
数组与Collectoin集合 List / Set
数组
java 数组需要先初始化才能使用,初始化后长度不可变
初始化后未填充的位置自动填充null
初始化方式:静态初始化(直接赋值)、动态初始化(先设定长度,再赋值)
Object数组能存储任意类型数据,包括基本数据类型
1 public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length) 2 代码解释: 3 Object src : 原数组 4 int srcPos : 从元数据的起始位置开始 // 序号从0开始,与下标一致 5 Object dest : 目标数组 6 int destPos : 目标数组的开始起始位置 7 int length : 要copy的数组的长度
Object数组
1 @Test 2 public void objectArrTest() { 3 Object[] arr = new Object[3]; 4 arr[0] = 1; 5 arr[2] = "2"; 6 // [1, null, 2] 7 System.out.println(Arrays.toString(arr)); 8 }
两种初始化方式:
1 /** 2 * java 数组需要先初始化才能使用 3 * 初始化方式:静态初始化(直接赋值)、动态初始化(先设定长度,再赋值) 4 */ 5 @Test 6 public void strArrayTest() { 7 String a = "xxx"; 8 String b = "yyy"; 9 // 静态初始化:同时声明、初始化、赋值 10 String[] strArr = new String[]{a,b}; 11 // [xxx, yyy] 12 System.out.println(Arrays.toString(strArr)); 13 14 15 // 动态初始化:先声明、设定长度,后续再赋值 16 String[] strArr2 = new String[2]; 17 strArr2[1] = "x"; 18 // 数组声明写法2:[]和变量名可以换位置 不推荐 19 String strArr3[] = new String[2]; 20 strArr3[0] = "y"; 21 // [null, x] 未赋值,填充null 22 System.out.println(Arrays.toString(strArr2)); 23 // [y, null] 24 System.out.println(Arrays.toString(strArr3)); 25 }
集合
基本介绍

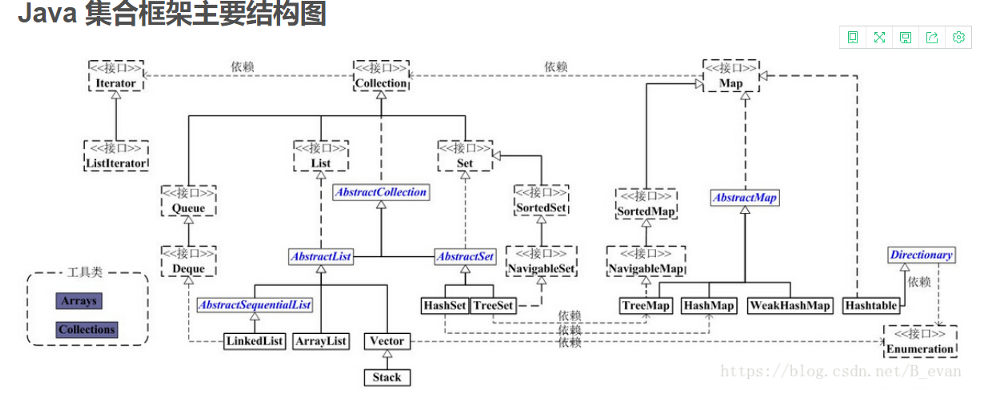
- 集合主要是Collection和Map)两个接口
- Connection称为单列集合,属于单值操作,即每次只能操作一个对象
- Map称为双列集合,每次操作一组对象(k,v) 键值对
Collection
- Collection 表示一组对象,
- 这些对象也称为 collection 的元素。
- 一些 collection 允许有重复的元素,而另一些则不允许。
- 一些 collection 是有序的,而另一些则是无序的。
- JDK 不提供此接口的任何直接 实现:它提供更具体的子接口(如 Set 和 List)实现。
- 此接口通常用来传递 collection,并在需要最大普遍性的地方操作这些 collection。
- Set 无序,不重复
- List 有序,可重复
- AbstractCollection重写了toString()方法,可以直接打印元素
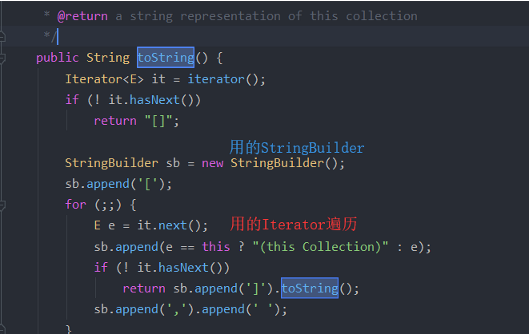
AbstractCollection提供方法概括
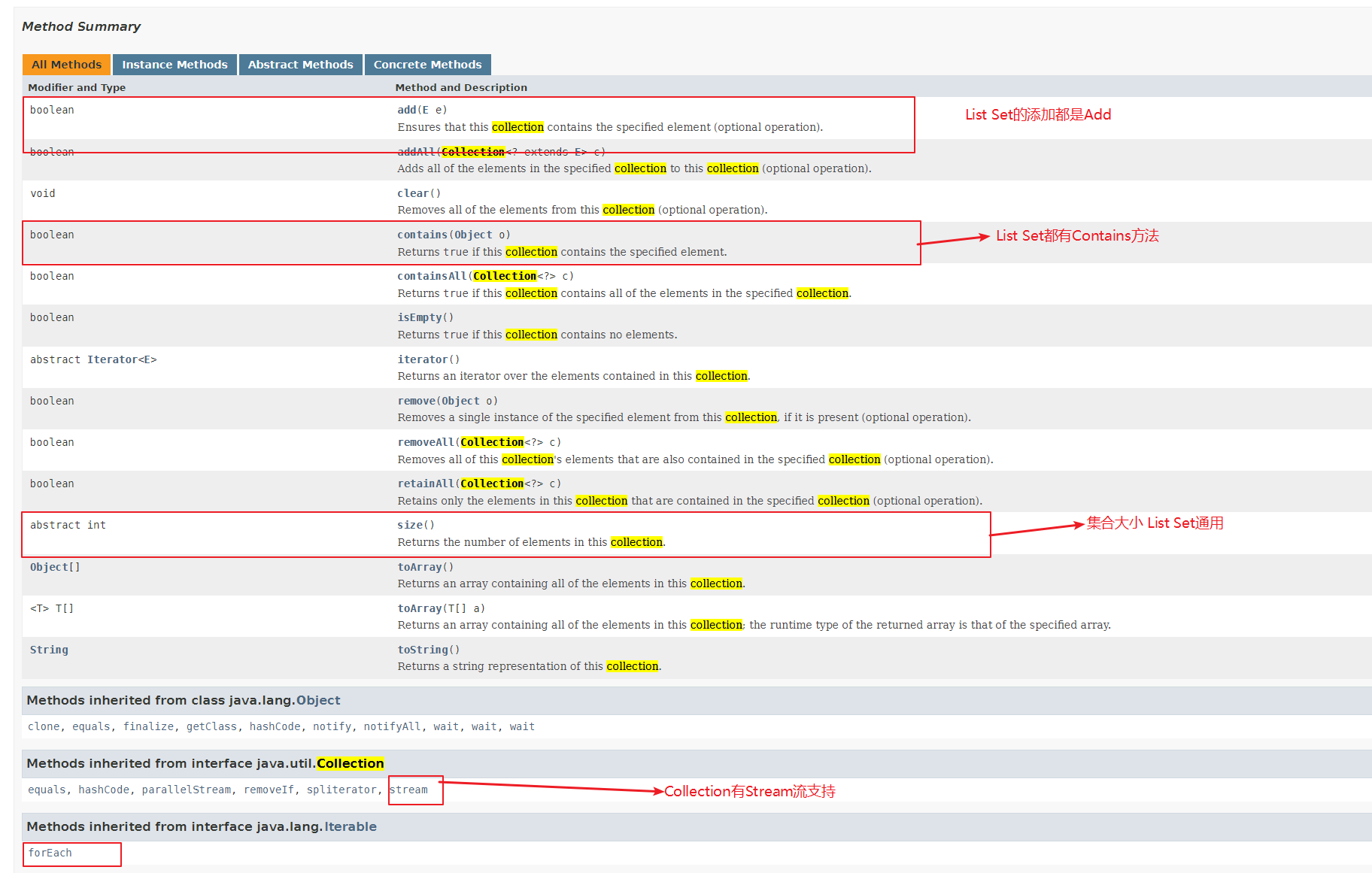
List接口
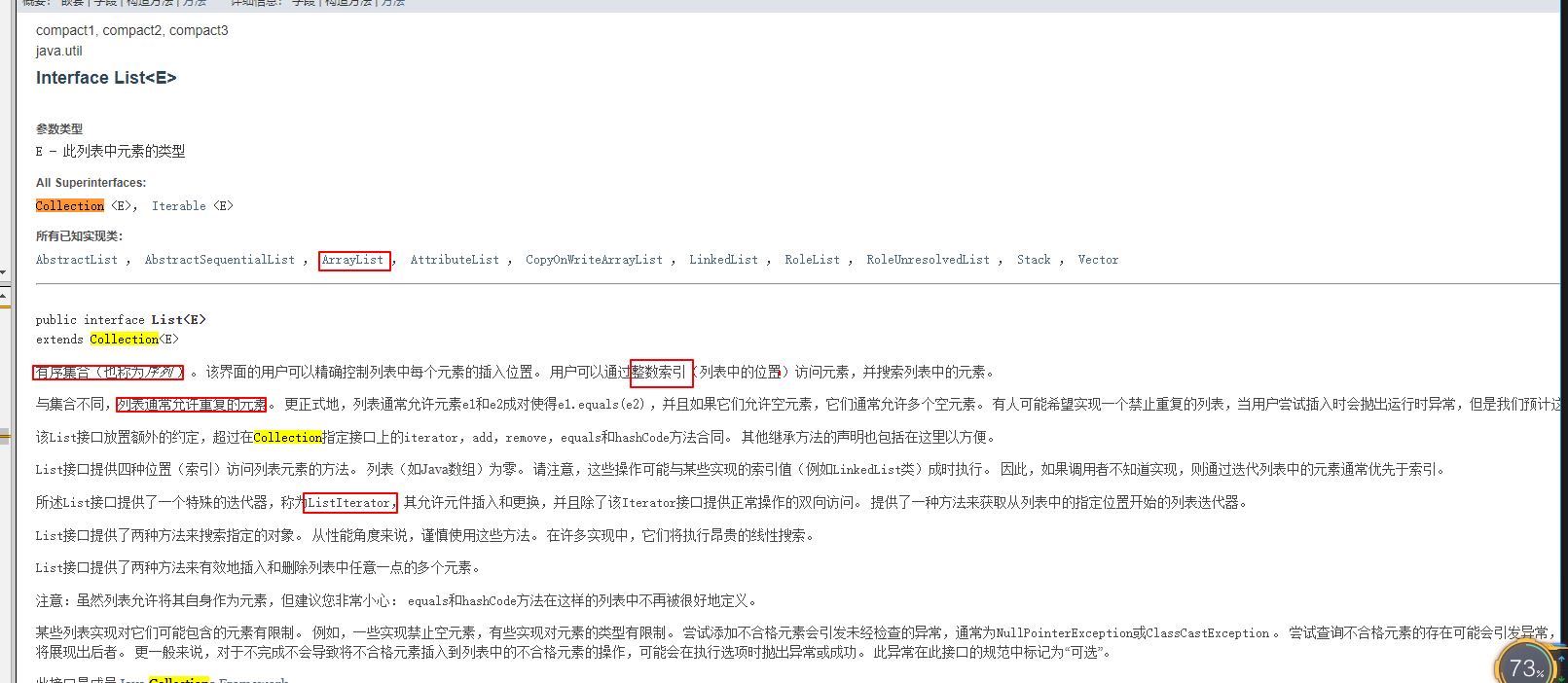
实现类有ArrayList, LinkedList,Vector常用
常用API
添加元素:add
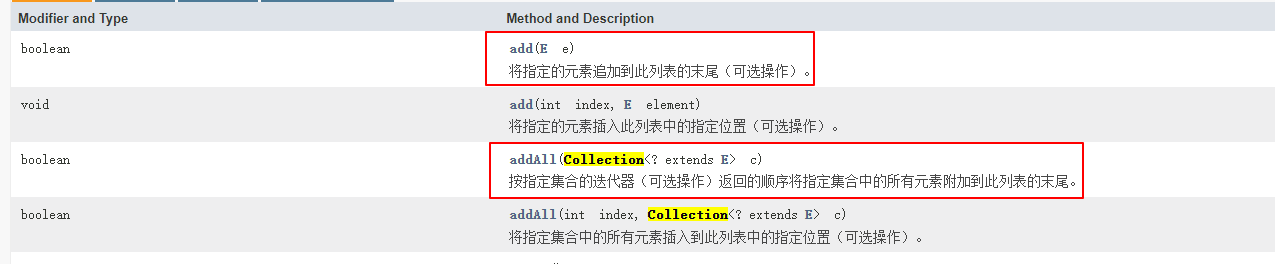
获取元素: get

删除元素;remove

是否包含:contains

是否为空:isEmpty

判断元素多少:size

ArrayList
ArrayList的底层数据结构是数组 =》数组的动态实现
查询快,增删慢,线程不安全
默认扩充为原来的1.5倍
随着向 ArrayList 中不断添加元素,其容量也自动增长 =》动态扩容
那Java本身就有数组了,为什么要⽤ArrayList呢?
(Arraylist动态扩容机制)
原⽣的数组会有⼀个特点:你在使⽤的时候必须要为它创建⼤⼩,⽽ArrayList不⽤。在⽇常开发的时候,往往我们是不知道数组的⼤⼩的如果数组的⼤⼩指定多了,内存浪费;如果数组⼤⼩指定少了,装不下假设我们给定数组的⼤⼩是10,要往这个数组⾥边填充元素,我们只能添加10个元素。⽽ArrayList不⼀样,ArrayList我们在使⽤的时候可以往⾥边添加20个,30个,甚⾄更多的元素因为ArrayList是实现了动态扩容的当我们new ArrayList()的时候,默认会有⼀个空的Object数组,⼤⼩为0当我们第⼀次add添加数据的时候,会给这个数组初始化⼀个⼤⼩,这个⼤⼩默认值为10使⽤ArrayList在每⼀次add的时候,它都会先去计算这个数组够不够空间如果空间是够的,那直接追加上去就好了。如果不够,那就得扩容--java3y
怎么扩容?⼀次扩多少?
扩容的原理是数组拷贝
在源码⾥边,有个grow⽅法,每⼀次扩原来的1.5倍。⽐如说,初始化的值是10嘛。现在我第11个元素要进来了,发现这个数组的空间不够了,所以会扩到15空间扩完容之后,会调⽤arraycopy来对数组进⾏拷⻉--java3y
/** * Increases the capacity to ensure that it can hold at least the * number of elements specified by the minimum capacity argument. * * @param minCapacity the desired minimum capacity */ private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) { @SuppressWarnings("unchecked") T[] copy = ((Object)newType == (Object)Object[].class) ? (T[]) new Object[newLength] : (T[]) Array.newInstance(newType.getComponentType(), newLength); System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength)); return copy; }
public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
为什么在⽇常开发中⽤得最多的是ArrayList呢?
是由底层的数据结构来决定的,在⽇常开发中,遍历的需求⽐增删要多,即便是增删也是往往在List的尾部添加就OK了。像在尾部添加元素,ArrayList的时间复杂度也就O(1)另外的是,ArrayList的增删底层调⽤的copyOf()被优化过现代CPU对内存可以块操作,ArrayList的增删⼀点⼉也不会⽐LinkedList慢--java3y
遍历方式
方式一:for循环遍历
1 for (int i = 0; i < arr.size(); i++) { 2 System.out.println(arr.get(i)); 3 }
方式二:增强型for循环
1 for (Object object : array) { 2 System.out.println("object:"+object); 3 }
方式三:List专用迭代器
可以双向遍历
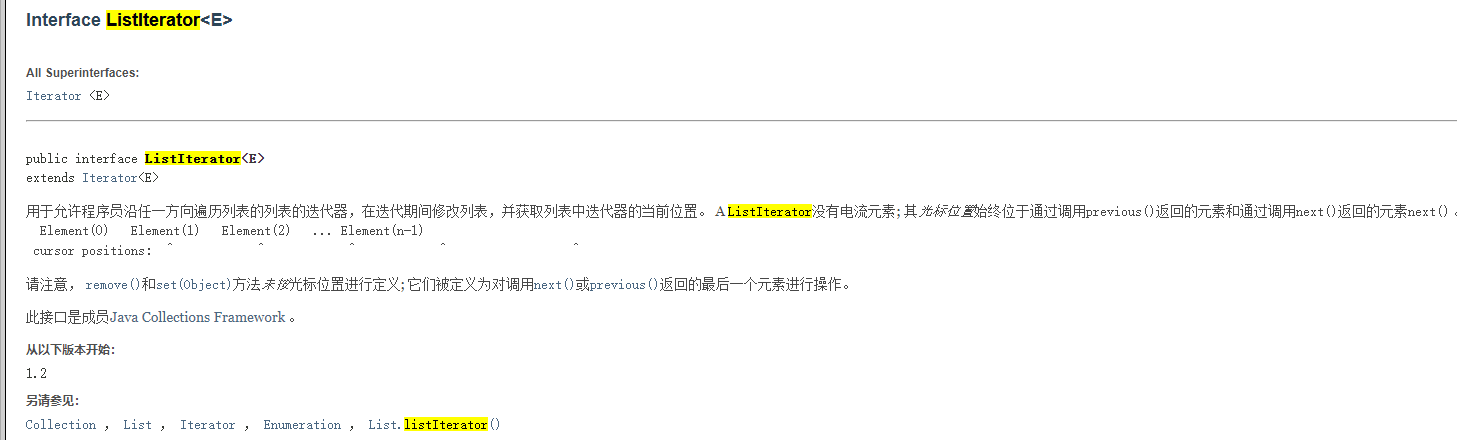
List<String> aList = new ArrayList<>(); aList.add("a"); aList.add("b"); aList.add("c"); ListIterator<String> listIterator = aList.listIterator();
// next后序遍历,起始位置,游标从-1算起 while (listIterator.hasNext()) { // 如果在末端,返回的是数组长度 也就是3 System.out.println("下一个位置:" + listIterator.nextIndex()); // 移动游标位置 System.out.println("下一元素" + listIterator.next()); } // 此时游标在末端, previous前序遍历,末尾位置 游标从数组长度算起 while(listIterator.hasPrevious()) { // 如果在末端,nextIndex()返回的是数组长度 也就是3 所以上一个位置是2 System.out.println("上一个位置:" + listIterator.previousIndex()); // 移动游标位置 System.out.println("上一元素" + listIterator.previous()); }

方式四:直接调用foreach API / stream的foreach也是一样
aList.forEach(System.out::print);
去重
利用java8 Stream流
已重写hashCode和equals
List<String> rebundList = aList.stream().distinct().collect(Collectors.toList());
自定义去重
collect(提供一个结束操作)

Collectors.toCollection(Supplier supplier)转Collection时提供Supplier进行排序操作
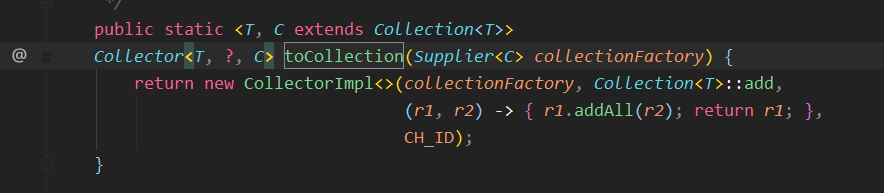
单属性去重
List<Student> collect = list.stream().collect( Collectors.collectingAndThen( Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(People::getName))), ArrayList::new));
多属性去重 通常以“;”进行隔开
1 ArrayList<Student> collect1 = list.stream().collect(collectingAndThen( 2 toCollection(() -> new TreeSet<>( 3 Comparator.comparing(element -> element.getName() + ";" + element.getAge()))), ArrayList::new));
排序
Stream流:
Stream<T> sorted(Comparator<? super T> comparator);
1 /** 2 * stream流排序 sort 3 */ 4 @Test 5 public void methodNameTest() { 6 List<People> peopleList = getPeopleList(); 7 // 正序 8 List<People> sortPeople = peopleList.stream() 9 .sorted(Comparator.comparing(People::getName)).collect(Collectors.toList()); 10 // [People(name=张三, age=23), People(name=张三, age=20), People(name=李四, age=20)] 11 System.out.println(sortPeople); 12 // 反序 reversed() 13 List<People> reSortPeople = peopleList.stream() 14 .sorted(Comparator.comparing(People::getName).reversed()).collect(Collectors.toList()); 15 // [People(name=李四, age=20), People(name=张三, age=23), People(name=张三, age=20)] 16 System.out.println(reSortPeople); 17 // 组合排序 comparing().thenComparing() 18 List<People> combineSort = peopleList.stream() 19 .sorted(Comparator.comparing(People::getName).thenComparing(People::getAge)).collect(Collectors.toList()); 20 // [People(name=张三, age=20), People(name=张三, age=23), People(name=李四, age=20)] 21 System.out.println(combineSort); 22 }
LinkedList
LinkedList和ArrayList的区别?
Vctor
除了Vctor,还有什么线程安全的List?
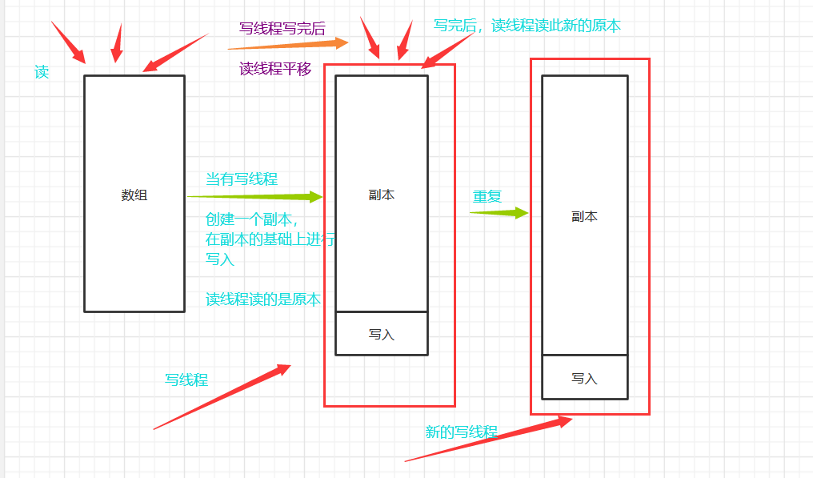
add()机制:

get()⽅法⼜或是size()⽅法只是获取array所指向的数组的元素或者⼤⼩,读不加锁,写加锁
优点:

Set
Set接口继承了Collection接口。Set集合中不能包含重复的元素,每个元素必须是唯一的。你只需将元素加入set中,重复的元素不会添加
HashSet

删除

HashSet排序
LinkedHashSet

TreeSet


public static void testName03(){ TreeSet<String> list= new TreeSet(new Compareby()); list.add("aaa"); list.add("a"); list.add("aa"); list.add("aaaa"); System.out.println(list); } class Compareby implements Comparator<String>{ //o1大于o2 返回正确 ,相等 返回 0 负整数 表示 o1小于o2 @Override public int compare(String o1, String o2) { int i= o1.length()-o2.length();//主要的按照长度来进行判断条件 return i==0 ? o1.compareTo(o2):i;//通过内容来进行对比次要的条件 }
LinkedHashSet是hashset的子类,hashset中有默认对Object对象类的hashcode和equals
LinkedHashSet继承自HashSet,源码更少、更简单,唯一的区别是LinkedHashSet内部使用的是LinkHashMap。这样做的意义或者好处就是LinkedHashSet中的元素顺序是可以保证的,也就是说遍历序和插入序是一致的。

作者: deity-night
出处: https://www.cnblogs.com/deity-night/
关于作者:码农
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 原文链接 如有问题, 可邮件(***@163.com)咨询.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号