DeepSeek技术报告解析:为什么DeepSeek-R1 可以用低成本训练出高效的模型
DeepSeek-R1 通过创新的训练策略实现了显著的成本降低,同时保持了卓越的模型性能。本文将详细分析其核心训练方法。
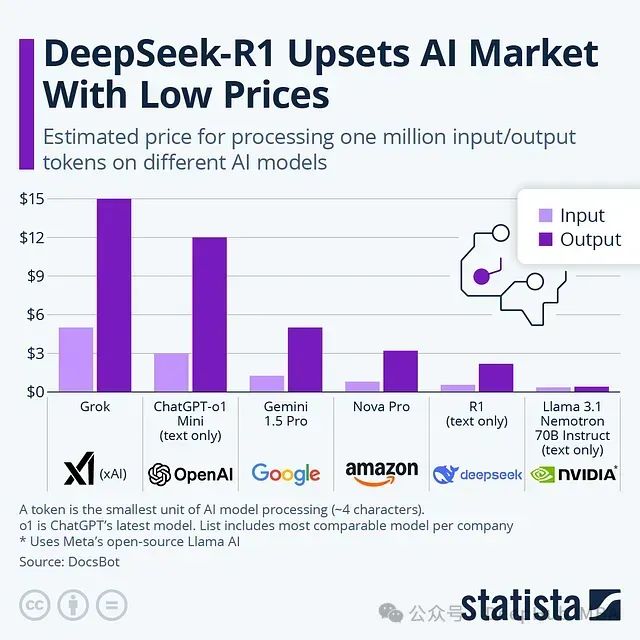
成本优势对比
在推理成本方面,DeepSeek-R1 展现出显著优势:
- 输入 tokens : $0.55/百万 tokens
- 输出 tokens : $2.19/百万 tokens
相比之下,O1 的推理成本:
- 输入 tokens : $15.00/百万 tokens
- 输出 tokens : $60.00/百万 tokens
https://avoid.overfit.cn/post/2f80a71952734612820d9986fadf2f1a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号