
FlowMo: 模式搜索+扩散模型提升图像Token化性能
自VQGAN和Latent Diffusion Models等视觉生成框架问世以来,先进的图像生成系统通常采用两阶段架构:首先将视觉数据Token化或压缩至低维潜在空间,随后学习生成模型。传统Token化器训练遵循标准范式,通过MSE、感知损失和对抗性损失的组合约束来实现图像压缩与重建。虽然扩散自编码器曾被提出作为端到端感知导向图像压缩的学习方法,但在ImageNet1K重建等竞争性任务上尚未展现出优越性能。
这个研究提出了FlowMo,一种基于Transformer的扩散自编码器,在多种比特率条件下实现了图像Token化的最新技术水平。其显著特点在于无需依赖卷积网络、对抗性损失、空间对齐的二维潜在编码或从其他Token化器中提取表征。FlowMo的关键技术创新在于其训练流程被划分为模式匹配预训练阶段和模式搜索后训练阶段。通过广泛的分析与消融实验,验证了该方法的有效性,并在FlowMo Token化器基础上训练了生成模型,进一步确认了其性能优势。
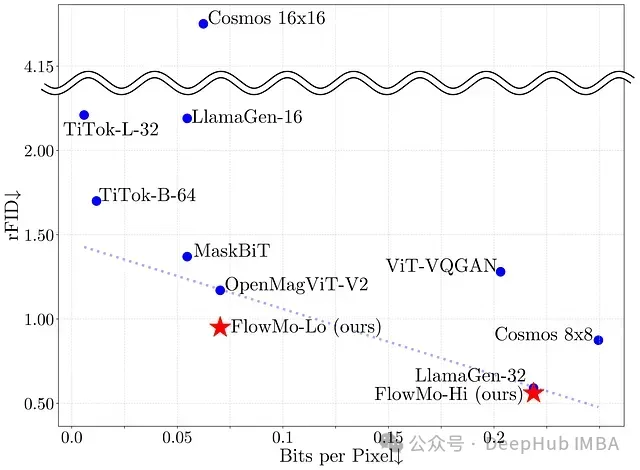
FlowMo在低比特率(FlowMo-Lo)和高比特率(FlowMo-Hi)条件下均达到了图像Token化的领先性能。作为一种基于Transformer的扩散自编码器,FlowMo摒弃了卷积层、对抗性损失以及来自辅助Token化器的代理目标,显示出其独特的技术优势。
https://avoid.overfit.cn/post/baf2f21e78e9457eb3bfe25d8009c012

 浙公网安备 33010602011771号
浙公网安备 33010602011771号