EvalPlanner:基于“计划-执行”双阶段的大语言模型评估框架
大语言模型(LLM)评估系统在生成思维链(Chain-of-Thought, CoT)序列时,需要系统地捕捉评估过程中的推理步骤。但是由于缺乏人工标注的CoT训练数据,以及预定义评估提示在复杂任务中的局限性,构建高质量的LLM评估模型面临重大挑战。另外手动调整评估指令的方法在面对多样化和复杂任务时表现出明显的局限性。
为应对这些挑战,研究团队提出了EvalPlanner[1],这是一种创新的LLM评估算法。该算法采用计划-执行的双阶段范式,首先生成无约束的评估计划,随后执行该计划并做出最终判断。这种方法显著提升了评估过程的系统性和可靠性。
核心方法论
系统架构
EvalPlanner的架构包含三个核心组件,如下图所示:
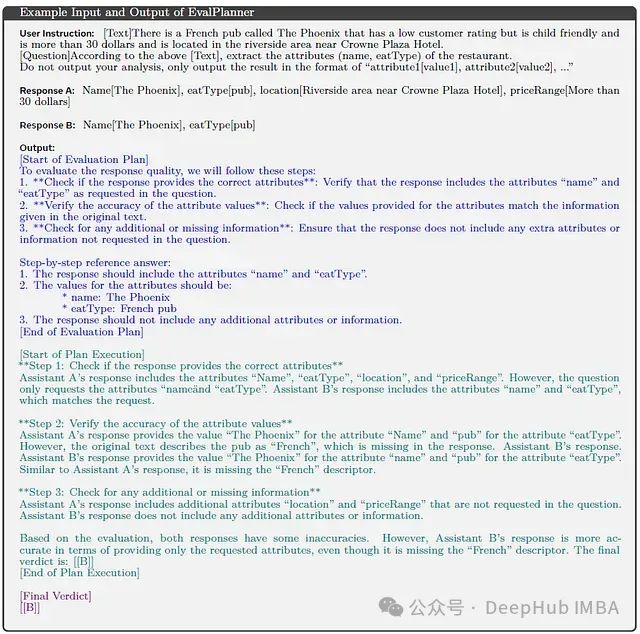
具体来说,系统包含以下关键要素:
https://avoid.overfit.cn/post/f7ce0fc3e984451b97da82075bfb0b27

 浙公网安备 33010602011771号
浙公网安备 33010602011771号