
视频编码器工作流程
1.视频编码器工作流程图
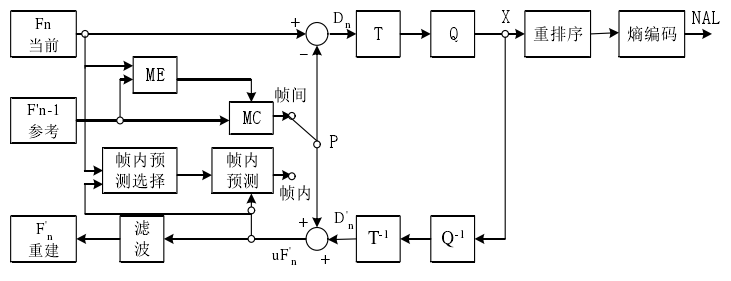
a.视频为什么能进行压缩?
因为存在时间和空间冗余...
b.为甚要有编码器的存在?
随着市场的需求,在尽可能低的存储情况下,获得好的图像质量和低宽带图像快速的传输...对视频进行压缩...
c.编码器的输入和输出是什么?
输入:一帧帧的图像(包括各种格式),编码器寄存器的配置;输出:码流,数据,sps...??
d.帧内预测:帧内预测模式中,预测块是基于已编码的重建块和当前块形成的...
通过帧内相邻的已经重建的宏块(左边、左上、上边)预测当前编码宏块,这样做既可以有效的抑制了因运动补偿产生的误码扩散,同时提高了帧
内预测的预测精度。
e.帧间预测:利用已编码的视频帧和基于块的运动补偿的预测模式。运动补偿:根据求出的运动矢量,找到当前帧的块是从前一帧的哪个位置移动过来的,从而得到当前帧像素块的预测值。
f.DCT(离散余弦变换):将图像的低频信号集中在DCT变换后的左上角的直流系数上,图像变换后的高频信号分配到其他交流系数上,视频图像的大部分信号集中在低频区域。
g.量化:DCT之后大部分为浮点数据,在不降低重建后的视频质量的前提下,尽可能减少视频图像的编码长度,量化中丢弃一些不影响视频重建的不必要的数据。
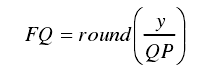
FQ:位量化后的值,QP:量化宽度,y:DCT变换后的原始数据,round:取整函数
QP:取较大值时,FQ有较小的动态范围,经过熵编码后,码字较小,但依据FQ重建出来的参考帧会丢失较多参考细节,影响视频质量。反之能得到较清晰的视频图像。
所以QP的值需要根据具体的带宽以及缓冲区的充盈度,在编码输出长度和图像质量之间找到一个平衡点。
量化为0的部分是无法还原的。
h.熵编码:提高视频压缩比,属于无损压缩,因此通过熵编码压缩后的视频信息可以在解码端无失真的重建出原始视频图像。(huffman,算数编码,游程编码)
I.按LCU行划分slice,h.265 64x64的最大宏块 h.264 16x16的最大宏块 ;按编码后的字节数划分slice 片与片之间会有台阶。
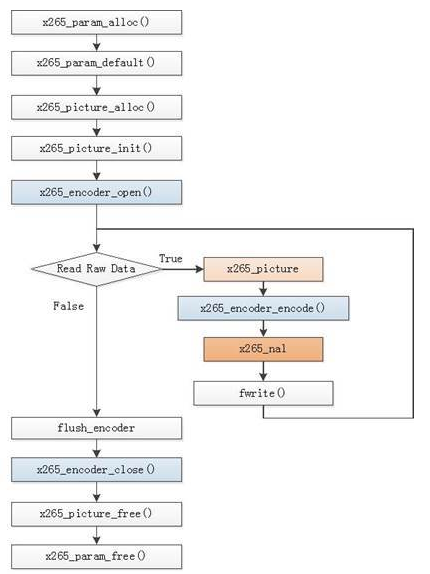
J.编码流程图:
h.VOP:视频对象平面(VOP,Video Object Plane)是视频对象(VO)在某一时刻的采样.
PEG-4在编码过程中针对不同VO采用不同的编码策略,即对前景VO的压缩编码尽可能保留细节和平滑;对背景VO则采用高压缩率的编码策略,甚至不予传输而在解码端由其他背景拼接而成。
编码类型:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号