近端策略优化(PPO)算法的理论基础与PyTorch代码详解
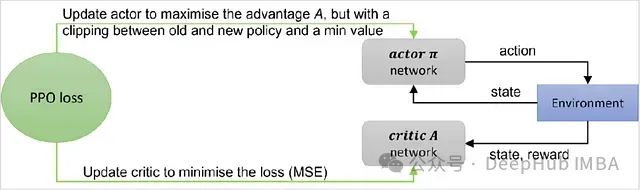
近端策略优化(Proximal Policy Optimization, PPO)算法作为一种高效的策略优化方法,在深度强化学习领域获得了广泛应用。特别是在大语言模型(LLM)的人类反馈强化学习(RLHF)过程中,PPO扮演着核心角色。本文将深入探讨PPO的基本原理和实现细节。
PPO属于在线策略梯度方法的范畴。其基础形式可以用带有优势函数的策略梯度表达式来描述:
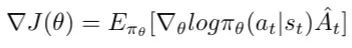
策略梯度的基础表达式(包含优势函数)。
这个表达式实际上构成了优势演员-评论家(Advantage Actor-Critic)方法的基础目标函数。PPO算法可以视为对该方法的一种改进和优化。
https://avoid.overfit.cn/post/ff4d892c414a4b9c9391a1812690eceb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号