四中基本排序算法几Java实现(冒泡、选择、插入、快排)
冒泡排序(Bubble Sort)也是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端。
作为最简单的排序算法之一,冒泡排序给我的感觉就像 Abandon 在单词书里出现的感觉一样,每次都在第一页第一位,所以最熟悉。冒泡排序还有一种优化算法,就是立一个 flag,当在一趟序列遍历中元素没有发生交换,则证明该序列已经有序。但这种改进对于提升性能来
1. 算法步骤
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
2. 动图演示
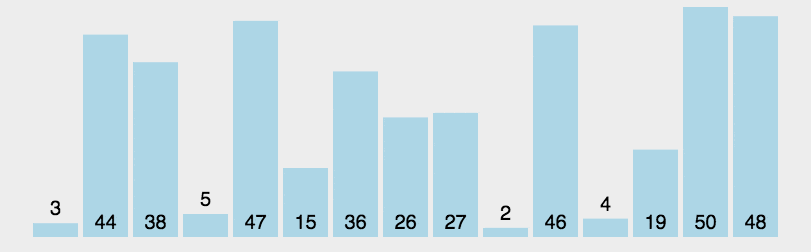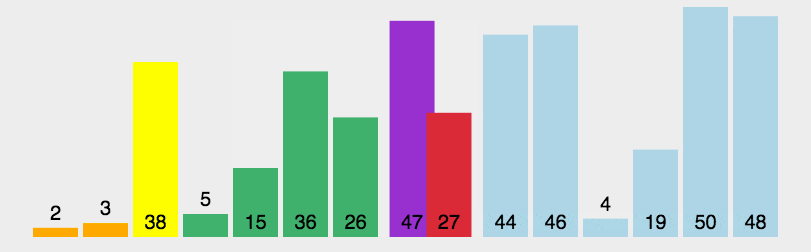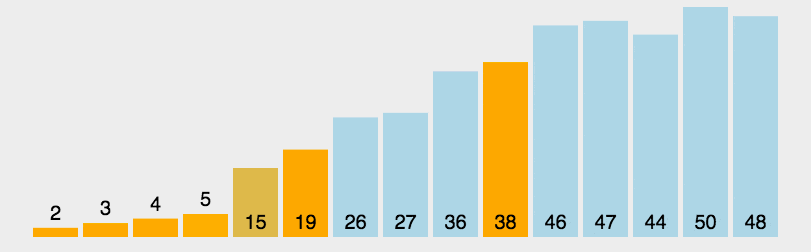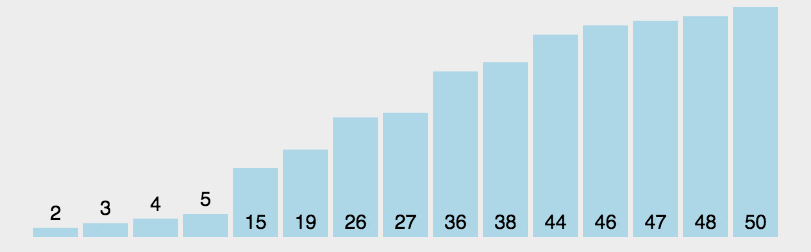
Java 代码实现
实例
public class BubbleSort implements IArraySort {
public int[] sort(int[] sourceArray) throws Exception {
// 对 arr 进行拷贝,不改变参数内容
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
for (int i = 1; i < arr.length; i++) {
// 设定一个标记,若为true,则表示此次循环没有进行交换,也就是待排序列已经有序,排序已经完成。
boolean flag = true;
for (int j = 0; j < arr.length - i; j++) {
if (arr[j] > arr[j + 1]) {
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = false;
}
}
if (flag) {
break;
}
}
return arr;
}
}
1.2 选择排序
分类 算法
选择排序是一种简单直观的排序算法,无论什么数据进去都是 O(n²) 的时间复杂度。所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。
1. 算法步骤
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
重复第二步,直到所有元素均排序完毕。
2. 动图演示
Java 代码实现
实例
public class SelectionSort implements IArraySort {
public int[] sort(int[] sourceArray) throws Exception {
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
// 总共要经过 N-1 轮比较
for (int i = 0; i < arr.length - 1; i++) {
int min = i;
// 每轮需要比较的次数 N-i
for (int j = i + 1; j < arr.length; j++) {
if (arr[j] < arr[min]) {
// 记录目前能找到的最小值元素的下标
min = j;
}
}
// 将找到的最小值和i位置所在的值进行交换
if (i != min) {
int tmp = arr[i];
arr[i] = arr[min];
arr[min] = tmp;
}
}
return arr;
}
}
1.3 插入排序
分类 算法
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了,因为只要打过扑克牌的人都应该能够秒懂。插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
插入排序和冒泡排序一样,也有一种优化算法,叫做拆半插入。
1. 算法步骤
将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
2. 动图演示
Java
实例
public class InsertSort implements IArraySort {
@Override
public int[] sort(int[] sourceArray) throws Exception {
// 对 arr 进行拷贝,不改变参数内容
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
// 从下标为1的元素开始选择合适的位置插入,因为下标为0的只有一个元素,默认是有序的
for (int i = 1; i < arr.length; i++) {
// 记录要插入的数据
int tmp = arr[i];
// 从已经排序的序列最右边的开始比较,找到比其小的数
int j = i;
while (j > 0 && tmp < arr[j - 1]) {
arr[j] = arr[j - 1];
j--;
}
// 存在比其小的数,插入
if (j != i) {
arr[j] = tmp;
}
}
return arr;
}
}
1.4快速排序
分类 算法
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。在最坏状况下则需要 Ο(n2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高!它是处理大数据最快的排序算法之一了。虽然 Worst Case 的时间复杂度达到了 O(n²),但是人家就是优秀,在大多数情况下都比平均时间复杂度为 O(n logn) 的排序算法表现要更好,可是这是为什么呢,我也不知道。好在我的强迫症又犯了,查了 N 多资料终于在《算法艺术与信息学竞赛》上找到了满意的答案:
快速排序的最坏运行情况是 O(n²),比如说顺序数列的快排。但它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。
1. 算法步骤
-
从数列中挑出一个元素,称为 "基准"(pivot);
-
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
-
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
2. 动图演示
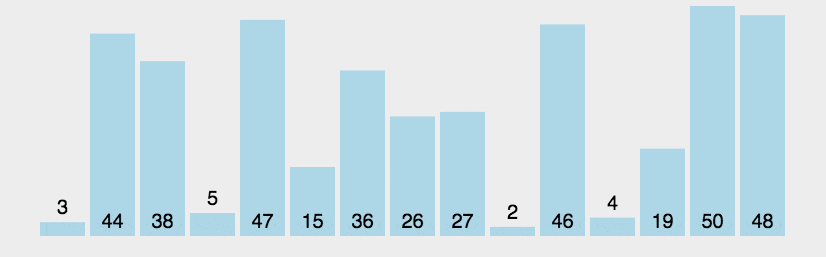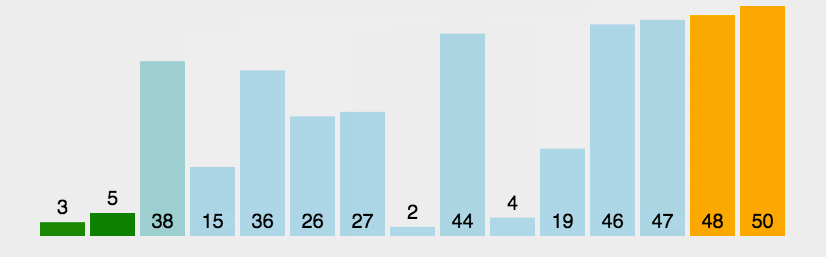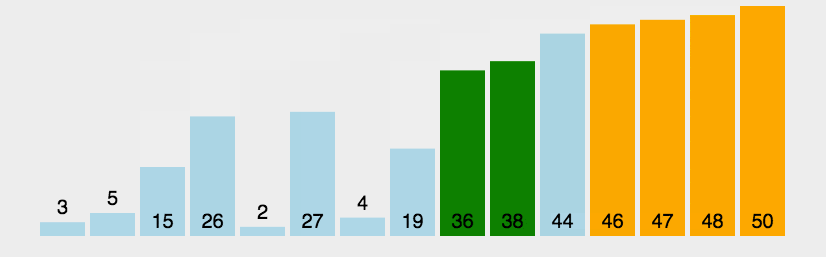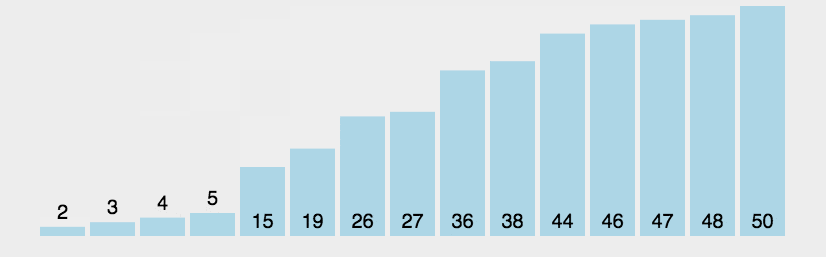
Java
实例
public class QuickSort implements IArraySort {
public int[] sort(int[] sourceArray) throws Exception {
// 对 arr 进行拷贝,不改变参数内容
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
return quickSort(arr, 0, arr.length - 1);
}
private int[] quickSort(int[] arr, int left, int right) {
if (left < right) {
int partitionIndex = partition(arr, left, right);
quickSort(arr, left, partitionIndex - 1);
quickSort(arr, partitionIndex + 1, right);
}
return arr;
}
private int partition(int[] arr, int left, int right) {
// 设定基准值(pivot)
int pivot = left;
int index = pivot + 1;
for (int i = index; i <= right; i++) {
if (arr[i] < arr[pivot]) {
swap(arr, i, index);
index++;
}
}
swap(arr, pivot, index - 1);
return index - 1;
}
private void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
冒泡排序(Bubble Sort)也是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端。
作为最简单的排序算法之一,冒泡排序给我的感觉就像 Abandon 在单词书里出现的感觉一样,每次都在第一页第一位,所以最熟悉。冒泡排序还有一种优化算法,就是立一个 flag,当在一趟序列遍历中元素没有发生交换,则证明该序列已经有序。但这种改进对于提升性能来
1. 算法步骤
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
2. 动图演示
Java 代码实现
实例
public class BubbleSort implements IArraySort {
public int[] sort(int[] sourceArray) throws Exception {
// 对 arr 进行拷贝,不改变参数内容
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
for (int i = 1; i < arr.length; i++) {
// 设定一个标记,若为true,则表示此次循环没有进行交换,也就是待排序列已经有序,排序已经完成。
boolean flag = true;
for (int j = 0; j < arr.length - i; j++) {
if (arr[j] > arr[j + 1]) {
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = false;
}
}
if (flag) {
break;
}
}
return arr;
}
}
1.2 选择排序
分类算法
选择排序是一种简单直观的排序算法,无论什么数据进去都是 O(n²) 的时间复杂度。所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。
1. 算法步骤
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
重复第二步,直到所有元素均排序完毕。
2. 动图演示
Java 代码实现
实例
public class SelectionSort implements IArraySort {
public int[] sort(int[] sourceArray) throws Exception {
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
// 总共要经过 N-1 轮比较
for (int i = 0; i < arr.length - 1; i++) {
int min = i;
// 每轮需要比较的次数 N-i
for (int j = i + 1; j < arr.length; j++) {
if (arr[j] < arr[min]) {
// 记录目前能找到的最小值元素的下标
min = j;
}
}
// 将找到的最小值和i位置所在的值进行交换
if (i != min) {
int tmp = arr[i];
arr[i] = arr[min];
arr[min] = tmp;
}
}
return arr;
}
}
1.3 插入排序
分类算法
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了,因为只要打过扑克牌的人都应该能够秒懂。插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
插入排序和冒泡排序一样,也有一种优化算法,叫做拆半插入。
1. 算法步骤
将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
2. 动图演示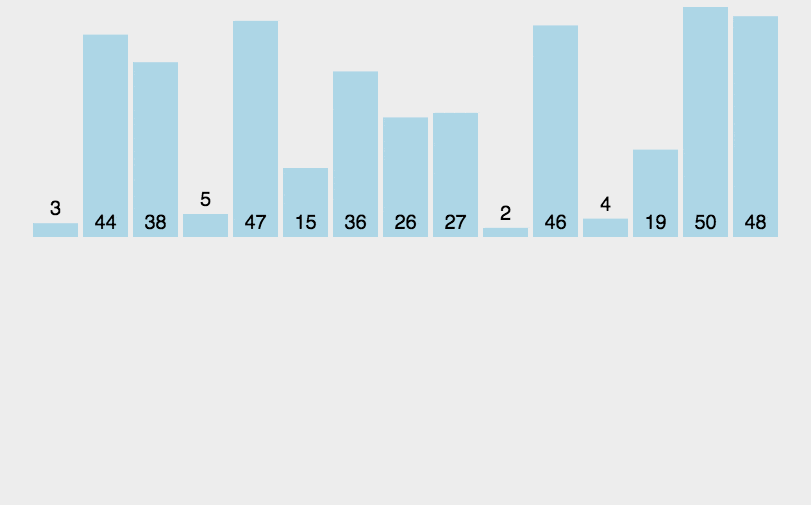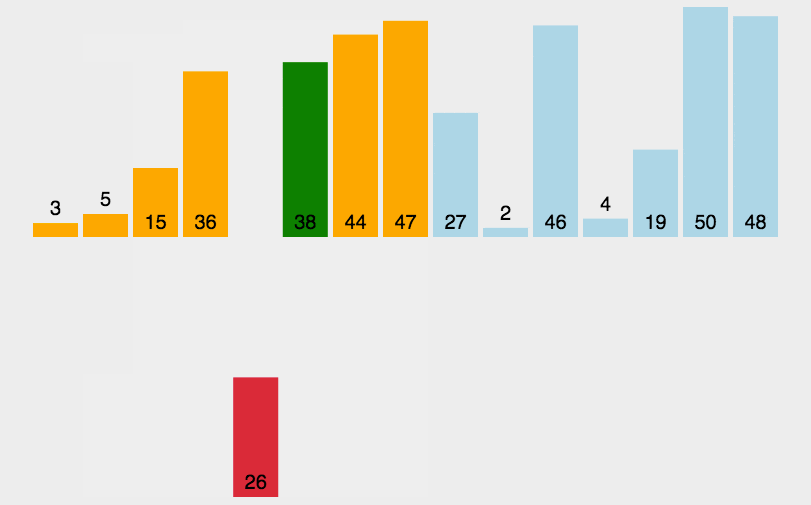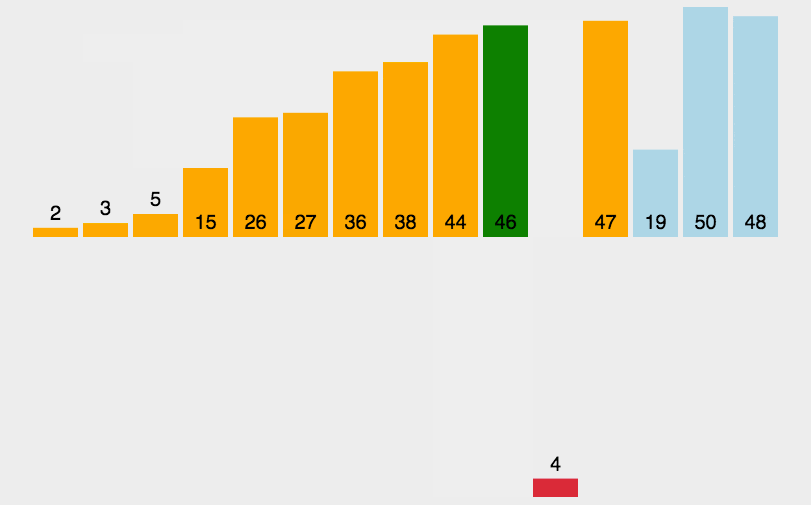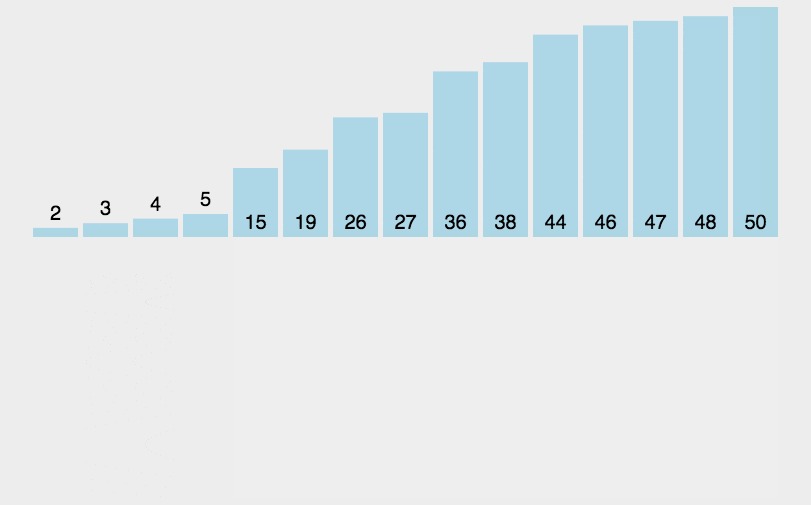
Java
实例
public class InsertSort implements IArraySort {
@Override
public int[] sort(int[] sourceArray) throws Exception {
// 对 arr 进行拷贝,不改变参数内容
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
// 从下标为1的元素开始选择合适的位置插入,因为下标为0的只有一个元素,默认是有序的
for (int i = 1; i < arr.length; i++) {
// 记录要插入的数据
int tmp = arr[i];
// 从已经排序的序列最右边的开始比较,找到比其小的数
int j = i;
while (j > 0 && tmp < arr[j - 1]) {
arr[j] = arr[j - 1];
j--;
}
// 存在比其小的数,插入
if (j != i) {
arr[j] = tmp;
}
}
return arr;
}
}
1.4快速排序
分类算法
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。在最坏状况下则需要 Ο(n2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高!它是处理大数据最快的排序算法之一了。虽然 Worst Case 的时间复杂度达到了 O(n²),但是人家就是优秀,在大多数情况下都比平均时间复杂度为 O(n logn) 的排序算法表现要更好,可是这是为什么呢,我也不知道。好在我的强迫症又犯了,查了 N 多资料终于在《算法艺术与信息学竞赛》上找到了满意的答案:
快速排序的最坏运行情况是 O(n²),比如说顺序数列的快排。但它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。
1. 算法步骤
-
从数列中挑出一个元素,称为 "基准"(pivot);
-
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
-
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
2. 动图演示
Java
实例
public class QuickSort implements IArraySort {
public int[] sort(int[] sourceArray) throws Exception {
// 对 arr 进行拷贝,不改变参数内容
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
return quickSort(arr, 0, arr.length - 1);
}
private int[] quickSort(int[] arr, int left, int right) {
if (left < right) {
int partitionIndex = partition(arr, left, right);
quickSort(arr, left, partitionIndex - 1);
quickSort(arr, partitionIndex + 1, right);
}
return arr;
}
private int partition(int[] arr, int left, int right) {
// 设定基准值(pivot)
int pivot = left;
int index = pivot + 1;
for (int i = index; i <= right; i++) {
if (arr[i] < arr[pivot]) {
swap(arr, i, index);
index++;
}
}
swap(arr, pivot, index - 1);
return index - 1;
}
private void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号