LLM高效推理:KV缓存与分页注意力机制深度解析
随着大型语言模型(LLM)规模和复杂性的持续增长,高效推理的重要性日益凸显。KV(键值)缓存与分页注意力是两种优化LLM推理的关键技术。本文将深入剖析这些概念,阐述其重要性,并探讨它们在仅解码器(decoder-only)模型中的工作原理。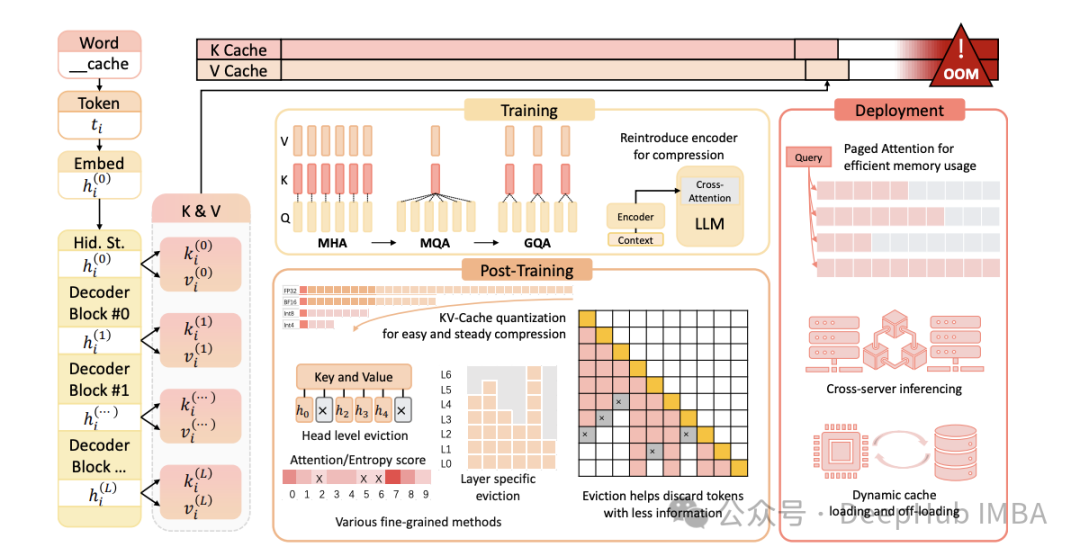
https://avoid.overfit.cn/post/db8875e43cd245359577a52c6018f81a
随着大型语言模型(LLM)规模和复杂性的持续增长,高效推理的重要性日益凸显。KV(键值)缓存与分页注意力是两种优化LLM推理的关键技术。本文将深入剖析这些概念,阐述其重要性,并探讨它们在仅解码器(decoder-only)模型中的工作原理。
https://avoid.overfit.cn/post/db8875e43cd245359577a52c6018f81a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号