SmolLM2:多阶段训练策略优化和高质量数据集,小型语言模型同样可以实现卓越的性能表现
SmolLM2 采用创新的四阶段训练策略,在仅使用 1.7B 参数的情况下,成功挑战了大型语言模型的性能边界:
- 在 MMLU-Pro 等测试中超越 Qwen2.5-1.5B 近 6 个百分点
- 数学推理能力(GSM8K、MATH)优于 Llama3.2-1B
- 在代码生成和文本重写任务中展现出色表现
- 支持 8K tokens 的长文本处理能力
这些成果得益于其精心设计的多阶段训练方法:通过在约 11 万亿 tokens 的优质数据上,逐步优化模型的通用认知、专业能力和指令遵循表现。研究团队还特别构建了 Fine-Math、Stack-Edu 和 SmolTalk 等专业数据集,进一步提升了模型在数学推理、代码生成等关键领域的性能。
这一研究证明,通过优化的训练策略和高质量数据集,小型语言模型同样可以实现卓越的性能表现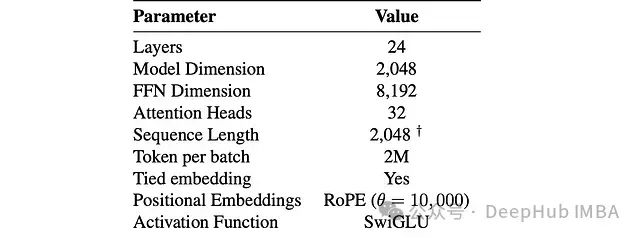
https://avoid.overfit.cn/post/a209e07e74154d689dc32ce557e786cb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号