
特征时序化建模:基于特征缓慢变化维度历史追踪的机器学习模型性能优化方法
我们在工作中经常会遇到一个问题,数据基础设施的设计往往没有充分考虑数据科学的需求。数据仓库或数据湖仓中的大量表格(主要是事实表和维度表)缺乏构建高性能机器学习模型所需的关键字段或结构。其中最显著的局限性在于,大多数表格仅记录观测值的当前状态,而未保留历史记录。
本文将通过缓慢变化维度(Slowly Changing Dimensions)这一数据建模技术来解决上面的这个问题。通过本文的介绍,可以了解历史数据存储对模型性能的重要影响,以及如何在实际应用中实施这一技术方案。
数据科学领域的常见挑战
在数据科学或机器学习工程领域工作一段时间后,可能会遇到这样一个建模问题:需要对数据中每个实例在时间维度上发生某事件的概率进行建模:
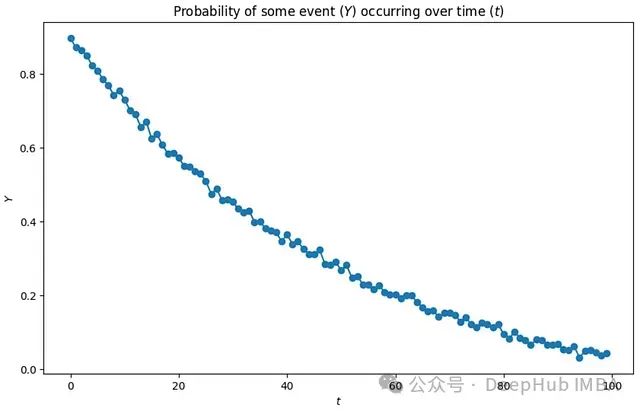
这种建模方法,通常称为面板建模(Panel Modeling),在实际应用中极为普遍。任何涉及特征随时间变化的建模问题都可以且通常应该采用这种方法。典型应用场景包括:客户流失预测、贷款违约预测、疾病进展监测、欺诈检测、设备故障预测等。
https://avoid.overfit.cn/post/ff7af723313a48c69b08eb313a016867

 浙公网安备 33010602011771号
浙公网安备 33010602011771号