
https://avoid.overfit.cn/post/e57ca7e30ea74ad380b093a2599c9c01
DeepSeekMoE是一种创新的大规模语言模型架构,通过整合专家混合系统(Mixture of Experts, MoE)、改进的注意力机制和优化的归一化策略,在模型效率与计算能力之间实现了新的平衡。
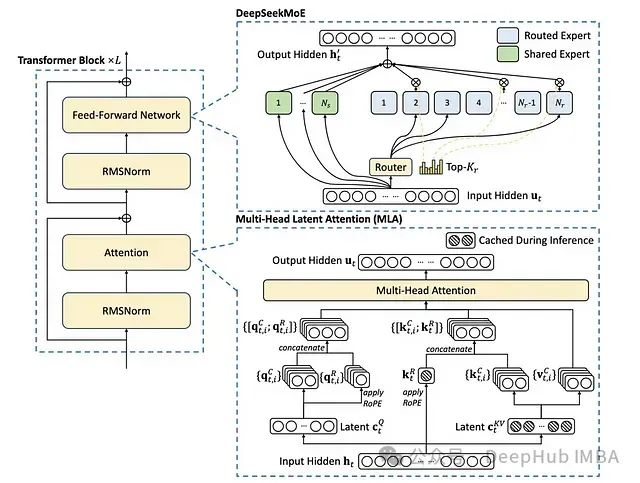
DeepSeekMoE架构融合了专家混合系统(MoE)、多头潜在注意力机制(Multi-Head Latent Attention, MLA)和RMSNorm三个核心组件。通过专家共享机制、动态路由算法和潜在变量缓存技术,该模型在保持性能水平的同时,实现了相较传统MoE模型40%的计算开销降低。
本文将从技术角度深入分析DeepSeekMoE的架构设计、理论基础和实验性能,探讨其在计算资源受限场景下的应用价值。
https://avoid.overfit.cn/post/e57ca7e30ea74ad380b093a2599c9c01

 浙公网安备 33010602011771号
浙公网安备 33010602011771号