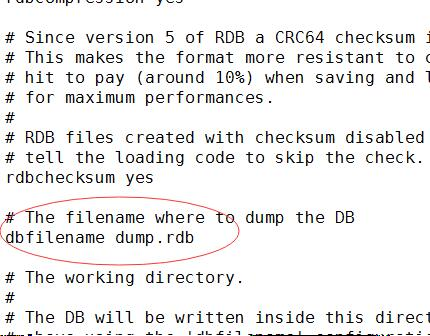
存储路径是当前目录
优劣势
优势:只有一个文件,每隔一个时间段,可以归档为一个文件(默认是redis目录下的dump.rdb),方便压缩转移(就一个文件)
劣势:如果宕机,数据损失比较大,因为它是每隔一个时间段进行持久化操作的。也就是积攒的数据比较多,一旦懵逼,就彻底懵逼了
附:save命令与bgsave命令对比
aof方式
以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录,服务器启动后就构建数据库,重新写入指令。
flushdb属于删除指令,也会记录到aof中,进行数据恢复前先将aof文件中的flushdb指令删掉,之后*和$会自动删除。
bgrewriteaof指令:使用重写(优化指令集)来减轻体积
redis-check-aof --fix appendonly.aof 故障恢复


默认关闭aof方式,默认文件名appendonly.aof
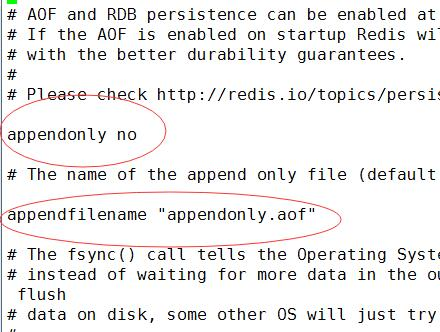
append三种策略:
- always 是只要发生修改,立即同步 (推荐实用 安全性最高)
- everysec 是每秒同步一次
- no 是不同步
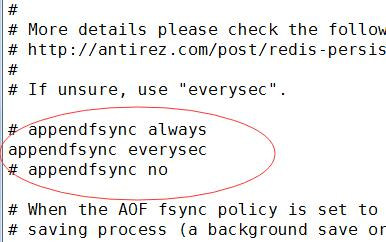
重写aof
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似
何时重写

优劣势
优势:安全性相对RDB方式高很多;
劣势:效率相对RDB方式低很多;
(同样可以拷贝文件到别的地方,重启redis便可以加载数据)
两种方式对比
RDB文件小,启动效率更高,只需要fork出子进程,极大的避免了服务进程的IO操作,性能更高,但是宕机会使还没来得及做持久化的数据丢失,无法保证数据的高完整性
AOF相比之下数据安全更高,写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容,格式清晰,易于理解
如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题
分析对比两种方式并做了测试后,发现这是两种不同风格的持久化方式。那么应该如何选择呢?
• 对于企业级的中大型应用,如果不想牺牲数据完整性但是又希望保持高效率,那么你应该同时使用 RDB 和 AOF 两种方式。
• 如果你不打算耗费精力在这个地方,只需要保证数据完整性,那么优先考虑使用 AOF 方式。
• RDB 方式非常适合大规模的数据恢复,如果业务对数据完整性和一致性要求不高,RDB 是很好的选择。
Redis事务
Redis 可以通过 MULTI,EXEC,DISCARD 和 WATCH 等命令来实现事务(transaction)功能。
使⽤ MULTI命令后可以输⼊多个命令。Redis不会⽴即执⾏这些命令,⽽是将它们放到队列,当
调⽤了EXEC命令将执⾏所有命令。Redis官⽹相关介绍 https://redis.io/topics/transactions 如下:
但是,Redis 的事务和我们平时理解的关系型数据库的事务不同。我们知道事务具有四⼤特性:
1.原⼦性,2. 隔离性,3. 持久性,4. ⼀致性。1. 原⼦性(Atomicity): 事务是最⼩的执⾏单位,不允许分割。事务的原⼦性确保动作要么全部完成,要么完全不起作⽤;2. 隔离性(Isolation): 并发访问数据库时,⼀个⽤户的事务不被其他事务所⼲扰,各并发事务之间数据库是独⽴的;3. 持久性(Durability): ⼀个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发⽣故障也不应该对其有任何影响。4. ⼀致性(Consistency): 执⾏事务前后,数据保持⼀致,多个事务对同⼀个数据读取的结果是相同的;Redis 是不⽀持 roll back 的,因⽽不满⾜原⼦性的(⽽且不满⾜持久性)。
Redis官⽹也解释了⾃⼰为啥不⽀持回滚。简单来说就是Redis开发者们觉得没必要⽀持回滚,这
样更简单便捷并且性能更好。Redis开发者觉得即使命令执⾏错误也应该在开发过程中就被发现
⽽不是⽣产过程中。Redis事务提供了⼀种将多个命令请求打包的功能。然后,再按顺序执⾏打包的所有命令,并且不会被中途打断
--参考javaGuide

Redis三大缓存问题
缓存穿透
访问的数据既不在缓存中,也不想在数据库中,大量请求直接访问数据库
解决措施:
1.做好参数校验,尽量过滤掉无效的请求
2.缓存空值或缺省值 使请求走缓存 从结果上处理,既然缺少对应缓存,那就加上 ,但是会导致有大量的无用缓存
3.使用布隆过滤器 判断请求值是否有效 从请求上参数上,无效的直接过滤掉
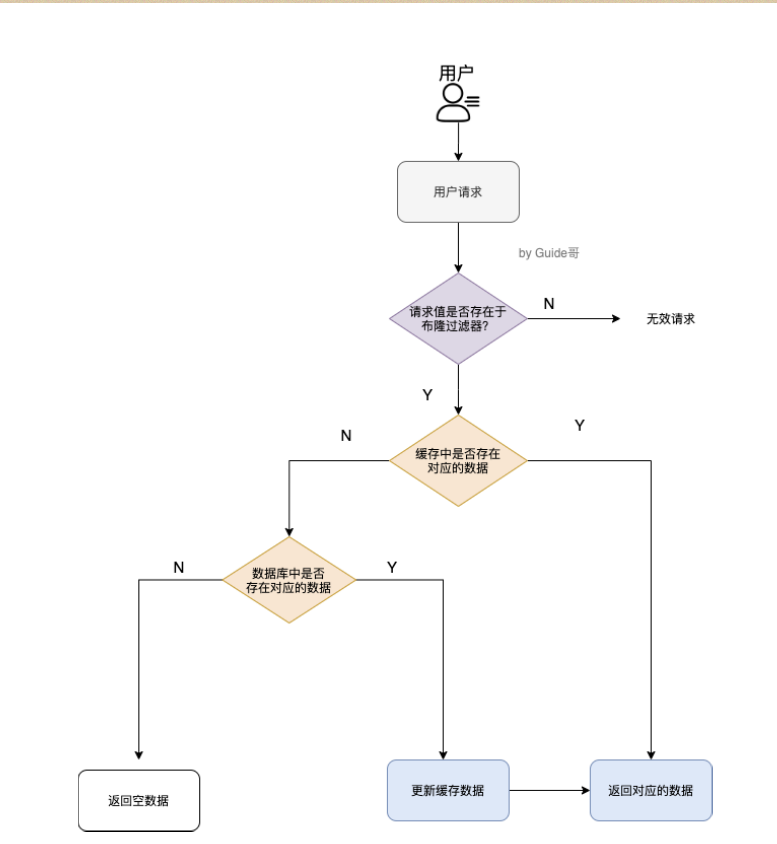
具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当⽤户请求过来,先判断⽤户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户 从输入角度上做限制
端,存在的话才会⾛下⾯的流程。
布隆过滤器原理
布隆过滤器是一个高空间利用率的概率性数据结构,由二进制向量(即位数组)和一系列随机映射函数(即哈希函数)两部分组成。布隆过滤器使用exists()来判断某个元素是否存在于自身结构中
过程
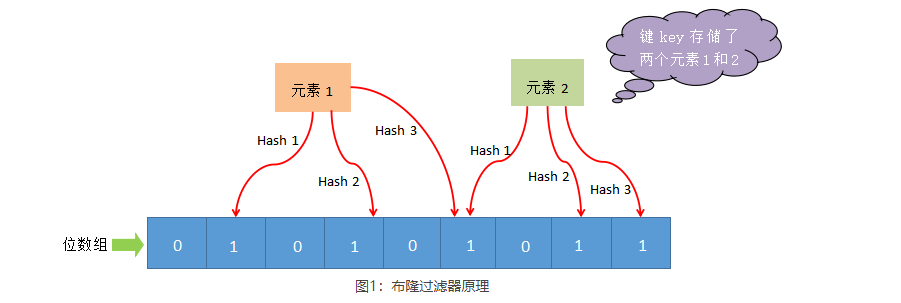
布隆过滤器主要由位数组和一系列 hash 函数构成,其中位数组的初始状态都为 0。
下面对布隆过滤器工作流程做简单描述,如下图所示:
1.添加数据:
当使用布隆过滤器添加 key 时,会使用不同的 hash 函数对 key 存储的元素值进行哈希计算,从而会得到多个哈希值。根据哈希值计算出一个整数索引值,将该索引值与位数组长度做取余运算,最终得到一个位数组位置,并将该位置的值变为 1。每个 hash 函数都会计算出一个不同的位置,然后把数组中与之对应的位置变为 1。通过上述过程就完成了元素添加(add)操作。
2.判定元素是否存在
当我们需要判断一个元素是否存时,其流程如下:首先对给定元素再次执行哈希计算,得到与添加元素时相同的位数组位置,判断所得位置是否都为 1,如果其中有一个为 0,那么说明元素不存在,若都为 1,则说明元素有可能存在。
3) 为什么是可能“存在”
您可能会问,为什么是有可能存在?其实原因很简单,那些被置为 1 的位置也可能是由于其他元素的操作而改变的(相同的hash值)。比如,元素1 和 元素2,这两个元素同时将一个位置变为了 1(图1所示)。在这种情况下,我们就不能判定“元素 1”一定存在,这是布隆过滤器存在误判的根本原因。
=》都为1,大概率存在,有不为1,一定不存在
缓存击穿
针对在数据库中存在的某个热点数据,突然缓存失效,大量请求进入数据库,一般是由于缓存中的key过期导致的。
两种解决方法:
1.改变过期时间
设置热点数据永不过期。
2.分布式锁
采用分布式锁的方法,重新设计缓存的使用方式,过程如下:
上锁:当我们通过 key 去查询数据时,首先查询缓存,如果没有,就通过分布式锁进行加锁,第一个获取锁的进程进入后端数据库查询,并将查询结果缓到Redis 中。
解锁:当其他进程发现锁被某个进程占用时,就进入等待状态,直至解锁后,其余进程再依次访问被缓存的 key。
缓存雪崩
缓存在同⼀时间⼤⾯积的失效,后⾯的请求都直接落到了数据库上,造成数据库短时间内承受⼤量请求
解决办法
针对redis服务不可用
- 采⽤ Redis 集群,避免单机出现问题整个缓存服务都没办法使⽤。
- 限流,避免同时处理⼤量的请求。
针对热点的缓存失效
- 设置不同的失效时间⽐如随机设置缓存的失效时间。 =》避免在同一时间段内大量失效
- 缓存永不失效。 =》热点缓存直接不失效
如何保证缓存和数据库数据的一致性?
可以使用旁路缓存模式:更新DB后直接删除缓存。
如果更新成功,但是删除缓存失败的话,解决措施:
1.缓存失效时间变短(不推荐,治标不治本) :我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
2.增加cache更新重试机制(常⽤): 如果 cache 服务当前不可⽤导致缓存删除失败的话,我们就隔⼀段时间进⾏重试,重试次数可以⾃⼰定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存⼊队列中,等缓存服务可⽤之后,再将 缓存中对应的 key 删除即可
--参考javaGuide文章
缓存双写一致性问题
--引用尚硅谷redis
没有绝对的数据一致
先更新数据库,再更新缓存
- 写了mysql,会写redis异常,导致数据不一致
- A更新mysql B更新Mysql B更新缓存 A更新缓存 mysql与redis数据不一致
先更新缓存,再更新数据库
- 不推荐,mysql应该作为基准数据
- A更新redis B更新redis B更新mysql A更新mysql =》 redisB mysqlA 数据不一致
先删除缓存,再更新数据库
A删除缓存,更新myslq,A未更新完成,B就读取,发现缓存没有,查mysql(A还未完成更新,此时还是旧值),将旧值写入缓存=》mysqlA 缓存B 数据不一致
解决措施 延时双删
=》需要在第二次删除前,线程B能够读取玩数据库数据且更新缓存 即 要等B操作完 =》该同步淘汰策略降低了吞吐量
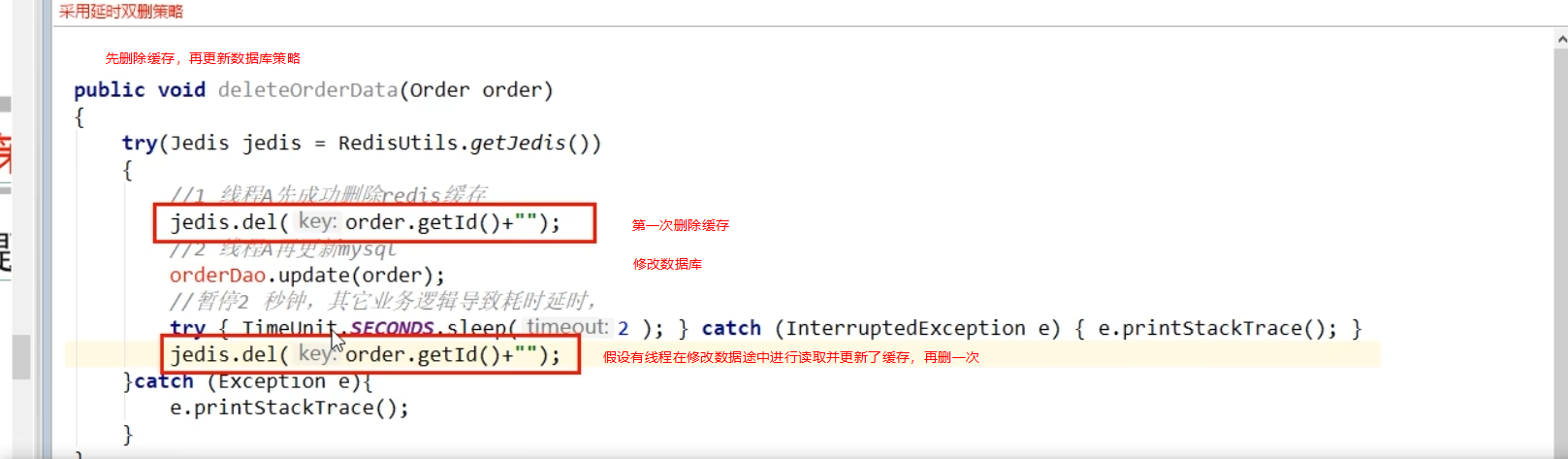
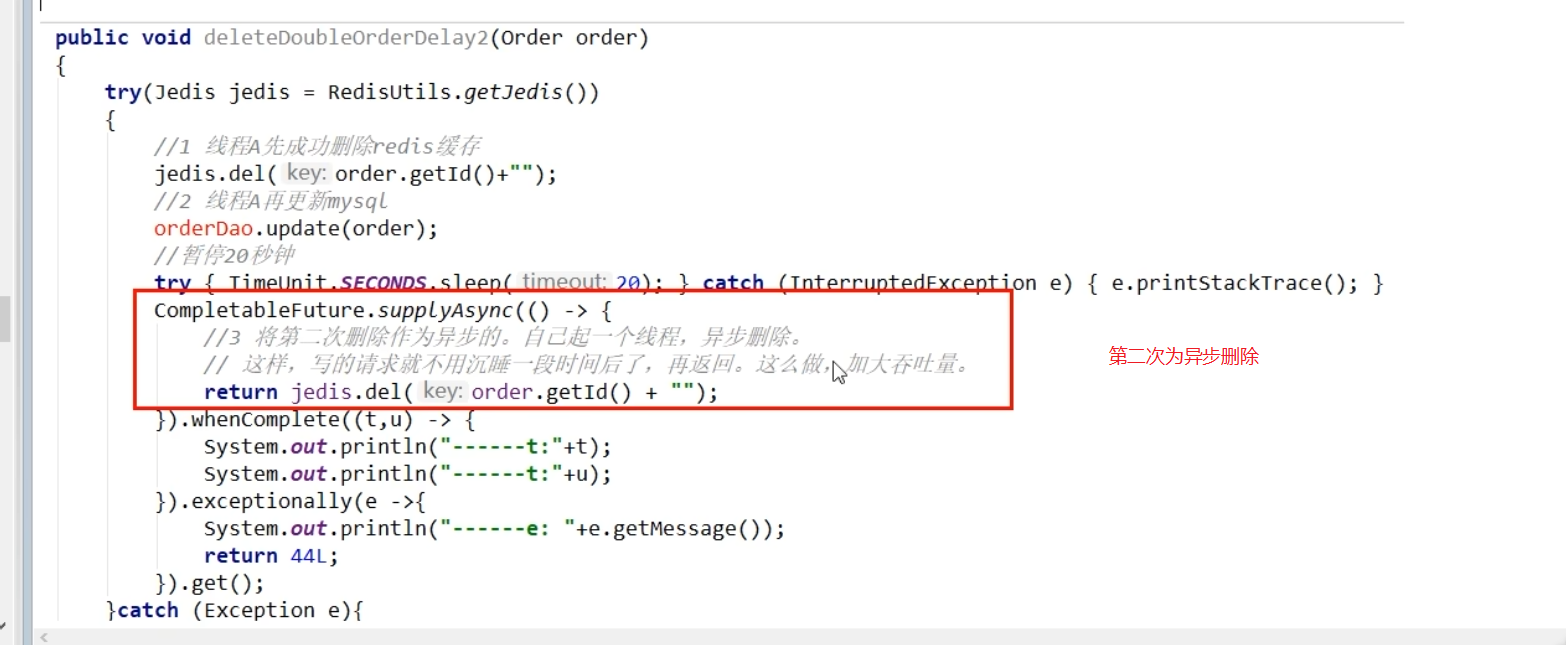
=》改进,第二次删除用异步删除,等线程A写完,异步删除缓存
=》看门狗
先更新数据库,再删除缓存(相对而言更好一些)
相关思想运用 微软云、阿里巴巴canal
异常问题

解决方案
绝对的数据一致不可能实现,只能干到最终一致性
在mysql中有个现成的中间件叫canal,可以完成 订阅binlog日志功能
兜底方案:通过binlog拿到操作的数据,放入消息中间件,重试删除缓存或者更新数据库
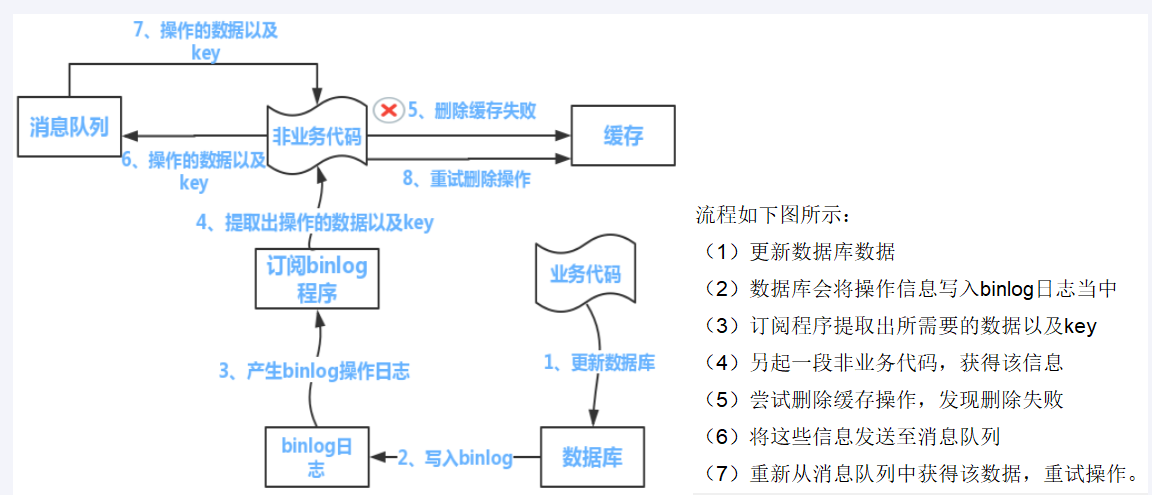
1.可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中
2.当程序没有能够成功地删除缓存值或者更新数据库时,可以从消息队列中重新读取这些值,然后再次进行删除或者更新
3.如果能够成功地删除或者更新,就把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了,否则还需要再次进行重试
4.如果重试超过一定次数还是没有成功,我们就需要向业务层发送报错信息,通知运维人员
方案选择
优先选用先更新数据库,再删除缓存的方案
- 先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力导致打满myslq
- 如果业务应用中读取数据和写缓存时间不好估算,那么延迟双删的等待时间就不好设置
使用先更新数据库,再删除缓存的方案前提下,
如果业务层要求必须读取一致性的数据,那么在更新数据库时,先在redis缓存客户端暂停并发读请求,等待数据库更新完成,缓存值删除后,再读取数据,从而保证数据一致性,只是理论可以达到的效果,但实际上不推荐,因为真实生产环境中,分布式下很难做到实时一致性,一般都是最终一致性
总结

作者: deity-night
出处: https://www.cnblogs.com/deity-night/
关于作者:码农
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 原文链接 如有问题, 可邮件(***@163.com)咨询.
