



Mysql
引入
MySQL是一种关系型数据库管理系统,它将数据保存在不同的表中
(1)MySQL数据库是用C和C++语言编写的,并且使用了多种编辑器进行测试,以保证源码的可移植性
(2)支持多个操作系统例如:Windows、Linux、Mac OS等等
(3)支持多线程,可以充分的利用CPU资源
(4)有多种列类型
(5)MySQL优化了SQL算法,有效的提高了查询速度
(6)支持事务
(7)它能够作为一个单独的应用程序应用在客户端服务器网络环境中,也可以作为一个库嵌入到其他的软件中并提供多种语言支持
数据类型
参考菜鸟:https://www.runoob.com/mysql/mysql-data-types.html
常用的有;Varchar,int,DATE,TIMESTAMP,BIGINT
mysql中字符串用单引号还是双引号?
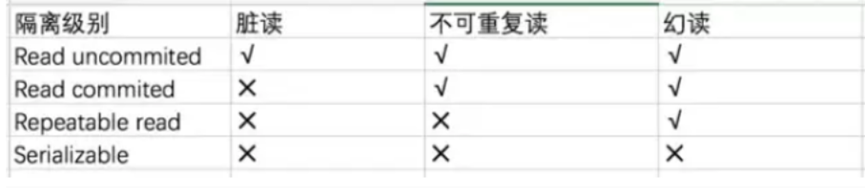
都可以,sql mode 叫做:ANSI_QUOTES 。这个 ANSI_QUOTES 开启后会把 双引号当作 ``。所以建议使用单引号来引用字符串。Mysql隔离级别
用来限定事务内外的哪些改变是可见的,哪些是不可见的
Read Uncommitted(读未提交)
Read Committed(读取提交)
Repeatable Read(可重读)默认
Serializable(可串行化)
一般使用Read COmmitted (读已提交)
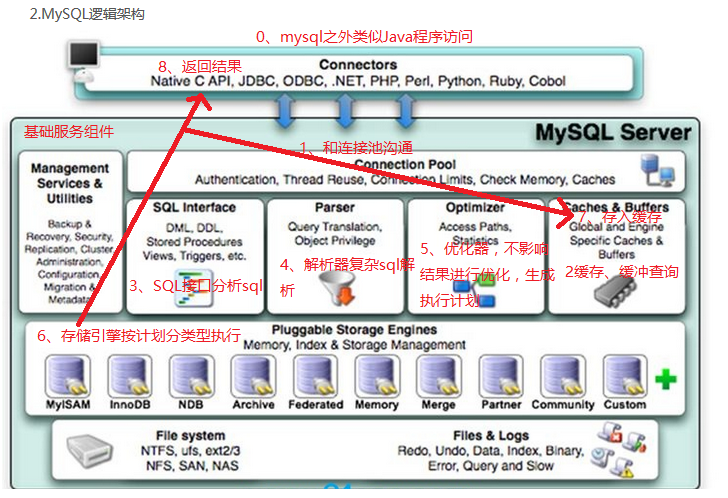
Mysql底层架构
存储引擎
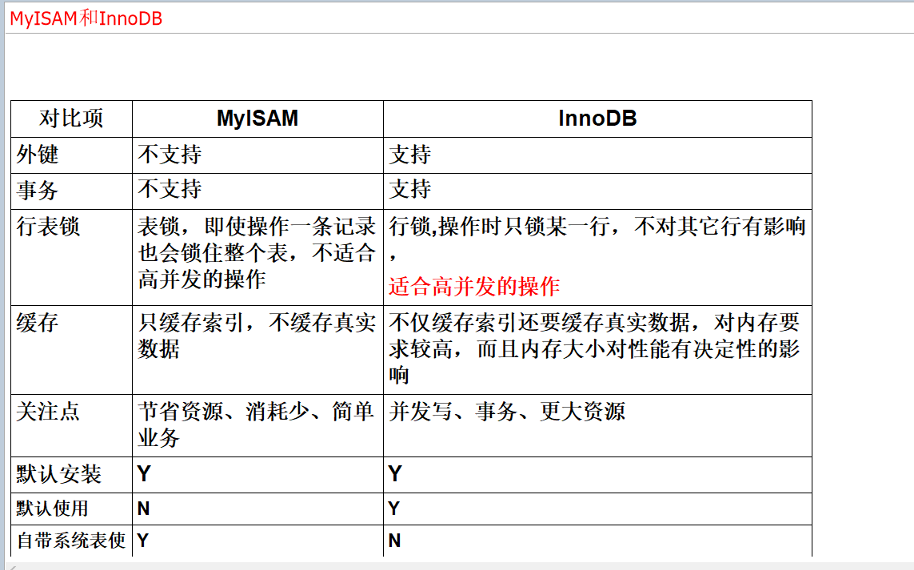
1、InnoDB存储引擎
InnoDB是MySQL的默认事务型引擎,它被设计用来处理大量的短期(short-lived)事务。除非有非常特别的原因需要使用其他的存储引擎,否则应该优先考虑InnoDB引擎。
2、MyISAM存储引擎
MyISAM提供了大量的特性,包括全文索引、压缩、空间函数(GIS)等,但MyISAM不支持事务和行级锁,有一个毫无疑问的缺陷就是崩溃后无法安全恢复。
3、Archive引擎
Archive档案存储引擎只支持INSERT和SELECT操作,在MySQL5.1之前不支持索引。
Archive表适合日志和数据采集类应用。
根据英文的测试结论来看,Archive表比MyISAM表要小大约75%,比支持事务处理的InnoDB表小大约83%。
4、Blackhole引擎
Blackhole引擎没有实现任何存储机制,它会丢弃所有插入的数据,不做任何保存。但服务器会记录Blackhole表的日志,所以可以用于复制数据到备库,或者简单地记录到日志。但这种应用方式会碰到很多问题,因此并不推荐。
5、CSV引擎
CSV引擎可以将普通的CSV文件作为MySQL的表来处理,但不支持索引。
CSV引擎可以作为一种数据交换的机制,非常有用。
CSV存储的数据直接可以在操作系统里,用文本编辑器,或者excel读取。
行内以逗号隔开,行外以换行符隔开
6、Memory引擎
如果需要快速地访问数据,并且这些数据不会被修改,重启以后丢失也没有关系(放在内存中的),那么使用Memory表是非常有用。Memory表至少比MyISAM表要快一个数量级。
类似redis等NoSQL,所以,被NoSQL替代了
7、Federated引擎
联合引擎
Federated引擎是访问其他MySQL服务器的一个代理,尽管该引擎看起来提供了一种很好的跨服务器的灵活性,但也经常带来问题(效率太低),因此默认是禁用的。
InnoDB和MyISAM对比
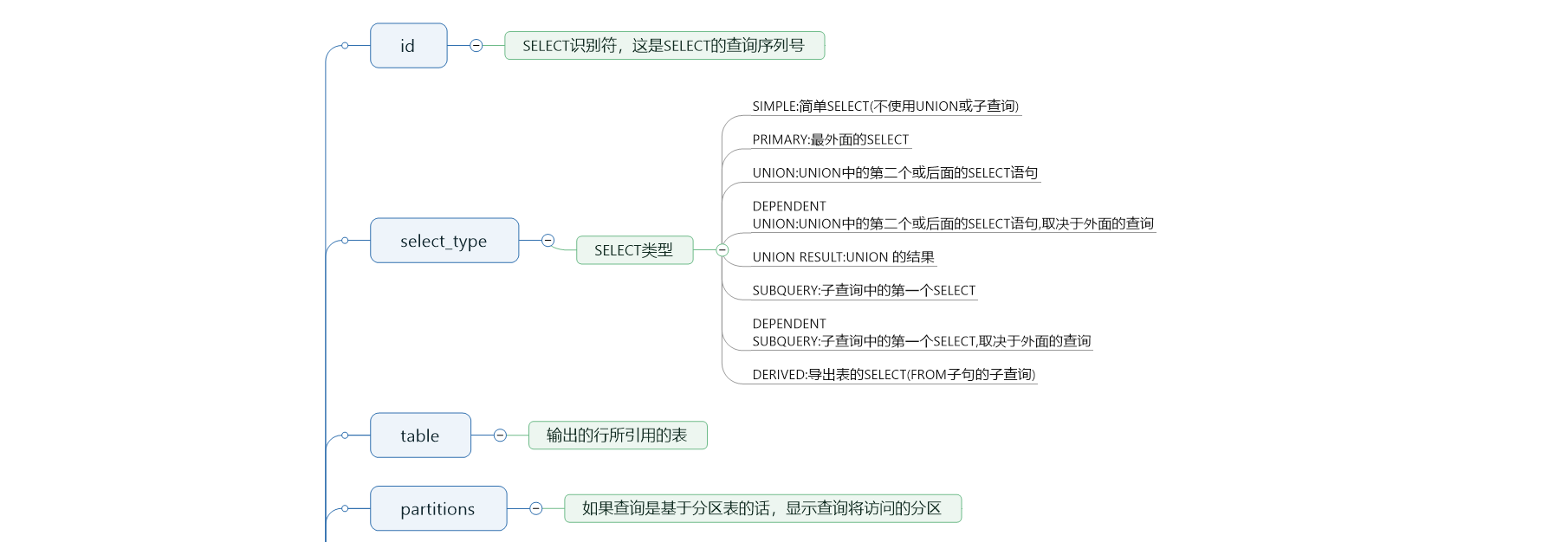
Explain&执行计划
参考
https://blog.csdn.net/BASK2311/article/details/127472235
https://mp.weixin.qq.com/s?__biz=MzA3MTg4NjY4Mw==&mid=2457328508&idx=2&sn=0db2e532d2b2612ba1c4398af17e3d8c&chksm=88a5c948bfd2405e9065b02e8455e6e9603591952480097dea86cdf4a0142ce575fe2487196a&scene=27
什么是Msqy执行计划
优化器在不影响结果的前提下会对sql进行优化,生成最终的执行计划,交给存储引擎执行
一条sql的好坏可以通过执行计划看出,执行计划提供了各种查询类型与级别,方便对sql进行性能分析
怎么查看
explain可以模拟优化器执行sql查询语句,从而知道如何处理的sql,即sql的执行计划。
使用;explain+待执行的sql

执行计划解析
参考:
https://blog.csdn.net/qq_37148705/article/details/126991190
https://mp.weixin.qq.com/s?__biz=MzA3MTg4NjY4Mw==&mid=2457328508&idx=2&sn=0db2e532d2b2612ba1c4398af17e3d8c&chksm=88a5c948bfd2405e9065b02e8455e6e9603591952480097dea86cdf4a0142ce575fe2487196a&scene=27


时间类型

Mysql时间类型转字符串
to_char(time,'YYYY-MM-DD hh24:mi:ss') 24h制 to_char(time,'YYYY-MM-DD') to_char(time,'YYYY-MM-DD hh:mi:ss')
表示分钟: mi
表示小时:hh 12进制,hh24 24小时制
与java不同,mm表示月
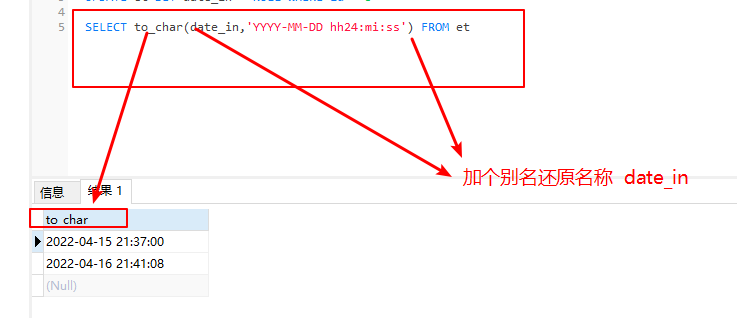
附:java中日期用字符表示
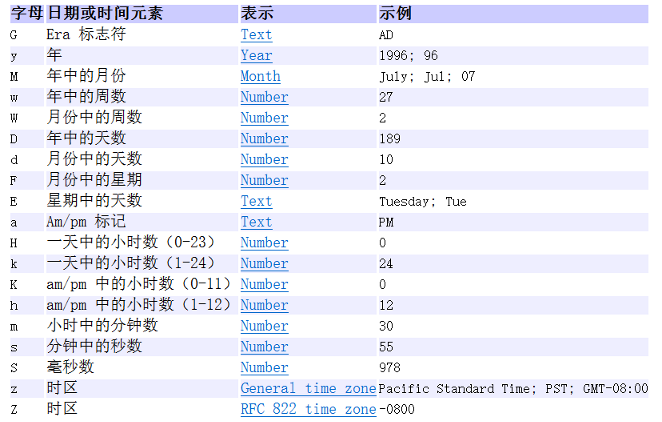
Mysql数据类型与Java类型对应
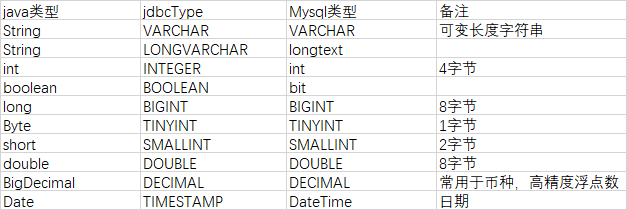
JOIN图释
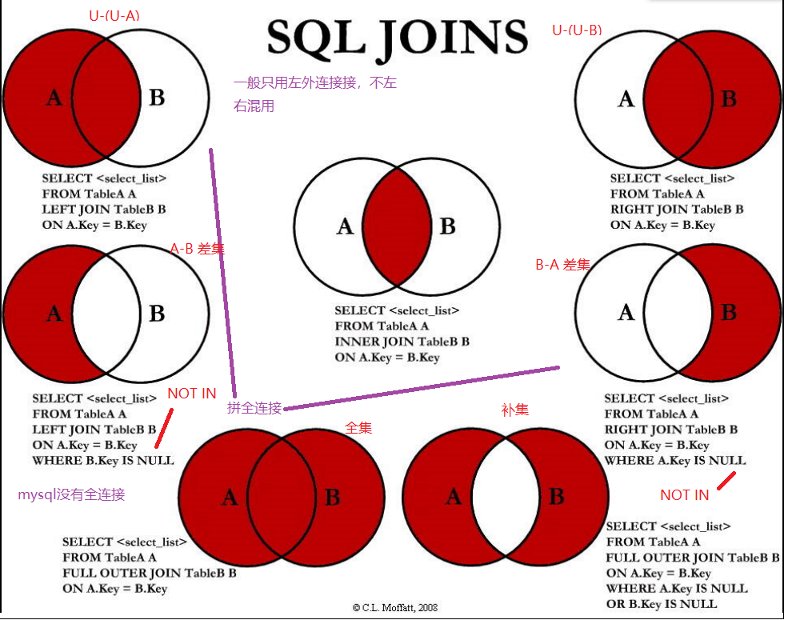
注:左外连接,在 on 后面只能对右表添加单独的字段限制,对左表添加无效,如 A left join B on A.xx= B.xx and B.? = 1
索引
索引(Index)是帮助MySQL高效获取数据的数据结构
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上
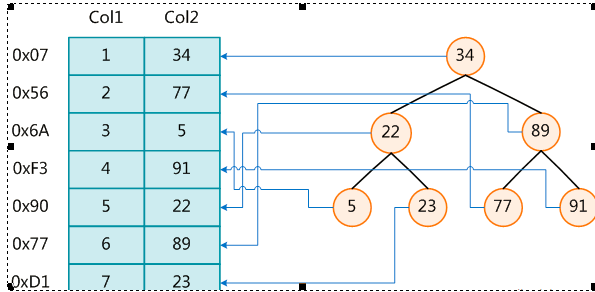
存储位置:
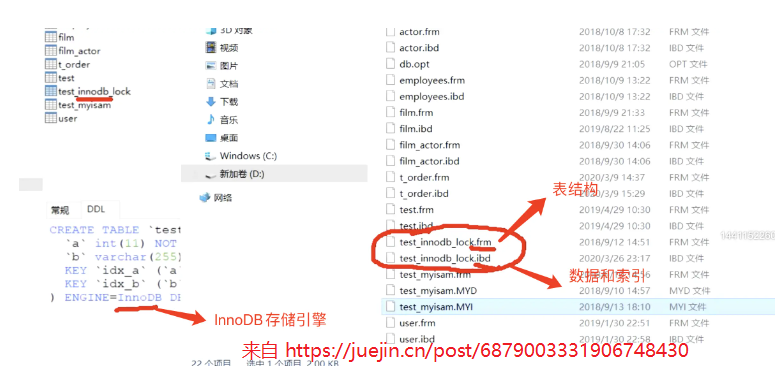
优势与劣势
优势:
包含特定算法,提高了检索效率,降低数据库的IO成本
通过索引列对数据排序,降低了排序成本,降低了cpu消耗
劣势:
同时,因为使用了索引,插入,更新,删除不仅要更改表的数据,还要更新索引,这就使增删改变慢了
索引也是一张表,保存了主键与索引字段,指向实体表的数据记录,也要占用存储空间,而且索引一般比较大
哪些情况需要建立索引
主键自动建立唯一索引
频繁作为查询条件的字段应该创建索引
查询中与其它表关联的字段,外键关系建立索引.
单键/组合索引的选择问题,组合索引性价比更高
查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
查询中统计或者分组字段
哪些情况不需要索引
表记录太少
经常增删改的表或者字段
Where条件里用不到的字段不创建索引
过滤性不好的不适合建索引
索引分类
参考:
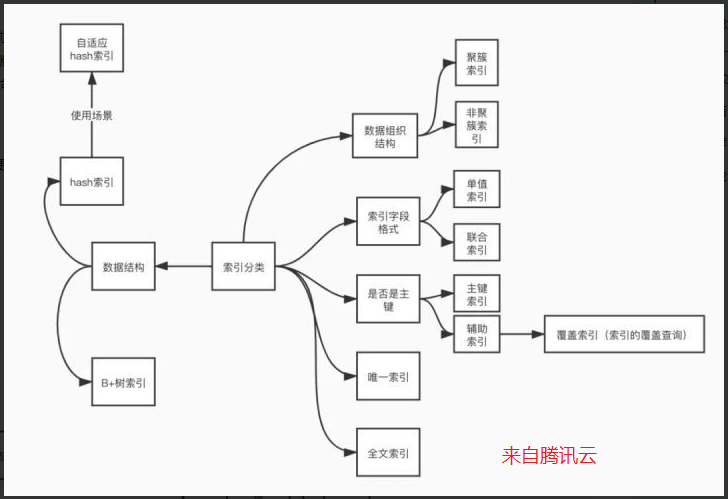
逻辑分类
• 主键索引:一张表只能有一个主键索引,不允许重复、不允许为 NULL;
• 唯一索引:数据列不允许重复,允许为 NULL 值,一张表可有多个唯一索引,但是一个唯一索引只能包含一列,比如身份证号码、卡号等都可以作为唯一索引;
• 普通索引:一张表可以创建多个普通索引,一个普通索引可以包含多个字段,允许数据重复,允许 NULL 值插入;
• 组合索引:指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合
• 全文索引:让搜索关键词更高效的一种索引
物理分类
• 聚簇索引:
一般是表中的主键索引,如果表中没有显示指定主键,则会选择表中的第一个不允许为 NULL 的唯一索引,
如果还是没有的话,就采用 Innodb 存储引擎为每行数据内置的 6 字节 ROWID 作为聚集索引。
每张表只有一个聚集索引,因为聚集索引的键值的逻辑顺序决定了表中相应行的物理顺序。
聚簇索引的顺序就是数据的物理存储顺序
聚集索引在精确查找和范围查找方面有良好的性能表现(相比于普通索引和全表扫描),
聚集索引就显得弥足珍贵,聚集索引选择还是要慎重的(一般不会让没有语义的自增 id 充当聚集索引);
• 非聚簇索引:该索引中索引的逻辑顺序与磁盘上数据行的物理存储顺序不同(非主键的那一列),一个表中可以拥有多个非聚集索引
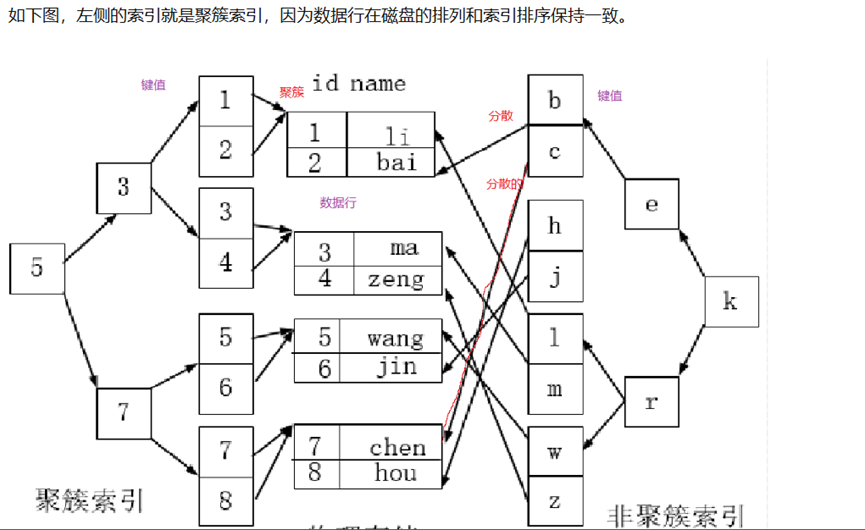
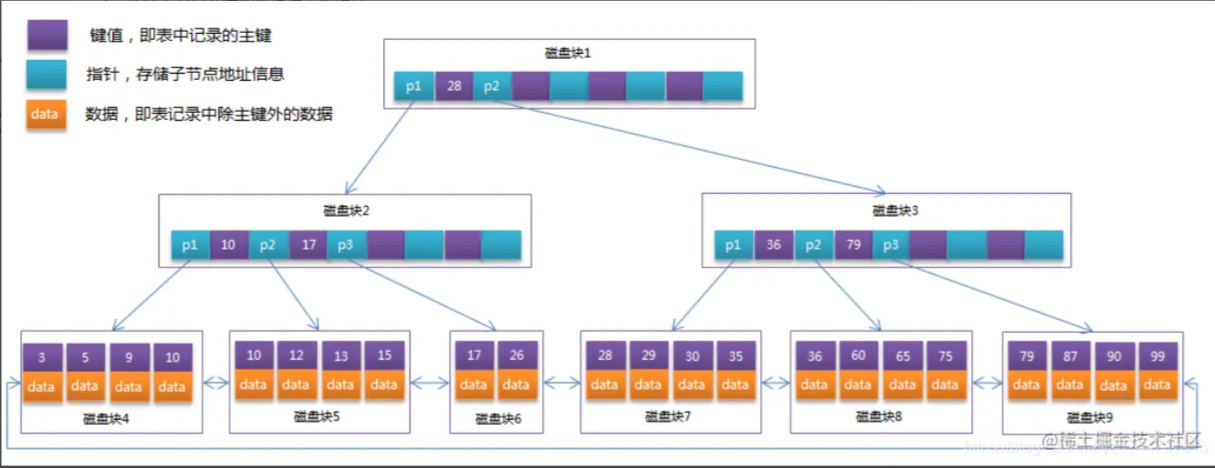
Mysql索引结构
为什么不用普通二叉查找树
索引容易形成单链 无意义
为什么不采用红黑树
B和B+Tree比较
B+Tree非叶子节点不存储数据,在相同的数据量下,B+Tree更矮壮
B+Tree叶子节点之间组成一个链表,方便遍历查询
B+Tree是B-Tree的变种,B-Tree能解决的问题,B+Tree也能够解决(降低树的高度,增大节点存储数据量)
B+Tree扫库和扫表能力更强。如果我们要根据索引去进行数据表的扫描,对B-Tree进行扫描,需要把整棵树遍历一遍,而B+TREE只需要遍历他的所有叶子节点即可(叶子节点之间有引用)。
B+Tree磁盘读写能力更强。他的根节点和支节点不保存数据区,所以根节点和支节点同样大小的情况下,保存的关键字要比B-Tree要多。所以,B+Tree读写一次磁盘加载的关键字比B-Tree更多。
B+Tree排序能力更强。上面的图中可以看出,B+Tree天然具有排序功能。
B+Tree查询性能稳定。B+Tree数据只保存在叶子节点,每次查询数据,查询IO次数一定是稳定的。当然这个每个人的理解都不同,因为在B-Tree如果根节点命中直接返回,确实效率更高。
作者:ailvyuanj
链接:https://juejin.cn/post/7196943016392638524
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
B-Tree

B+Tree
Msyql常见索引失效场景
违背了最左匹配法则
对索引列做算数、函数操作
索引中范围条件右边的列不走索引
使用不等于! 或者<>
is Not null 不走索引,但是is Null走索引
like模糊匹配以通配符开头%abc
字符串不加单引号
最左匹配原则
按创建索引时指定的索引顺序走索引,从最开始那个索引列开始匹配,中间断开后不再走索引
SQL调优
通过EXPLAIN可以模拟优化器对sql进行性能分析,主要看id,type,rows这些,看是否使用了索引,用到了哪些索引?是不是进行了全表扫描
sql优化策略:
- 避免不走索引的场景
- SELECT语句其他优化
- 增删改 DML 语句优化
- 查询条件优化
- 建表优化
语法上面的优化
- 对查询进行优化的时候,应尽量避免全表扫描 只查需要的列
- 应尽量避免在 where 子句中对字段进行 null 值判断,进行计算
- 应尽量避免在 where 子句中使用 or 来连接条件
- 对查询频繁的列建立索引
- 对排序的列建立索引
- in集合中匹配数量不超过100
走了索引还是查询慢
走了索引还是慢,一般来说是数据量是在是太大了
可以考虑能不能把“旧”数据删除
能不能在查询前走一层缓存,走缓存的话,又要看业务能不能忍受读取的【非真正实时】的数据(毕竟Redis和MySQL的数据⼀致性需要保证)
如果查询条件相对复杂且多变的话(涉及各种group by 和sum),那⾛缓存也不是⼀种好的办法,维护起来就不⽅便了...
再看是不是有【字符串】检索的场景导致查询效率低,如果是的话,可以考虑把表的数据导入致ElasticSerach类的搜索引擎,后续的线上查询直接走ElasticSearch
Mysql->ElasticSearch需要有对应的同步程序(⼀般就是监听MySQL的binlog,解析binlog后导⼊到Elasticsearch)
如果还不是的话,那考虑要不要根据查询条件的维度,做相对应的聚合表,线上的请求就查询聚合表的数据,不⾛原表
大致上是空间换时间
--java3y《对线面试官》

写性能瓶颈怎么办
先看架构是啥样的,如果是单库的话,可以考虑升级主从架构,实现读写分离
主库接收写请求,从库接收读请求。从库的数据由主库发送的binlog进⽽更新,实现主从数据⼀致(在⼀般场景下,主从的数据是通过异步来保证最终⼀致性的)
如果在主从架构下,读写仍存在瓶颈,那就要考虑是否要分库分表了
--java3y《对线面试官》
Mysql主从复制
默认支持主从复制,可以一主一从,也可以一主多从
异步复制,基于binlog,从主库获取二进制日志,解析,然后执行sql语句进行复制
记录了所有DDL与DML,但是不包括数据库查询语句
binlog提供容灾能力,mysql默认没有开启该日志
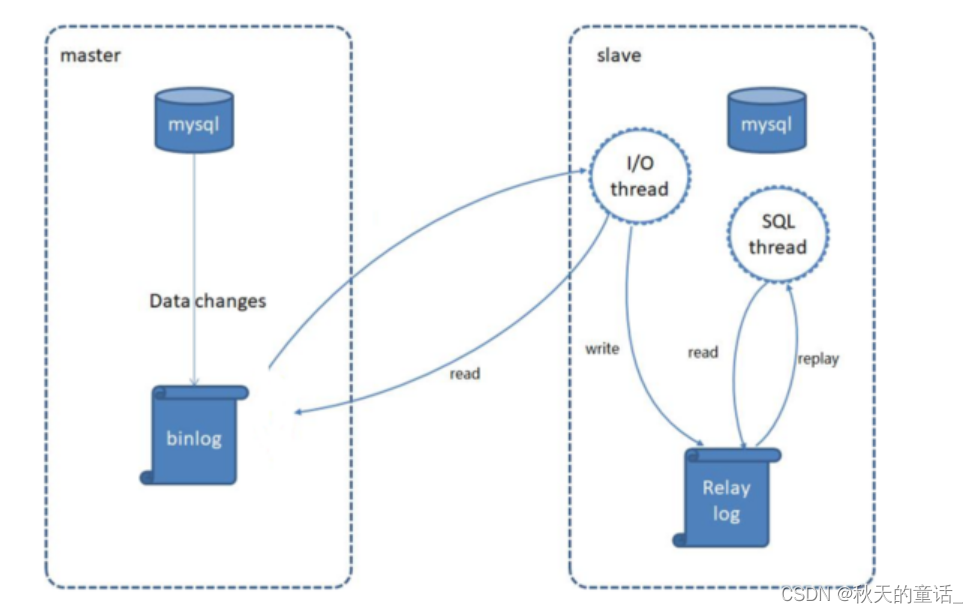
规则
①每个slave只能有一个master。(一对一)
②每个slave只能有一个唯一的服务器ID。
③每个master可以有多个slave。(一对多)
在主从复制过程中,最大的问题就是延时。
大致步骤
①master将改变记录到二进制日志(binary log),这些记录过程叫做二进制日志事件(binary log events)。
②slave将master的binary log events拷贝到中继日志(relay log)。
③slave重做中继日志中的事件,将改变应用到自己的数据库中。MySQL的复制是异步且串行化的。
与Oracle相比
Mysql属于轻量级数据库,小巧,免费(开源的),使用方便。
Oracle:大型数据库软件,收费,支撑体系完善,强大,安全性高(适用于服务器比较强大的单节点或者集群环境)
基本语法
列名不加单引号,字符串才加单引号,但是列名可以加反撇号与敏感字符做区分
对于日期,直接用字符串来写入也可以
update emploee set induction_date= '2023-02-28' where `name`= '老王' ;
查看属性值命令
SHOW STATUS LIKE '%变量名%' ;
Mysql的sql语句分类
主要:
DDL 数据定义语言
在数据库中进行创建或者删除表 ,操作表的结构
DQL 数据查询语言
就是在数据库中进行查询数据表的语言
DML 数据操作语言
就是对数据表中的 数据进行添加,修改,删除,操作表中的数据
DCL 数据控制语言
用来创建数据库用户、控制数据库的 访问权限
DQL相关
基本格式
select [表字段名称|列名]|[*] from 数据表的名称 [where] [查询的条件] [and] [条件1] [group by 分组条件] [having 过滤] [order by 排序] [LIMIT offset ,num 分页]
DML相关
插入
不指定列
**需要与表的列顺序一致 insert into 表名 VALUES (对应的列中的数据)
指定列
insert into 表名 (列名1,列名2) VALUES (列值1,列值2)
对于自动增长的主键,可以不指定,但是要给一个null,不能无视,或者直接写列名

批量插入
分组,用逗号隔开
INSERT INTO [表名]([列名],[列名]) VALUES ([列值],[列值])), ([列值],[列值])), ([列值],[列值]));
1 INSERT INTO 2 items(name,city,price,number,picture) 3 VALUES 4 ('耐克运动鞋','广州',500,1000,'003.jpg'), 5 ('耐克运动鞋2','广州2',500,1000,'002.jpg');
注意
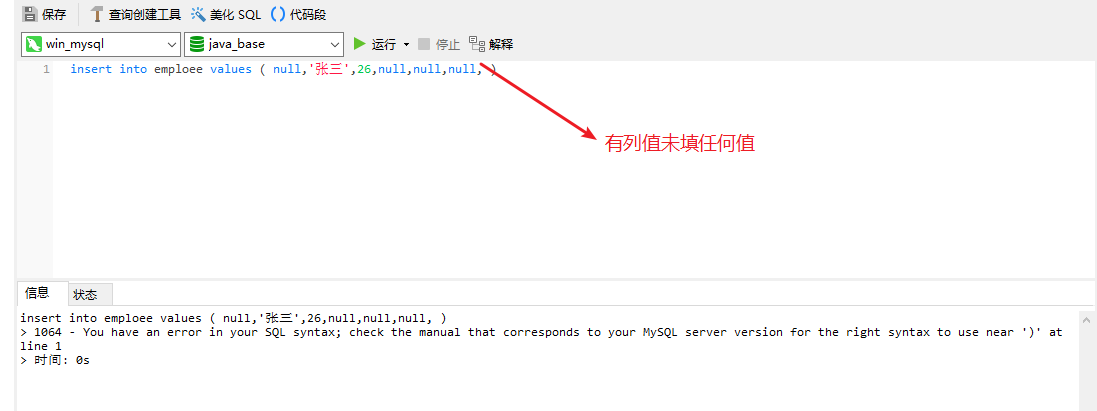
1.插入时,valuse后面的值不能不填,没有就给null,不然会sql报错
2.字符串建议用单引号,虽然双引号也可以,但是其实也是mysql转为了单引号
3.自动增长的主键可以不指定值,直接填null或者主键名都可以,起码给个null(同mybatis中使用)
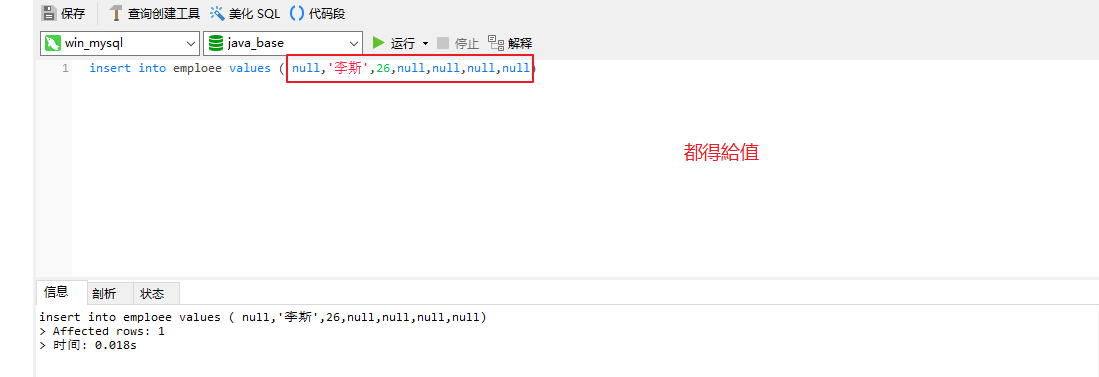
修改
一定要带上条件
普通修改
update 表名 set 列名1=值,列名2=值...... [where 条件 and 条件]
指定具体行进行批量更新/替换
方式一 :replace
表示插入替换数据,当记录中有PrimaryKey,或者unique索引的话,如果数据库已经存在数据,则用新数据替换(先delete再insert),如果没有数据效果则和insert into一样
replace into table values ()
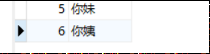
REPLACE INTO mytable VALUES (5,'古力'), (6,'娜扎')

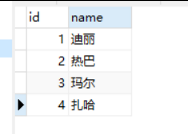
方式二:insert into on duplicate key update
表示插入更新数据,当记录中有PrimaryKey,或者unique索引的话,如果数据库已经存在数据,则用新数据更新(update),如果没有数据效果则和insert into一样
insert into table() values () on duplicate key update
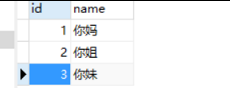
INSERT INTO mytable(id,name) VALUES (1,'迪丽'), (2,'热巴'), (3,'玛尔'), (4,'扎哈') ON DUPLICATE KEY UPDATE id=VALUES(id), name=VALUES(name)
删除
delete from 表名 [where 条件 and 条件]
一定要带上条件
删除尽量不要用foreach,而是获取ID进行批量删除
建索引
参考:https://www.cnblogs.com/bruce1992/p/13958166.html
普通索引
create index index_name on tableName(columnName);
唯一索引
create unique index index_name on tableName(columnName);
组合索引
create index index_name on tableName(column1,column2)
DDL相关
创建表
create table 表名( 列名 列的类型 [相关的约束], 列名 列的类型 [相关的约束], ) 如: CREATE TABLE student( id int , names VARCHAR(1) )
添加字段
语法
alter TABLE tableName add columnName 类型 [约束];
示例
alter TABLE student add phone VARCHAR(11);
修改字段
ALTER TABLE tableName CHANGE COLUMN oldColumnName newColumnName 类型 [约束]
作者: deity-night
出处: https://www.cnblogs.com/deity-night/
关于作者:码农
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 原文链接 如有问题, 可邮件(***@163.com)咨询.

