
Nccl allreduce && BytePS原理
一、Nccl AllReduce基本原理:
allreduce是collective communication中的一种,其他种类的还有:Broadcast、Scatter、Gather、Reduce等
具体含义可以参考文档:https://images.nvidia.com/events/sc15/pdfs/NCCL-Woolley.pdf、
其中nccl采用一种Undirectional-Ring的单向环算法,可以实现同步时间与卡的个数无关,以BroadCast为例:
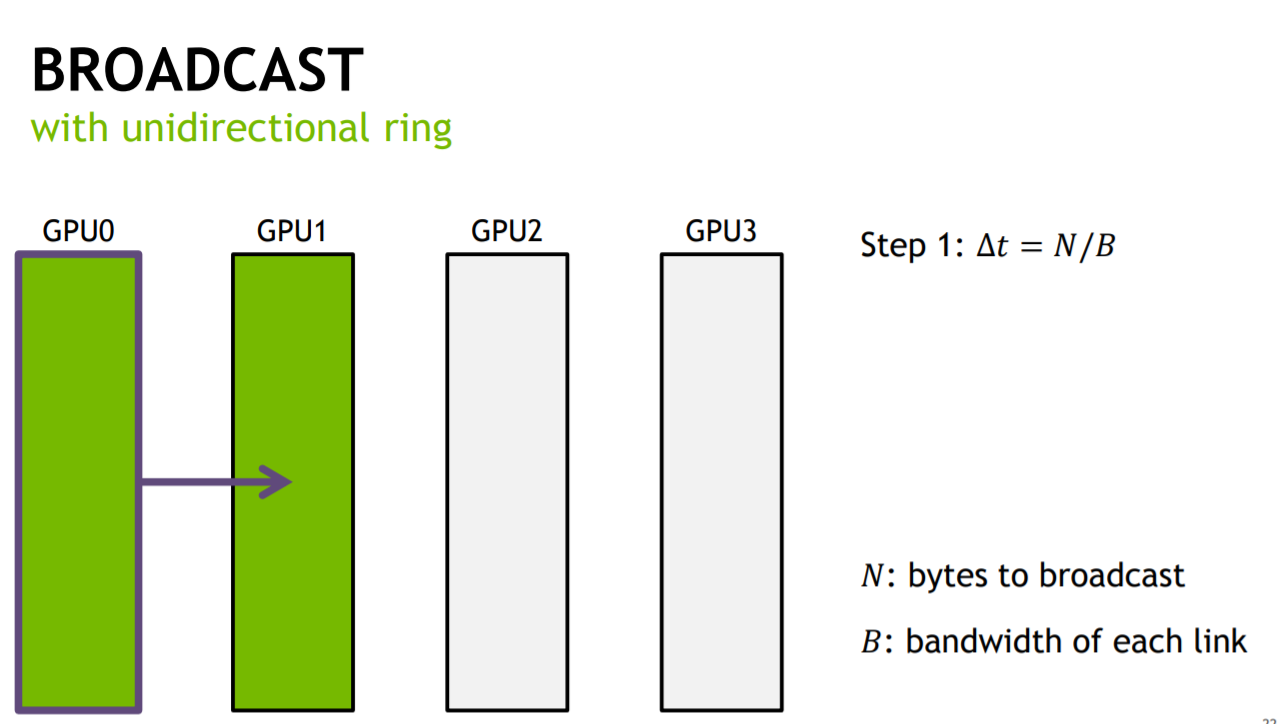
假设有4块GPU,传输的数据量为N,传输带宽为B(单机多卡间的传输带宽可以通过cuda/sample下的p2pBandwidthLatencyTest得到),如果按照顺序发送的方式,完成整个BroadCast的时间(同步时间)为:(4-1)N/B,即传输时间与卡的个数成正比.

如果将N大小的数据分成S份,然后GPU0每次只传输一份数据给GPU1,依次类推,那么总时间是GPU0传输到GPU1的时间 + 最后一份数据从GPU1到GPU3的时间,即:SN/(SB) + (4-2)*N/(SB)=(S+4-2)N/SB = N/B,可以看出若S无穷大,这样同步时间就与卡的个数无关了.
理解了BroadCast的例子再去理解AllReduce的例子就好多了,Allreduce分为两个阶段:Reduce-Scatter + AllGather,具体可参考:http://andrew.gibiansky.com/
首先经过Reduce-Scatter在每个GPU上各算出一部分和,然后在通过AllGather传递给全部GPU.假设传输的数据大小为K,GPU个数为N,
通过文章中的代价分析可以得出:每个GPU传输的数据量大小为K/N,Reduce-Scatter传输的次数为N-1次,AllGather同样为N-1次,因此每个GPU传输的数据总量均为:2(N-1)K/N.(请记住这个值)
这里注意,文章https://images.nvidia.com/events/sc15/pdfs/NCCL-Woolley.pdf中的AllReduce实现是不同的,如图所示:
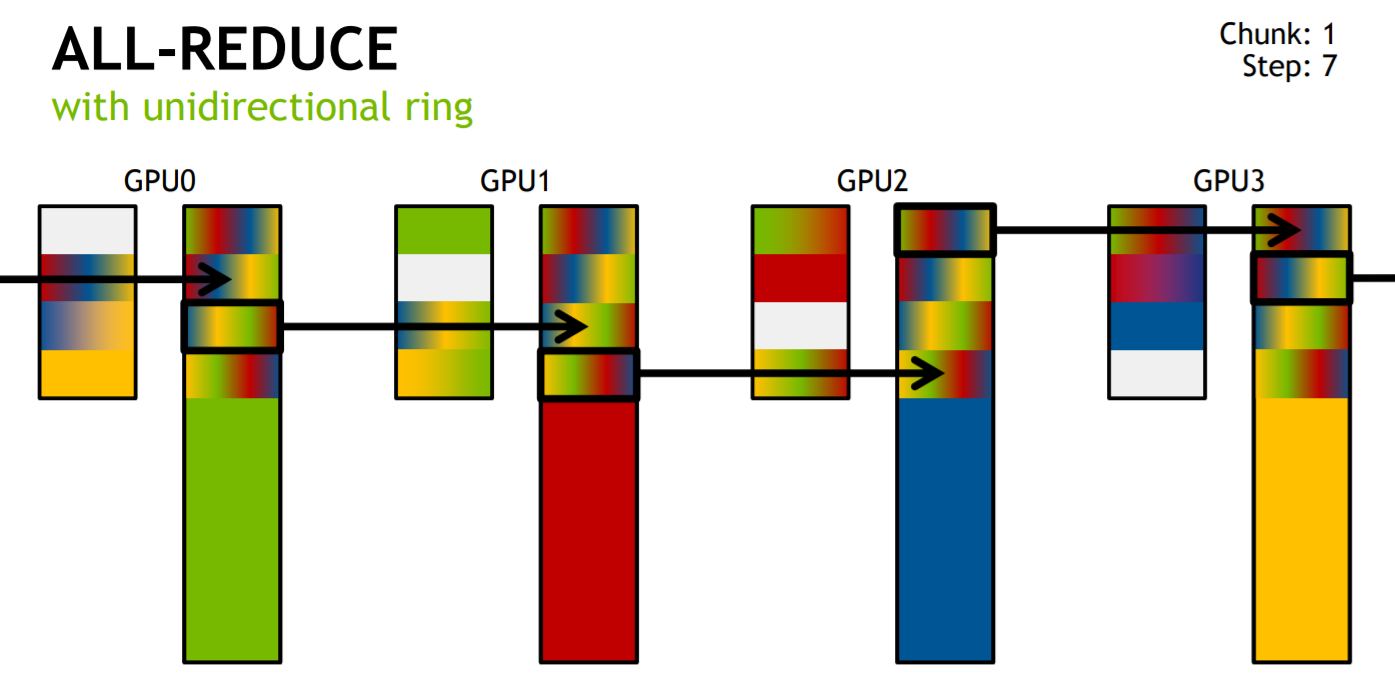
文中的意思很明显是分段执行Reduce-Scatter和AllGather,但是其实数据传输量也是2(N-1)K/N,感兴趣的可以自己算一下.
二、BytePS是如何减少数据传输量的.
以下内容主要参考:https://www.zhihu.com/question/331936923/answer/732262268
首先虽然头条将其命名为PS(Params Server),但是:其借鉴了PS的方式实现的却是AllReduce.
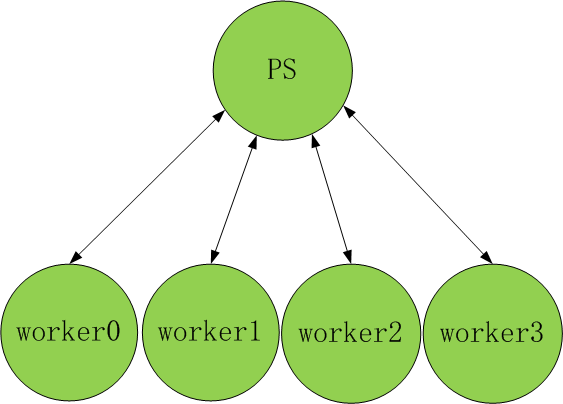
以上图为例,假设有4个worker节点和一个PS节点,此时PS不再持有任何params,只是每次接受梯度做aggregation,一般都是mean(这个阶段相当于reduce-scatter),然后再传回每个worker(这个阶段相当于AllGather),本质就是实现了AllReduce,这时PS的作用是为了增加带宽.那这种实现方式相比Ring-AllReduce传输量有多少呢?
假设worker数为N,每个worker传输数据大小为M,并且一次性全部传到PS端,那么PS一次接受的数据量为NM(假设同时算完),然后做mean操作,算完了再传回就又需要NM的传输量,不做任何优化传输数据总量为2NM(浪费了双向带宽). 如何优化?
这里首先借鉴Nccl的BroadCast思路,将M大的数据分为K份,每次只传输M/K大小的数据,然后在此M/K大小的数据做完取mean操作之后马上传回全部worker,而同时下一份M/K大小的数据传入PS,这样就相当于①传数据+计算(reduce-scatter)②传回worker(allGather)形成一个Pipeline,并且利用了双向带宽,这样就等价于带宽变为2倍,传输的数据量减半,即变为NM.
第二次优化就是:加机器. 如图所示:
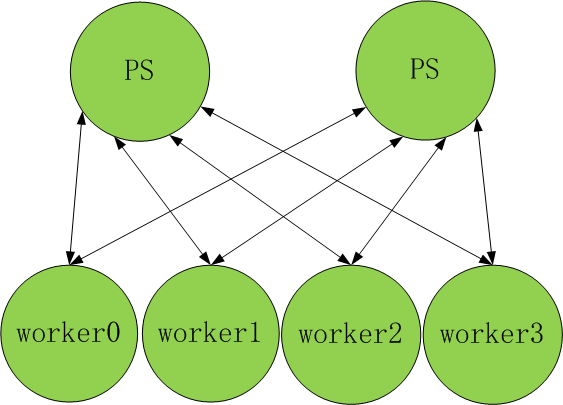
加机器就等价于带宽继续增加,这样每个PS只需要处理M/2的数据量就可以了.假设PS的数量等于worker的数量,那么数据传输量理想情况就是M,此值是小于2(N-1)*M/N的,理论上正好是Ring-AllReduce数据传输量的一半,如果能保证机器的传输带宽都是B,那么同步时间就是M/B. 如果PS节点更多,那么数据传输量将更少,同步时间也将更少.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号