
MySQL索引原理与使用原则
那些我们听过的索引优化手段
- 表的索引建得越全越好,对吗?
- 选择的索引列的长度不宜过长,对吗?
- 不要使用select * ,写明具体查询字段
- 模糊匹配like %abc,like%2673%, like%888都用不到索引,对吗?
- where条件中NOT IN 和 <> !=都无法使用索引对吗?
一、索引到底是什么(索引需要空间,原理是空间换时间)
数据库索引,是数据库管理系统(DBMS)中一个排序的数据结构,以协助快速查询,更新数据库表中数据。
- 索引类型:
- Normal
- Unique(需要有唯一值)
- 主键索引(不允许为空)
- FULL TEXT(长字符串,像like %s%)
- 索引方法:
- BTREE(数据库默认使用方法)
- HASH(时间复杂度O(1),因为无序,也不支持orderBy)

创建索引
ALTER TABLE user_info ADD INDEX inx_name(name);二、数据模型:
- 有序数组:是指在这个数组当中的所有数据,必须按照一定的顺序来排列,即便是插入新数据或者删除原有数据,仍然要按照既定规则来排序
- 单链表:是一种链式存取的数据结构,用一组地址任意的存储单元存放线性表中的数据元素
- 二分查找:每次折半查找
三、索引常见方法:
1、二叉查找树:

2、平衡二叉树(AVL):左右子树深度差绝对值不能超过1

AVL数据存储:一次加载磁盘内容到内存(磁盘I/O)的大小,默认:page 16k,一个树的大小就是16K,一次的磁盘I/O :一个键值 , 一个磁盘地址, 两个指针
问题:怎么减少磁盘I/O?
每个节点多装些内容 ---》多路平衡查找树
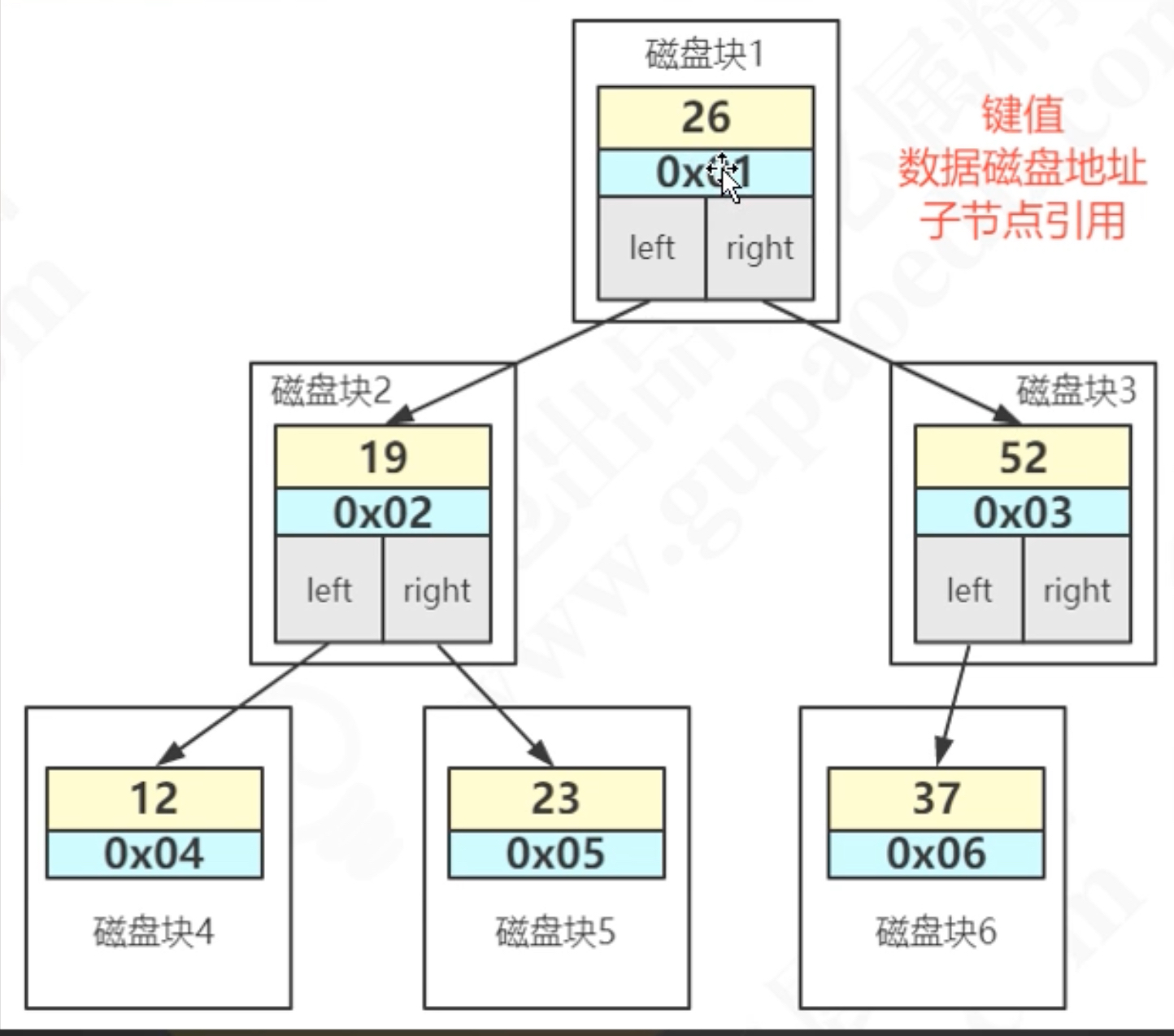
3、多路平衡二叉树:
如何实现一个节点存储多个数据,还保持平衡?
-->分裂、合并

4、B+Tree 加强版多路平衡查找树
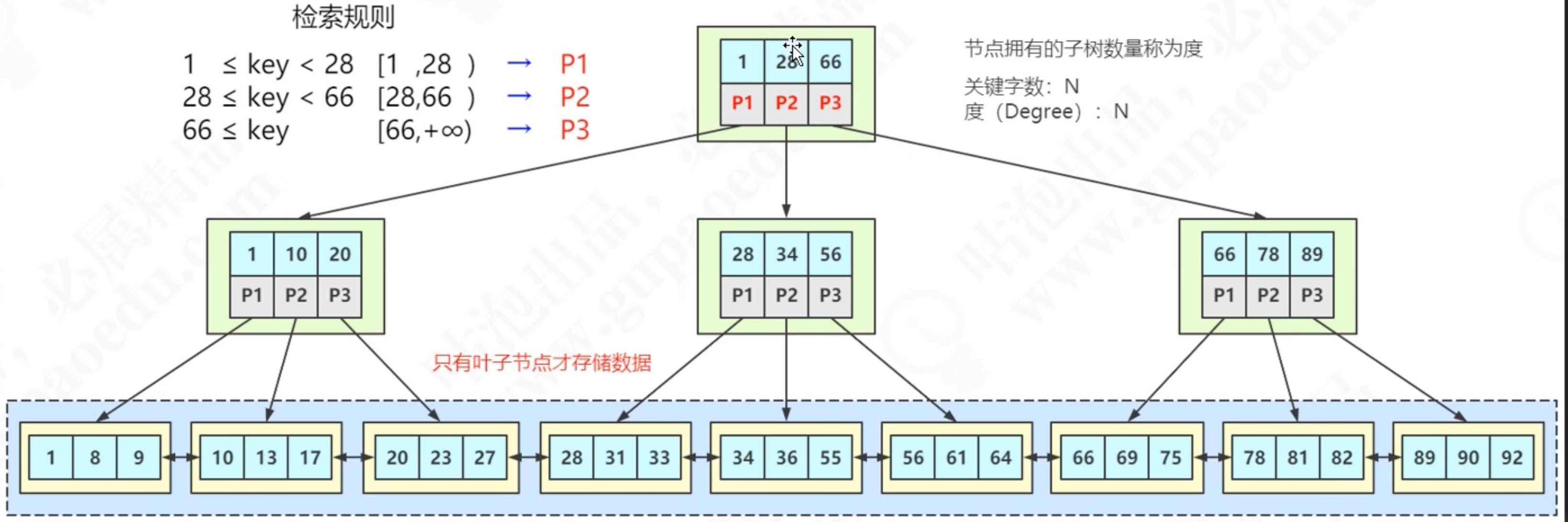
B+Tree的特点:
- B Tree 能解决的问题,B+ Tree都能解决
- 扫库、扫表能力更强
- 磁盘读写能力更强
- 排序能力更强
- 效率更加稳字
四、在存储引擎中索引如何实现?

根据需求选择引擎:
1、更快的访问速度: 内存
2、更高的一致性: 事务
3、历史数据存储:压缩 no index
最常用的存储引擎:MyISAM / InnoDb(推荐使用)
MyISAM 和 InnoDb有哪些区别:
| B-tree indexes | Clustered indexes | Data caches | Foreign key support | Locking granularity(锁颗粒度) | MVCC(多版本并发) | Transactions(事务) | |||
| MyISAM | yes | no | no | no | table | no | no | ||
| InnoDB | yes | yes | yes | yes | row | yes | yes |
InnoDB: 数据即索引,索引即数据(直接到内容放在索引里)

聚集索引: 数据行的物理存放顺序,跟索引的逻辑顺序相同
在InnoDB中,主键索引就是聚集索引(把内容放到索引上的这个行为叫聚集)
问题: 如果一张表没有主键呢?一张索没有定义索引?
1、primary key 主键索引就是聚集索引
2、unique key no null value 不包含空值,这样的第一个索引当成聚集索引
3、rowid 隐藏的id作为聚集索引
InnoDB: 辅助索引

四、为什么我创建了索引却用不到?
1、列的离散度(区分度)
-
-
- 离散度公式: count(distinct(column_name)) : count(*)
- gender 和 phone,哪一列的离散度更高 -->phone的离散度更高
-

2、联合索引最左匹配: 在使用联合索引时,where条件里的字段必须跟创建索引的字段一样,不能中断
ALTER TABLE user_infodb ADD INDEX 'comidx_name_phone'('name','phone');模拟服务器执行SQL语句,分析SQL语句使用 explain
explain select * from user_innodb where name = '章机轻' and phone = '16607463532';
explain select * from user_innodb where phone = '16607463532' and name = '章机轻';
explain select * from user_innodb where name = '章机轻';
explain select * from user_innodb where phone = '16607463532';执行结果第一行,第二行,第三行,都使用联合索引,其中第二个顺序不一至,使用optimizer优化器自动调整顺序:

下面这种创建索引的方式对吗?
select * from user_innodb where name = ? and phone = ?;
select * from user_innodb where name = ?;针对以下语句创建索引:
CREATE INDEX idx_name on user_innodb(name);
CREATE INDEX idx_name_phone on user_innodb(name,phone):解析:以上为冗余索引,建立a, b , c 的索引,会同时建立a / a,b / a, b ,c三种索引,不需要再额外再建索引
3、覆盖索引(explain ---> Extra字段中--> Using index)
select * from user_innodb where name = '章机轻' and phone = '16607463532'; #不属于覆盖索引
select name,phone from user_innodb where phone = '16607463532' and name = '章机轻'; #属于覆盖索引
select phone from user_innodb where name = '章机轻'; #属于覆盖索引
select phone from user_innodb where phone = '16607463532'; #覆盖索引 :基于成本的优化器(Cost Based Optimizer),主要是cpu IO计算的成本以下几种有可能会用不到索引?-->其它用不用得到索引主要由Optimizer说了算
- 在索引列使用函数或者表达式、计算
- 字符串不加引号,出现隐式转换
- like条件前面带%(最左前缀) -->like '%a'
- 负向查询: NOT LIKE/ !=(<>) / NOT IN
三十六般武艺,七十二般变化,修练出个人品牌并发出光芒

 浙公网安备 33010602011771号
浙公网安备 33010602011771号