机器学习基础
机器学习,一直以来都是计算机相关从业者研究的领域之一,整个行业也在欺负之中不断地深入发展。随着深度学习的崛起,及其徐诶再一次乘上了时代的浪潮,成为新宠!今后将在博客园和大家一起分享我在深度学习这一块的各种酸甜苦辣
机器学习:顾名思义是指机器学习的一个过程。
在机器学习中,有三个基本的要素:任务T、经验E和性能P。则机器学习=通过经验E的改进后,机器在任务T上的性能p所度量的性能有所改进=T--(从E中学习)-->P(提高)
机器学习中常见的任务T分类:




性能度量P:
1.准确率 2.错误率 3.样本概率的对数平均值
训练集:用于训练机器学习的数据集
测试集:用于测试机器学习效果的数据集
训练集和测试集都是由许多的样本点组成
经验E:
无监督学习:数据集无标签,如密度分布,去燥等
有监督学习:数据集有标签,如线性回归,部分分类问题等
P和E的关系以及机器学习的目的:
“经验”通常是以“数据”形式存在;而机器学习的目的就是从这些数据中的经验产生一个模型(model),然后用这个产生出来的model去帮助我们解决新的问题,并且把模型在解决新的问题上的能力称为泛化能力!在训练集上产生的误差称为训练误差,而在测试集上产生的误差称为泛化误差!
机器学习的五大部件:
1.任务 2.模型 3.性能度量 4.学习算法 5.经验
我们以一个线性回归任务为例说明:

那么本次针对线性回归的目的,则是通过学习测试集中数据的经验,生成一个模型,将模型产生的输出值与样本真实值之间的均方误差作为性能度量标准,我们需要选择一个合适的学习算法(最小二乘法、梯度下降等)使该性能度量标准达到最优!
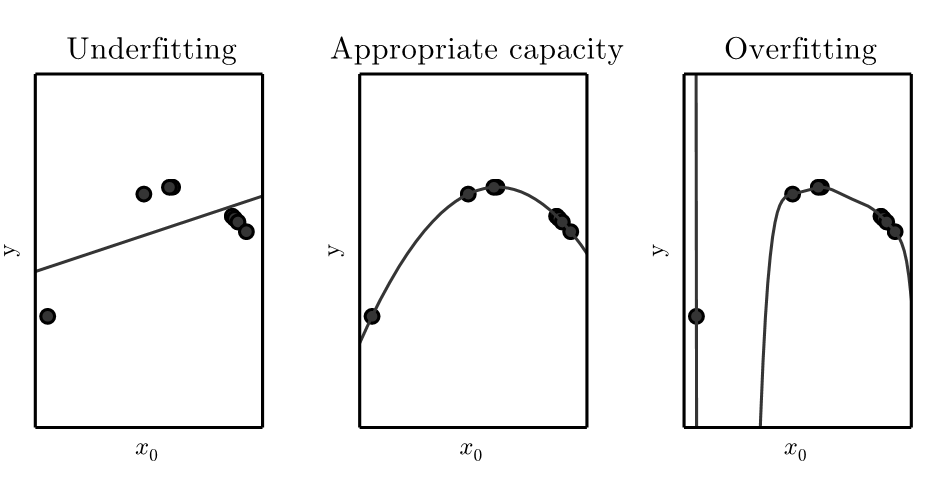
欠拟合:模型在训练集上的误差过大
过拟合:模型在测试集上的误差过大
容量:模型拟合各种函数的能力。一般来说,容量低的模型容易导致欠拟合,而容量高的模型容易导致过拟合。
在线性回归问题中:

不同的模型容量导致不同的效果:
在机器学习过程中,不是通过学习所获得的参数,称为超参数(学习率等)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号