

Python-标准库之处理URL-urllib
一、URL解析:urllib.parse
urllib.parse模块主要定义了两个类:1、urllib.parse.urlparse 通过一个URL字符串,将该字符串按组件(协议、网络位置、路径等)分解 ; 2、urllib.parse.quote 对特殊字符进行转义
-
urlparse: 分解URL,返回各组件
from urllib.parse import *
url = "https://i.cnblogs.com/posts/edit;postId=15137104"
o = urlparse(url)
print(o)
#执行结果: ParseResult(scheme='https', netloc='i.cnblogs.com', path='/posts/edit', params='postId=15137104', query='', fragment='')
print(o.scheme)
#执行结果:https --> URL协议
print(o.netloc)
#执行结果:i.cnblogs.com -->网络位置部分
print(o.params) #参数 -->postId=15137104
print(o.username)
print(o.password)通过解析URL得到的属性:
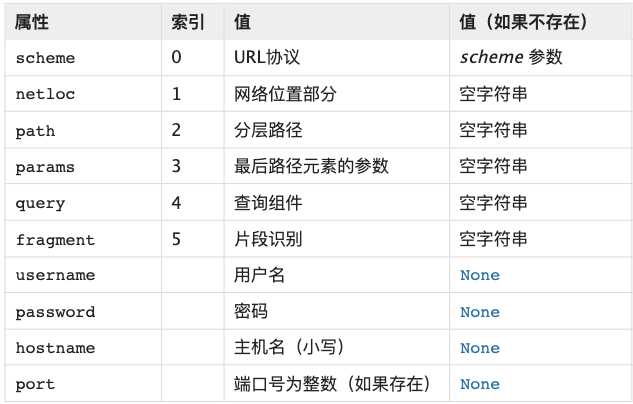
2.urlsplit: 也能分解URL,不同的是,urlsplit并不会把路径参数(params)从路径(path)中分离出来,当路径部分包含多个参数时,
#使用urlparse会出现问题
split_url = "http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg#fragment"
res = urlsplit(split_url)
print(res)
#执行结果:SplitResult(scheme='http', netloc='user:pwd@domain:80', path='/path1;params1/path2;params2', query='query=queryarg', fragment='fragment')
res1 = urlparse(split_url)
print(res1)
#执行结果:ParseResult(scheme='http', netloc='user:pwd@domain:80', path='/path1;params1/path2', params='params2', query='query=queryarg', fragment='fragment')3. urldefrag: 将URL中的碎片(fragment)分离出来
frag_url = "http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg#fragment"
res = urldefrag(frag_url)
print(res)
#执行结果:DefragResult(url='http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg', fragment='fragment')
print(res.url)
#执行结果:http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg
print(res.fragment)
#执行结果:fragment4.urlunparse(), urljoin() : 组建生成URL
- urlunparse()必须六个参数以上,否则报错not enough values
sub_url = ('http','user:pwd@domain:80','path1;params1/path2','params2','query=queryarg','fragment')
res = urlunparse(sub_url)
print(res)
#执行结果:http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg#fragment- urljoin()将两个字符串拼接成url
url1 = "https://home.cnblogs.com/"
url2 = "deeptester-vv"
res = urljoin(url1,url2)
print(res)
#执行结果:https://home.cnblogs.com/deeptester-vv5. urlencode(): 将一个字典(dict)编码并拼接成一个URL参数
dict = {
"name": 'vv',
"age": 18,
"sex": "Female"
}
res = urlencode(dict)
print(res)
#执行结果: name=vv&age=18&sex=Female6、parse_qs(): 将编码后的URL参数解析成dict
dict = {
"name": 'vv',
"age": 18,
"sex": "Female"
}
res = urlencode(dict)
print(res)
#执行结果: name=vv&age=18&sex=Female
print(parse_qs(res))
#执行结果: {'name': ['vv'], 'age': ['18'], 'sex': ['Female']}7. quote: 对特殊字符进行转义,unquote则相反
res = quote("中国")
print(res)
#执行结果: %E4%B8%AD%E5%9B%BD
res1 = unquote("%E4%B8%AD%E5%9B%BD")
print(res1)
#执行结果: 中国二、URL请求模块:urllib.request
关于 urllib.request: urllib.request 模块提供了最基本的构造 HTTP (或其他协议如 FTP)请求的方法,利用它可以模拟浏览器的一个请求发起过程。利用不同的协议去获取 URL 信息。它的某些接口能够处理基础认证 ( Basic Authenticaton) 、redirections (HTTP 重定向)、 Cookies (浏览器 Cookies)等情况。而这些接口是由 handlers 和 openers 对象提供的。
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)注意:url为https类型时有时会报错:urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1129)>
解决方案:
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
三十六般武艺,七十二般变化,修练出个人品牌并发出光芒


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律