Python3基础(3)集合、文件操作、字符转编码、函数(*args和*kwargs)、全局/局部变量、递归、函数式编程、高阶函数
---------------个人学习笔记---------------
----------------本文作者疆--------------
------点击此处链接至博客园原文------
1.集合
集合是无序的、不重复的数据组合,主要作用是:关系测试、去重等,用{}表示,set() 创建集合。
--------------关系测试------------------------------
intersection() 求集合交集 运算符为 &
union() 求集合并集 运算符为 |
difference() 求集合差集 运算符为 -
issubset() 判断是否为子集
issuperset() 判断是否为父集
symmetric_difference() 求对称差集,即并集-交集 运算符为 ^
isdisjoint() 若两集合无交集返回True


--------------基本操作------------------------------
add() 向集合增加1个元素
update() 向集合增加多个元素,括号内为列表
remove() 删除集合1个元素,该元素必须存在,否则报错
len() 集合长度
in 判断元素是否在集合内
not in 判断元素不否在集合内
copy() 浅复制

pop() 删除任意某个元素并返回该元素
discard() 删除集合1个元素,该元素可以不存在,不存在则不做任何操作,存在则删除

2.文件操作
f = open(文件名,打开文件模式) 打开文件返回文件句柄,有时根据情况需指定encoding,也有with open() as f: 这种方式(称为:管理上下文)当with代码块执行完毕,内部将自动关闭并释放资源
f.read() 一次读取文件全部内容,若连续两次f.read()则第2次读不到任何东西,因为第一次read后光标已经至末尾 模式可选为“r”
f.write() 向文件写入内容(创建新文件,若有同名文件则覆盖) 模式可选为“w”
f.write() 向文件中末尾追加内容 模式选为“a”
f.readline() 读取文件一行
f.readlines() 一次性按行读取文件,返回列表(每行为一个元素),适合处理小文件
for line in f: 大文件可逐行读取,内存中只保留一行数据,效率最高(文件变成迭代器)
f.tell() 文件句柄指针位置(可理解为光标位置,按字符计数)
f.seek() 设置句柄指针位置,如f.seek(0) 则光标移至文件开头
f.encoding 该文件的编码
f.name 该文件的名字
f.isatty() 判断是否为终端设备,如打印机
f.flush() 强制刷新,io往文件写的时候是等到待写入文件达到buffer_size才一起写入,f.flush()可以强制刷新,直接即时写入
f.truncate() 截取x个字符
f.close() 关闭文件句柄
----------------------------------------打开文件模式------------------------------------------
r 只读,若文件不存会报错
w 只写,若文件不存在则自动创建再写入,会覆盖文件
a 追加,若文件不存在则自动创建再写入,不会覆盖文件,但在末尾追加
r+ 读写,若文件不存会报错,写会覆盖文件(比如读三行后后再写,写的时候不是从光标当前位置写了,而是在末尾追加写)
w+ 写读,若文件不存在则自动创建再写入,写会覆盖文件
a+ 追加,若文件不存在则自动创建再写入,写不会覆盖文件,但在末尾追加
wb,rb类似于w、r,但用于二进制文件(如视频)或Python3中网络传输
---------------------------------------------------------------------------------------------------------
3.文件修改
上述文件操作中修改文件会将原文件覆盖
方法一:类似于vim先将文件加载到内存里再修改,效率低
方法二:读文件修改后写入一个新的文件,相比较效率更高
注意字符串操作有返回值,原字符串值不被修改

4.进度条(缓冲flush)

5.字符转编码
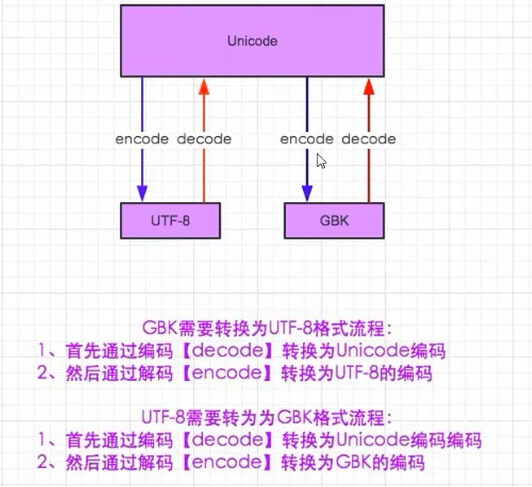
-----------------------------------Python2------------------------------------
系统默认编码 sys.getdefaultencoding()为ASCII编码
程序中若带有中文需在开头申明UTF-8编码
UTF-8字符串str1转为GBK:str1.decode("utf-8").encode("gbk")
GBK字符串str2转为UTF-8:str2.decode("gbk").encode("utf-8")
其余未涉及的转编码类似,都要经过unicode
-----------------------------------Python3--------------------------------------
默认编码为Unicode,赋值一个字符串则为Unicode编码,字符转编码与Python2相同
Python3中encode()不仅将字符编码集改了,还会转成bytes类型
如开头申明 # -*-coding:gbk-*-则意味着文件编码为gbk 赋值一个字符串仍为Unicode编码,而不是gbk
6.函数
------------------------------三种编程范式------------------------------
面向对象:类 class
面向过程:过程 def,没有返回值的函数,Python中隐式地返回None
函数式编程?:函数 def,代码重用、保持一致性、可扩展性
-------------------------------------------------------------------------------
函数内return后不再执行代码
若函数return多个值,而调用函数赋给1个变量,则返回值以tuple形式返回
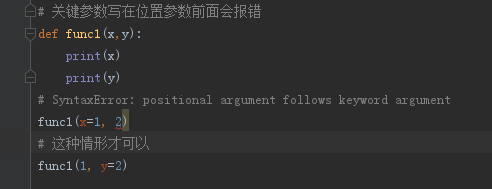
位置参数调用、关键参数调用,两种方式混合时关键参数不能写在位置参数前面
默认参数,定义形参时同时赋默认值,调用函数时默认参数非必须传递赋值
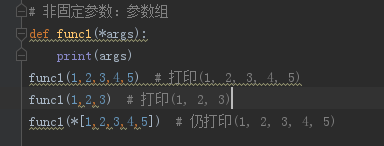
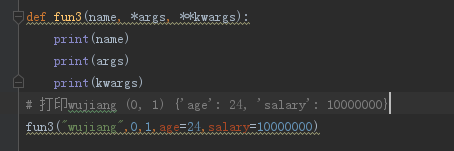
----------------------------------函数的非固定参数------------------------------
即实参传递数目不固定,形参如何声明?参数组
实参转换为元组
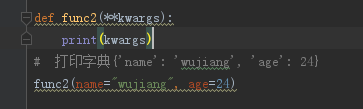
实参转换为字典,实参需以关键参数形式写
7.获取系统当前时间
import time
time_format = "%Y-%m-%d %X"
time_current = time.strftime(time_format)
8.全局/局部变量
局部变量只在函数内部生效,其作用域为对应定义的函数
全局变量应在程序一开始顶级定义,其作用域为整个程序
允许函数内部有与全局变量同名的变量,在该函数内部该变量起作用,在其余地方全局变量起作用
若想在函数内部改变全局变量的值,可在函数内部用global声明,不建议这么做,易造成程序逻辑混乱
除了整数、字符串未加global时不能在函数内部修改全局变量,其余像(列表、字典、集合...)均可不加global就能在函数内部修改全局变量!
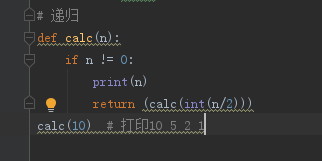
9.递归
如果一个函数在内部调用自身,该函数就是递归函数
------------------------递归特性------------------------
必须有一个明确的结束条件(最大递归999次)
每次进入更深一层递归时,问题规模相比上次递归都应有所减少
递归效率不高,递归层次过多会导致栈溢出(函数调用是通过栈stack这种数据结构实现的)
10.函数式编程(lisp、hashshell、erlang)
虽然可以归结到面向过程的程序设计,但其思想更接近数字计算。由于我们在Python中常定义函数中涉及一些逻辑判断(变量状态不确定),
使得输入确定,输出不确定,即对于同样的输入,可能得到不同的输出,这种函数有副作用。而函数式编程更侧重数字计算,输入确定,
输出确定。Python对函数式编程提供部分支持,由于Python允许使用变量,因此,Python不是纯函数式编程语言。
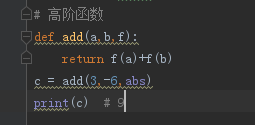
11.高阶函数
一个函数接收另一个函数作为参数,这种函数称为高阶函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号